流式计算可以广泛应用于金融银行、互联网、物联网等诸多领域,如股市实时分析、插入式广告投放、交通流量实时预警等场景,主要是为了满...
本文简述通过maven和gradle快速构建的Flink工程。建议安装好Flink以后构建自己的Flink项目,安装与示例运行请查看:Flink快速入门--安装...

Apache Kafka 是一个开源消息系统,由Scala 写成。是由Apache 软件基金会开发的一个开源消息系统项目。

实现批处理的技术许许多多,从各种关系型数据库的sql处理,到大数据领域的MapReduce,Hive,Spark等等。这些都是处理有限数据流的经典方...

Yahoo 的 Storm 团队曾发表了一篇博客文章 ,并在其中展示了 Storm、Flink 和 Spark Streaming 的性能测试结果。该测试对于业界而言极 ...

Kafka在0.10.0.0版本以前的定位是分布式,分区化的,带备份机制的日志提交服务。而kafka在这之前也没有提供数据处理的顾服务。大家的流...

流式计算分为无状态和有状态两种情况。无状态计算观察每个独立的事件,Storm就是无状态的计算框架,每一条消息来了以后和前后都没有关系...

Flink对于流处理架构的意义十分重要,Kafka让消息具有了持久化的能力,而处理数据,甚至穿越时间的能力都要靠Flink来完成。

我们知道过去对于Kafka的定义是分布式,分区化的,带备份机制的日志提交服务。也就是一个分布式的消息队列,这也是他最常见的用法。但是...

数据架构设计领域正在发生一场变革,其影响的不仅是实时处理业务,这场变革可能将基于流的处理视为整个架构设计的核心,而不是将流处...

Kafka是由LinkIn开源的实时数据处理框架,目前已经更新到2.3版本。不同于一般的消息中间件,Kafka通过数据持久化和磁盘读写获得了极高...

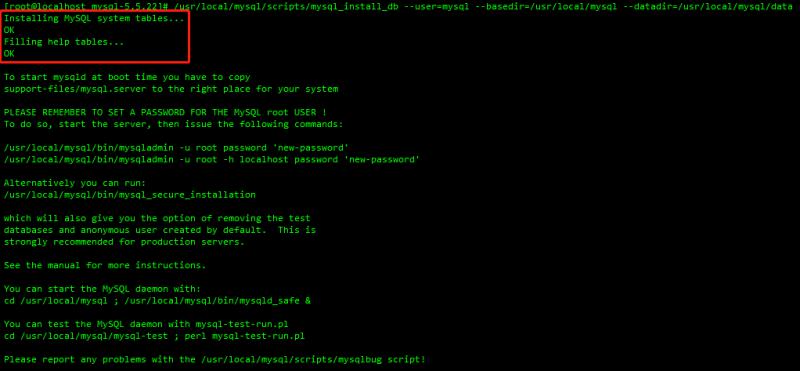
MySQL 数据库是一个关系型数据库管理系统,是服务器领域中受欢迎的开源数据库系统,目前有 Oracle 公司主要负责运营与维护;
对于大数据集群来说,监控功能是非常必要的,通过日志判断故障低效,我们需要完整的指标来帮我们管理Kafka集群。本文讨论Kafka的监控以...

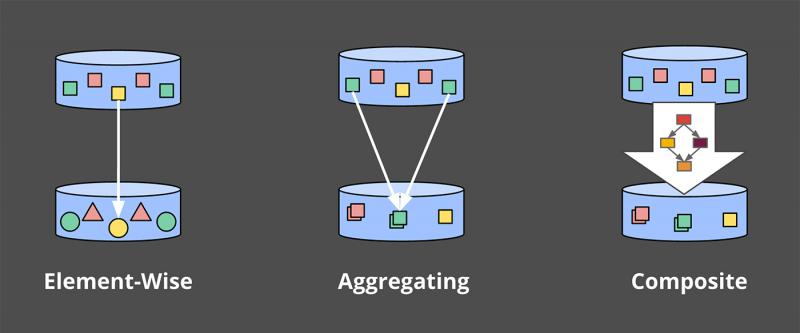
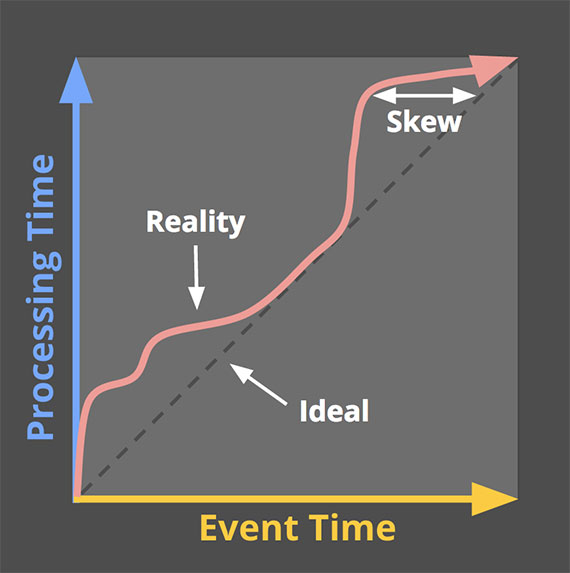
此文选自Google大神Tyler Akidau的另一篇文章:Streaming 102: The world beyond batch
本文主要给大家介绍SpringBoot中如何通过sl4j日志组件优雅地记录日志。其实,我们入门 JAVA 的第一行代码就是一行日志,那你现在还在使...
分享一篇关于实时流式计算的经典文章,这篇文章名为Streaming 101: The world beyond batch
kafka0.9版本以后用java重新编写了producer,废除了原来scala编写的版本。这里直接使用最新2.3版本,0.9以后的版本都适用。注意引用的包...

从学sklearn时,除了算法的坎要过,还得学习matplotlib可视化,对我的实践应用而言,可视化更重要一些,然而matplotlib的易用性和美观性...
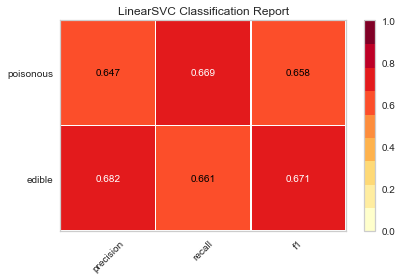
从学sklearn时,除了算法的坎要过,还得学习matplotlib可视化,对我的实践应用而言,可视化更重要一些,然而matplotlib的易用性和美观性...
Kafka旧版本producer由scala编写,0.9以后已经废除示例代码如下: {代码...} 自定义partition示例代码如下: {代码...} 更多实时计算,K...







