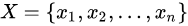sklearn.linear_model.LinearRegression调用 {代码...} Parametersfit_intercept释义:是否计算该模型的截距。设置:bool型,可选,默认True,如果使用中心化的数据,可以考虑设置为False,不考虑截距。normalize释义:是否对数据进行标准化处理设置:bool型,可选,默认False,建议将标准化的工作放在训练模型之前,通过设置sklearn...

sklearn.decomposition.PCA(n_components=None, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', random_state=None)参数n_components
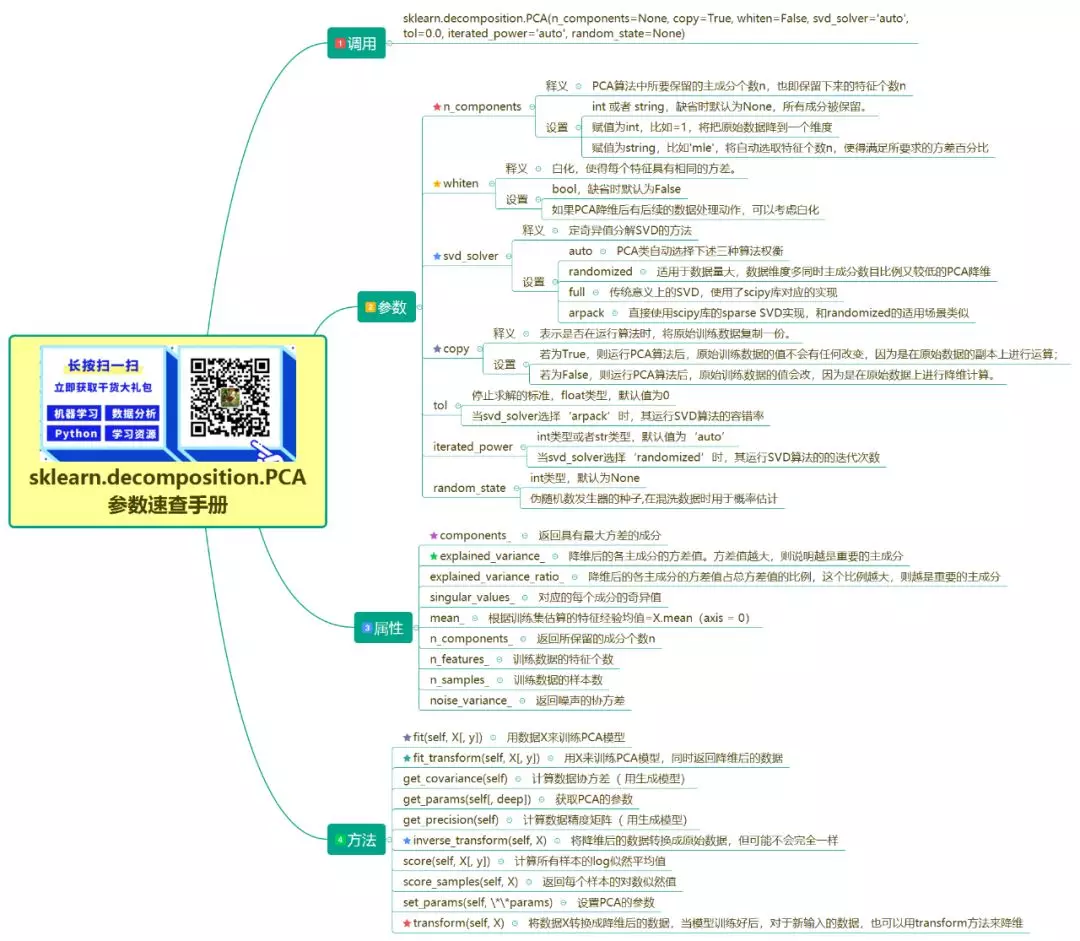
语法sklearn.linear_model.Ridge(alpha=1.0,fit_intercept=True, normalize=False,copy_X=True, max_iter=None, tol=0.001, solver='auto', random_state=None)Parametersalpha
在许多情况下,我们需要在迭代数据对性(即我们可以循环的任何对象)时获取元素的索引。实现预期结果的一种方法是:

跟着漂亮小姐姐从0到1学习Tensorflow推荐一个Tensorflow发布的系列视频——“Machine Learning: From Zero to Hero with TensorFlow”(机器学习: 从零到一学习Tensorflow),每个视频都很简短,有配套的案例代码,非常适合用一个下午的时间完整的熟悉机器学习、神经网络、机器视觉和TensorFlow的基本概念和操作。

