本文讲述如何安装,部署,启停HBase集群,如何通过命令行对Hbase进行基本操作。并介绍Hbase的配置文件。在安装前需要将所有先决条件安装...

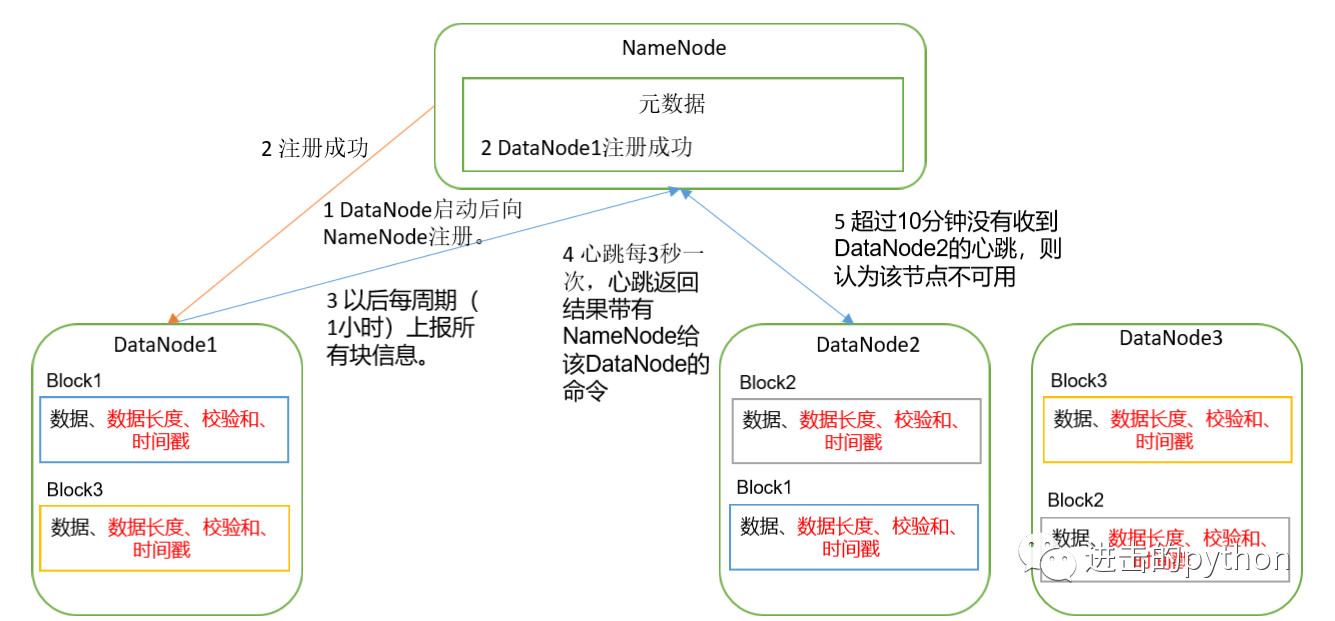
一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及...
场景描述:2019 云栖大会于昨日落幕。在这三天里,阿里围绕「数·智」主题,进行了多场技术分享和交流。和以往不同,作为马云卸任后的首...

