在此为 RL 社区贡献一点绵薄之力,首先摘录 Stable Baselines3 的 RL Tips and Tricks,其次给出个人心得,最后提供一些其他优秀的资源。
近日,由网易伏羲研究团队和伏羲TTG技术团队联合发布的强化学习推荐系统工业数据集RL4RS,正式在Github开源社区开放下载。在之前的2021年年中,该工作曾与IEEE BigData 2021大会合办了网易伏羲第一届大数据竞赛,IEEE BigData Cup 2021: RL-based RecSys,吸引了国内外高校近百支队伍的参赛以及多达7篇的参赛中稿论文,...

强化学习的一个难题是与环境交互时的样本效率:好的探索策略可以减小样本复杂度;差的探索策略则可能导致即使交互了很多次,也无法求解到最优策略。具体而言,由于环境是未知的,智能体并不确定从环境得到的反馈是准确的,所以无法贪婪地优化策略来交互。直觉上,一个好的探索策略要不断尝试那些未知的/不确定的动作;但...
由北京大学前沿计算研究中心助理教授董豪博士等编写的深度强化学习专著《深度强化学习:基础、研究与应用(Deep ReinforcementLearning: Foundamentals, Research and Applications)》英文版于2020年6月由 Springer 发行,中文简体、繁体版先后于2021年6月、2022年1月发行,并于2022年2月对中文简体版开放免费下载。

OpenAI Gym是一款用于研发和比较强化学习算法的环境工具包,它支持训练智能体(agent)做任何事——从行走到玩Pong或围棋之类的游戏都在范围中。 它与其他的数值计算库兼容,如pytorch、tensorflow 或者theano 库等。现在主要支持的是python 语言

然而,作为一类机器学习算法,强化学习也面临着机器学习领域的公共难题,即难以被人理解。缺乏可解释性限制了强化学习在安全敏感领域中的应用,如医疗、驾驶等,并导致强化学习在环境仿真、任务泛化等问题中缺乏普遍适用的解决方案。
强化学习 (RL) 与深度学习的结合带来了一系列令人印象深刻的壮举,许多人认为(深度)强化学习提供了通向通用智能体的途径。然而,RL 智能体的成功通常对训练过程中的设计选择高度敏感,这可能需要繁琐且容易出错的手动调整。这使得将 RL 用于新问题变得具有挑战性,同时也限制了它的全部潜力。在机器学习的许多其他领域...

目前,机器学习系统可以解决计算机视觉、语音识别和自然语言处理等诸多领域的一系列挑战性问题,但设计出媲美人类推理的灵活性和通用性的学习赋能(learning-enable)系统仍是遥不可及的事情。这就引发了很多关于「现代机器学习可能缺失了哪些成分」的讨论,并就该领域必须解决哪些大问题提出了很多假设。

In 2022, in an effort to broaden the diversity of the pool of participants to ICLR 2022, we are starting a program specifically assisting underrepresented, underprivileged, independent, and particularly first-time ICLR submitters. We hope this program can help create a path for prospective ICLR a...

在强化学习研究中,一个实验就要跑数天或数周,有没有更快的方法?近日,来自 SalesForce 的研究者提出了一种名为 WarpDrive(曲率引擎)的开源框架,它可以在一个 V100 GPU 上并行运行、训练数千个强化学习环境和上千个智能体。实验结果表明,与 CPU+GPU 的 RL 实现相比,WarpDrive 靠一个 GPU 实现的 RL 要快几个数量级。