推荐两个公开课,在中国大学Mooc上都被评为国家精品公开课,完全免费学习。授课老师是北京理工大学嵩天博士

先重温一下迭代(Iteration)、迭代器对象(iterable)、迭代器(iterator )的概念:
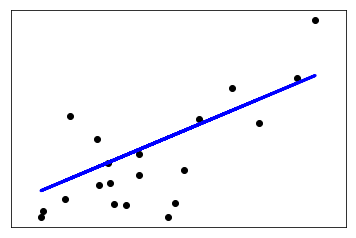
回归模型的性能的评价指标主要有:RMSE(平方根误差)、MAE(平均绝对误差)、MSE(平均平方误差)、R2_score。但是当量纲不同时,RMSE、MAE、MSE难以衡量模型效果好坏。这就需要用到R2_score,实际使用时,会遇到许多问题,今天我们深度研究一下。
随着现代图像处理和人工智能技术的快速发展,不少学者尝试讲CV应用到教学领域,能够代替老师去阅卷,将老师从繁杂劳累的阅卷中解放出来,从而进一步有效的推动教学质量上一个台阶。

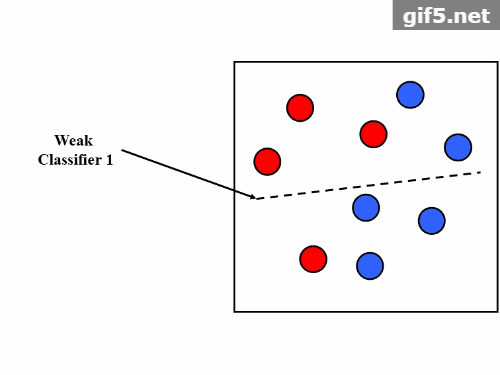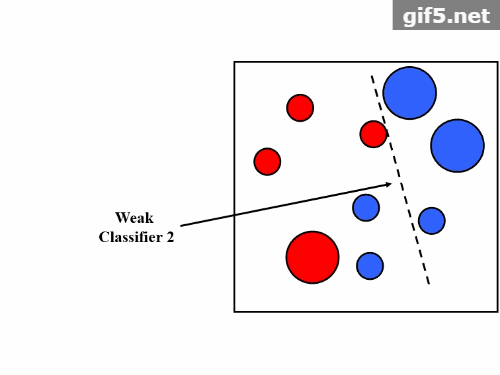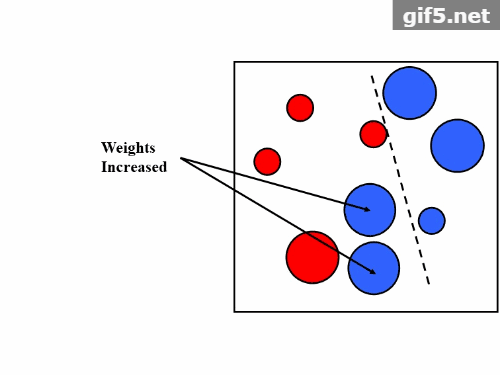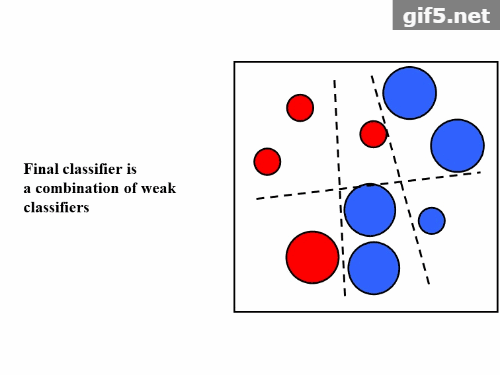
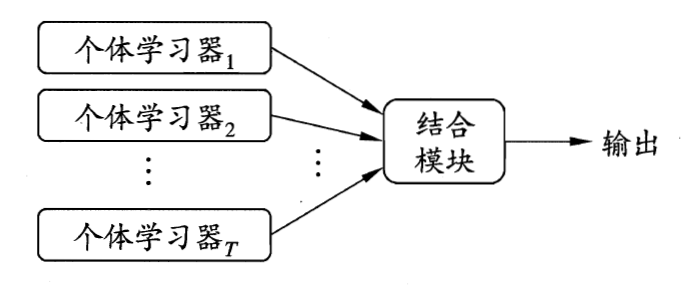
Boosting是一种用来提高弱分类器准确度的算法,是将“弱学习算法“提升为“强学习算法”的过程,主要思想是“三个臭皮匠顶个诸葛亮”。一般来说,找到弱学习算法要相对容易一些,然后通过反复学习得到一系列弱分类器,组合这些弱分类器得到一个强分类器。
本文涉及pandas最常用的36个函数,通过这些函数介绍如何完成数据生成和导入、数据清洗、预处理,以及最常见的数据分类,数据筛选,分类汇总,透视等最常见的操作。
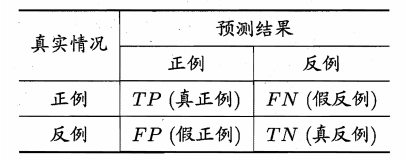
对模型进行评估时,可以选择很多种指标,但不同的指标可能得到不同的结果,如何选择合适的指标,需要取决于任务需求。
在参与的项目和产品中,涉及到模型和算法的需求,主要以自然语言处理(NLP)和知识图谱(KG)为主。NLP涉及面太广,而聚焦在具体场景下,想要生产落地的还需要花很多功夫。作为NLP的主要方向,情感分析,文本多分类,实体识别等已经在项目中得到应用。例如通过实体识别,抽取文本中提及到的公司、个人以及金融产品等。通...