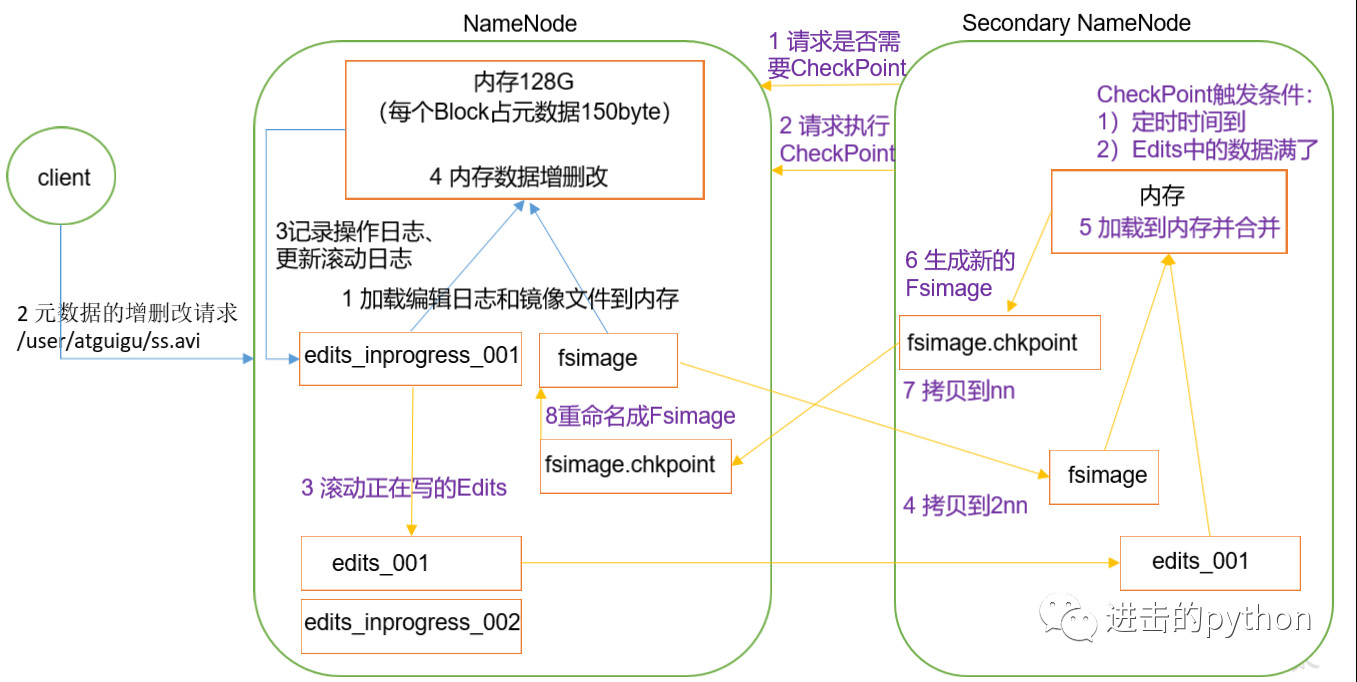
假设存储在NameNode节点的硬盘中,因为经常需要随机访问和响应客户请求,必然效率太低,所以是存储在内存中的
行转列原始数据:需求: {代码...} 实现: {代码...} 列转行原始数据:需求: {代码...} 实现: {代码...}

前言:今天接手了同事之前做的一个小项目,里面涉及到了 FastDFS 的使用。但是当我在本地运行项目的时候,却报了 Could not autowire No...

1、磁盘的格式化1.1、查看当前文件目录使用 df -h 命令来查看当前已经挂载的磁盘以及磁盘的信息: {代码...} 1.2、磁盘分区查找已经安装...
在正式开始前,千万不要把这一步与数据可视化或数据结果统计混淆——数据可视化或数据结果统计意味着结果。

集群环境:centOs6.8:hadoop102,hadoop103,hadoop104jdk版本:jdk1.8.0_144hadoop版本:Hadoop 2.7.2