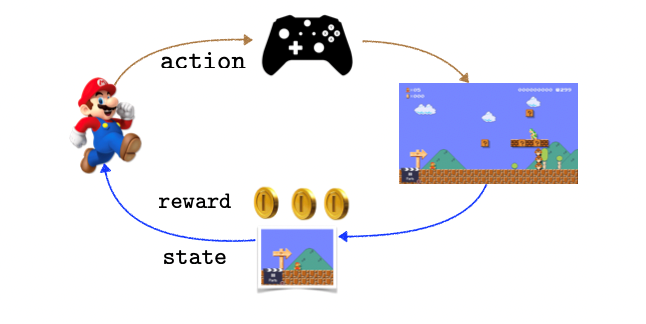
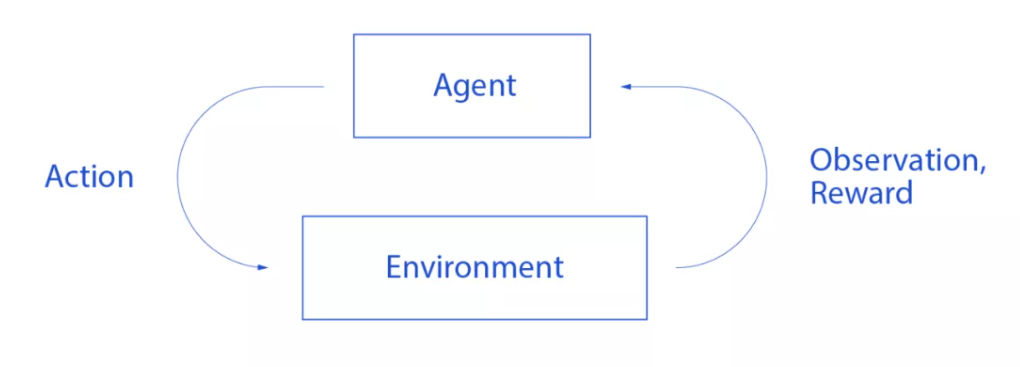
一句话概括强化学习(RL):Agent不停地与环境互动,通过反复尝试的方式进行学习,在一定的不确定性下做出决策,最终达到exploration (尝试新的可能) 与exploitation (利用旧的知识) 之间的平衡。
很多机器人强化学习任务都面临计算需求和仿真速度的瓶颈,而英伟达这个仿真环境可以将过去需要数千个 CPU 核参与训练的任务移植到单个 GPU 上完成训练。
Mava 是一个用于构建多智能体强化学习 (MARL) 系统的库。Mava 为 MARL 提供了有用的组件、抽象、实用程序和工具,并允许对多进程系统训练和执行进行简单的扩展,同时提供高度的灵活性和可组合性。

