elasticsearch 提供了几个内置的分词器:standard analyzer(标准分词器)、simple analyzer(简单分词器)、whitespace analyzer(空格分词...

PaddleNLP Pipelines 是一个端到端智能文本产线框架,面向 NLP 全场景为用户提供低门槛构建强大产品级系统的能力。本项目将通过一种简单...
因为 ElasticSearch 是用 Java 语言编写的,所以必须安装 JDK 的环境,并且是 JDK 1.8 以上,具体操作步骤自行百度
为了帮助大家及时了解中国数据库行业发展现状、梳理当前数据库市场环境和产品生态等情况,从2022年4月起,墨天轮社区行业分析研究团队出...

FBI 管理的 190 万恐怖分子观察名单副本在 2021 年 7 月 19 日至 8 月 9 日期间在网上曝光了三周,其中包括机密的 "禁飞"记录。

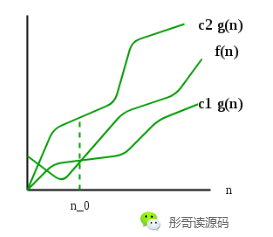
前面几节,我们一起学习了算法的复杂度如何分析,并从最坏、平均、最好以及不能使用最坏情况全方位无死角的剖析了算法的复杂度,在我们...
性能调优是系统架构里所有组件必不可少的话题,Elasticsearch也不例外,虽说Elasticsearch内的默认配置已经非常优秀,但这不表示它就是...

索引是我们使用Elasticsearch里最频繁的部分日常的操作都与索引有关,本篇从运维人员的视角,来玩一玩Elasticsearch的索引操作。
生产环境中运行的组件,只要有数据存储,定时备份、灾难恢复是必修课,mysql数据库的备份方案已经非常成熟,Elasticsearch也同样有成熟...

如果我们的Elasticsearch集群做了一些离线的维护操作时,如扩容磁盘,升级版本等,需要对集群进行启动,节点数较多时,从第一个节点开始...

我们从开始编程就接触过各种各样的组件,而每种功能的组件,对硬件要求的特性都不太相同,有的需要很强的CPU计算能力,有的对内存需求量...

前面历经33篇内容的讲解,与ES的请求操作都是在Kibana平台上用Restful请求完成的,一直没发布Java或python的客户端代码,Restful才是运...
搜索模板search tempalte高级功能之一,可以将我们的一些搜索进行模板化,使用现有模板时传入指定的参数就可以了,避免编写重复代码。对...
本篇以实际案例为背景,介绍不同技术组件对数据建模的特点,并以ES为背景,介绍常用的联合查询的利弊,最后介绍了一下文件系统分词器pat...
本篇主要介绍聚合查询的内部原理,正排索引是如何建立的和优化的,fielddata的使用,最后简单介绍了聚合分析时如何选用深度优先和广度优...

上一篇我们演练的聚合算法,在Elasticsearch分布式场景下,其实是有略微区别的,简单来说我们可以把这些聚合算法分成两类,易并行算法和...

Elasticsearch的聚合查询,跟数据库的聚合查询效果是一样的,我们可以将二者拿来对比学习,如求和、求平均值、求最大最小等等。
前面的案例使用standard、english分词器,是英文原生的分词器,对中文分词支持不太好。中文作为全球最优美、最复杂的语言,目前中文分词...
概要本篇介绍怎样在全文字段中搜索到最相关的文档,包含手动控制搜索的精准度,搜索条件权重控制。手动控制搜索的精准度搜索的两个重要...

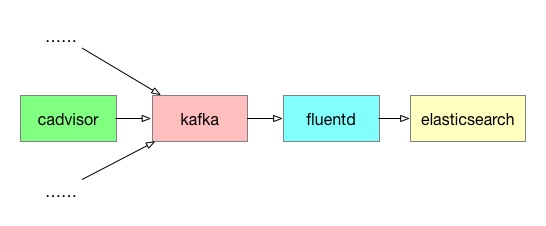
由于logstash内存占用较大,灵活性相对没那么好,ELK正在被EFK逐步替代.其中本文所讲的EFK是Elasticsearch+Fluentd+Kfka,实际上K应该是Kib...