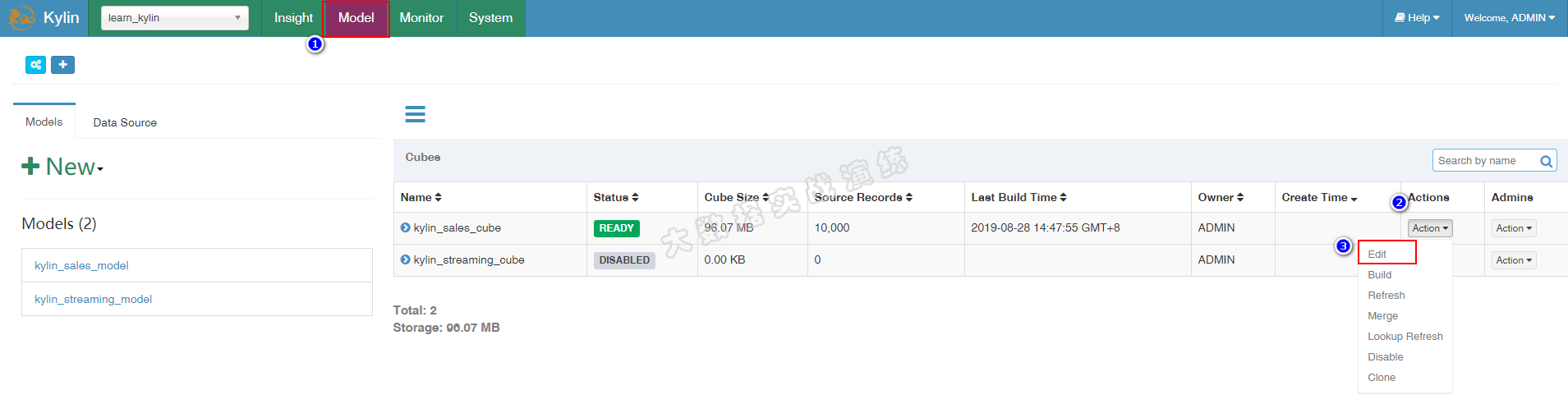
HDP版本:2.6.4.0Kylin版本:2.5.1机器:三台 CentOS-7,8G 内存Kylin 的计算引擎除了 MapReduce ,还有速度更快的 Spark ,本文就以 Ky...
本文将介绍大数据的知识和Hbase的基本概念,作为大数据体系中重要的一员,Hbase弥补了Hadoop只能离线批处理的不足,支持存储小文件,随...
我们知道,大数据的计算模式主要分为批量计算(batch computing)、流式计算(stream computing)、交互计算(interactive computing)、图计...
我们知道可以自己来开发Source 和 Sink ,但是一些比较基本的 Source 和 Sink 已经内置在 Flink 里。

本文基于java构建Flink1.9版本入门程序,需要Maven 3.0.4 和 Java 8 以上版本。需要安装Netcat进行简单调试。

原因分析:producer向不存在的topic发送消息,用户可以检查topic是否存在 或者设置auto.create.topics.enable参数

在学习了Zookeeper(后文都简称zk)的介绍和功能后,您已经很好地理解了zk。 现在,在这个zk教程中,我们将讨论zk的优点和局限性。 zk有...

在广告系统中倒排索引起着至关重要的作用,当请求过来时,需要根据定向信息从倒排索引中匹配合适的广告。我们的倒排索引采用的是Elastic...

Broker:Kafka的服务端即Kafka实例,Kafka集群由一个或多个Broker组成,主要负责接收和处理客户端的请求

上次我们通过分析KafkaProducer的源码了解了生产端的主要流程,今天学习下服务端的网络层主要做了什么,先看下 KafkaServer的整体架构图

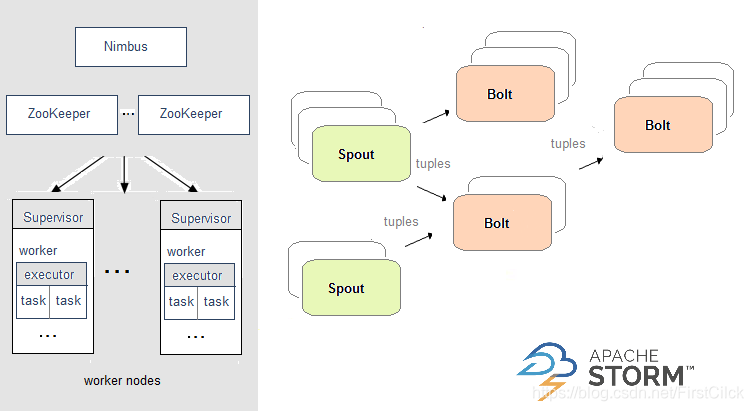
Apache Flink 和 Apache Storm 是当前业界广泛使用的两个分布式实时计算框架。其中 Apache Storm(以下简称“Storm”)在美团点评实时计算...