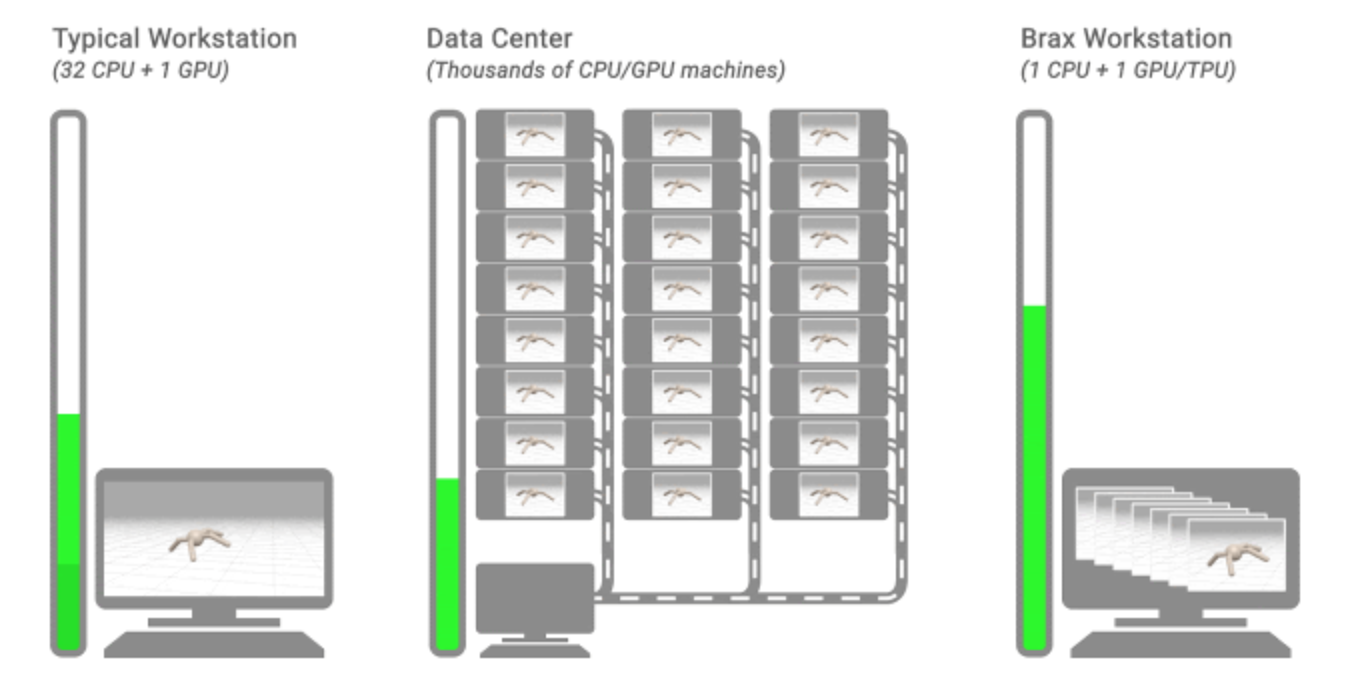
强化学习(RL) 是一种流行的教学机器人导航和操纵物理世界的方法,其本身可以简化并表示为_刚体_之间的交互1(即,当对它们施加力时不会变形的固体物理对象)。为了便于在实际时间内收集训练数据,RL 通常利用模拟,其中任意数量的复杂对象的近似值由许多由关节连接并由执行器提供动力的刚体组成。但这带来了一个挑战:RL...
人们普遍认为,将传统强化学习与深度神经网络相结合的深度强化学习研究的巨大增长始于开创性的DQN算法的发表。这篇论文展示了这种组合的潜力,表明它可以产生可以非常有效地玩许多 Atari 2600 游戏的智能体。从那时起,已经有几种 方法建立在原始 DQN 的基础上并对其进行了改进。流行的Rainbow 算法结合了这些最新进展,...
基于采样的学习机制,即在环境中交互试错,是强化学习和传统的监督学习的一大区别。监督学习中,我们的数据集与每一个数据的标签,都是事先收集好的。我们使用一个函数近似器来尽可能高概率地使得每一个数据点的标签都被函数近似器准确预测。
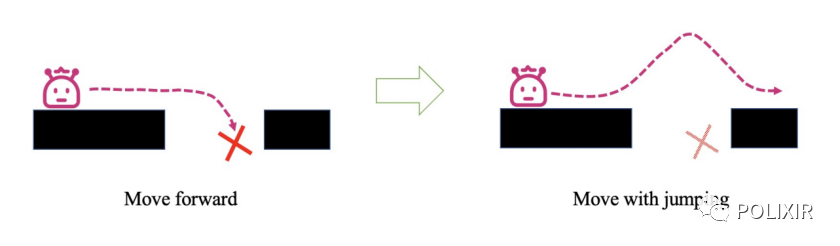
目前,深度强化学习(DRL)技术在游戏等领域已经取得了巨大的成功,同时在量化投资中的也取得了突破性进展,为了训练一个实用的DRL 交易agent,决定在哪里交易,以什么价格交易以及交易的数量,这是一个具有挑战性的问题,那么强化学习到底如何与量化交易进行结合呢?下图是一张强化学习在量化交易中的建模图:
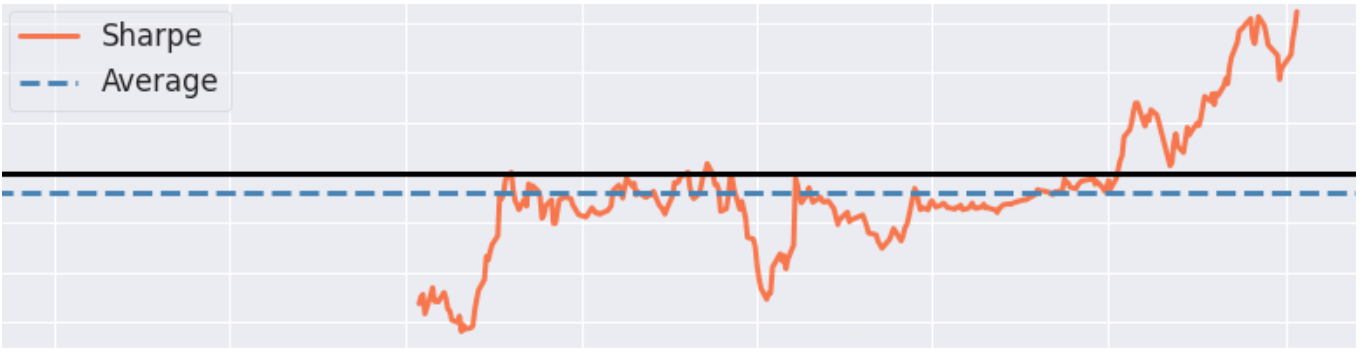
416: Robust Reinforcement Learning: A Case Study in Linear Quadratic Regulation

元学习作为一种增加强化学习的灵活性和样本效率的方法,科研学者对此的关注兴趣迅速增长。然而,该研究领域中的一个问题是缺乏足够的基准测试任务。通常,过去基准的基础结构要么太简单以至于无法引起兴趣,要么就太不明确了以至于无法进行有原则的分析。在当前的工作中,DeepMind科学家介绍了用于元RL研究的新基准:Alc...

报道:深度强化学习实验室作者: 高新根博士(DeepRL-Lab研究员)编辑: DeepRL本文章读者能简单理解如下几个问题:简单分析了这些方法偏差与方差的高低特点,比如为何说TD算法高偏差低方差。简单梳理了这些方法之间的关系1.值函数的估计方法1.1 时序差分算法(3) TD算法的特点——高偏差低方差1.2 蒙特卡罗算法2.优势函数的估...