前文对随机森林的概念、工作原理、使用方法做了简单介绍,并提供了分类和回归的实例。本期我们重点讲一下:1、集成学习、Bagging和随机森林概念及相互关系2、随机森林参数解释及设置建议3、随机森林模型调参实战4、随机森林模型优缺点总结
熵最早是一个物理学概念,由克劳修斯于1854年提出,它是描述事物无序性的参数,跟热力学第二定律的宏观方向性有关:在不加外力的情况下,总是往混乱状态改变。熵增是宇宙的基本定律,自然的有序状态会自发的逐步变为混沌状态。1948年,香农将熵的概念引申到信道通信的过程中,从而开创了”信息论“这门学科。香农用“信息熵...
目前计算机视觉(CV)与自然语言处理(NLP)及语音识别并列为人工智能三大热点方向,而计算机视觉中的对象检测(objectdetection)应用非常广泛,比如自动驾驶、视频监控、工业质检、医疗诊断等场景。目标检测的根本任务就是将图片或者视频中感兴趣的目标提取出来,目标的识别可以基于颜色、纹理、形状。其中颜色属性运用...

前段时间在阿里云买了一台服务器,准备部署网站,近期想玩一些深度学习项目,正好拿来用。TensorFlow官网的安装仅提及Ubuntu,但我的ECS操作系统是 CentOS 7.6 64位,搭建Python、TensorFlow、Jupyter开发环境过程中遇到很多问题。这里将具体步骤分享给大家,可以少走很多弯路。
几张GIF理解K-均值聚类原理k均值聚类数学推导与python实现前文说了k均值聚类,他是基于中心的聚类方法,通过迭代将样本分到k个类中,使每个样本与其所属类的中心或均值最近。

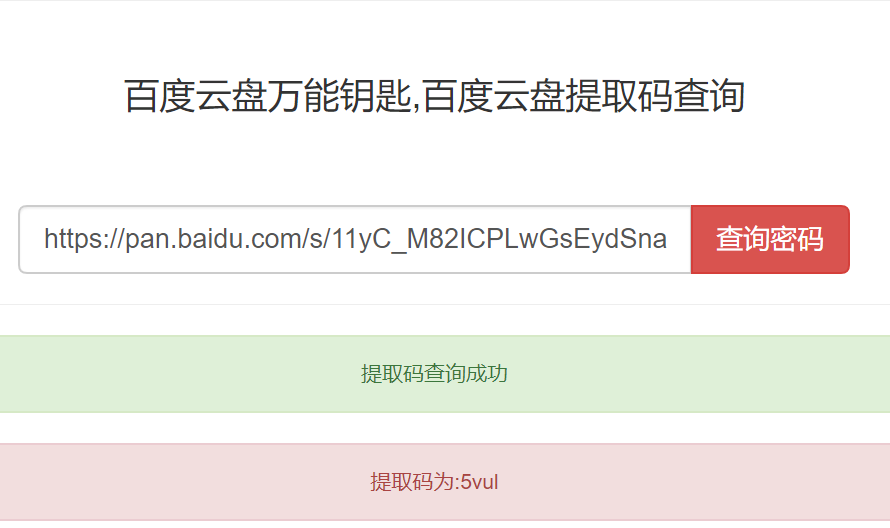
同学们知道,我们在百度网盘分享文件的时候,一般都会设置一个提取码,以保障传播范围及私密性,只有输入提取码才能下载分享的资料。很多同学在云盘搜等网站找百度网盘学习资料时,经常会遇到只有云链接,但是没有提取码的尴尬。这里向大家推荐一款神器——百度云盘万能钥匙有着这把钥匙,就可以畅行无阻了。
1、k均值聚类模型给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类。用C表示划分,他是一个多对一的函数,k均值聚类就是一个从样本到类的函数。2、k均值聚类策略k均值聚类的策略是通过损失函数最小化选取最优的划分或函数。...