
enumerate() 的作用
在许多情况下,我们需要在迭代数据对性(即我们可以循环的任何对象)时获取元素的索引。实现预期结果的一种方法是:
animals = ['dog', 'cat', 'mouse']
for i in range(len(animals)):
print(i, animals[i])输出:
0 dog
1 cat
2 mouse大多数C ++ / Java背景的开发人员都可能会选择上述实现,通过索引迭代数据对象的长度是他们熟悉的概念。但是,这种方法效率很低。
我们可以使用enumerate()来实现:
for i, j in enumerate(example):
print(i, j)enumerate()提供了强大的功能,例如,当您需要获取索引列表时,它会派上用场:
(0, seq[0]), (1, seq[1]), (2, seq[2]), ...案例研究1:枚举字符串

字符串只是一个列表
为了更好地理解字符串枚举,我们可以将给定的字符串想象为单个字符(项)的集合。因此,枚举字符串将为我们提供:
1.字符的索引。
2.字符的值。
word = "Speed"
for index, char in enumerate(word):
print(f"The index is '{index}' and the character value is '{char}'")输出:
The index is '0' and the character value is 'S'
The index is '1' and the character value is 'p'
The index is '2' and the character value is 'e'
The index is '3' and the character value is 'e'
The index is '4' and the character value is 'd'案例研究2:列举列表
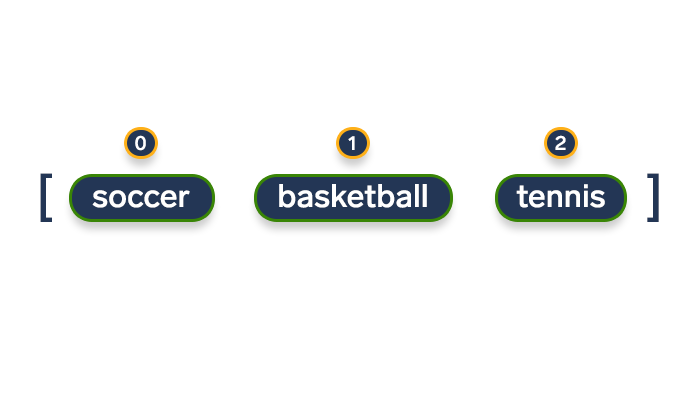
那么,我们应该如何列举一个列表呢?为了做到这一点,我们可以利用for循环并遍历每个项目的索引和值:
sports = ['soccer', 'basketball', 't` ennis']
for index, value in enumerate(sports):
print(f"The item's index is {index} and its value is '{value}'")输出:
The item's index is 0 and its value is 'soccer'
The item's index is 1 and its value is 'basketball'
The item's index is 2 and its value is 'tennis'案例研究3:自定义起始索引
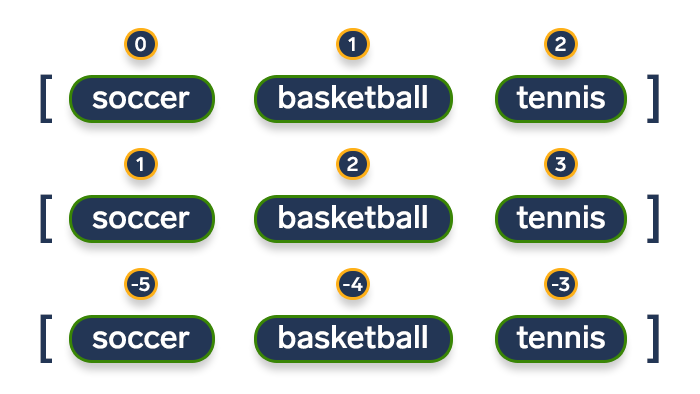
我们可以看到枚举从索引0开始,但是们经常需要更改起始位置,以实现更多的可定制性。值得庆幸的是,enumerate()还带有一个可选参数[start]
enumerate(iterable, start=0)可以用来指示索引的起始位置,方法如下:
students = ['John', 'Jane', 'J-Bot 137']
for index, item in enumerate(students, start=1):
print(f"The index is {index} and the list element is '{item}'")输出
The index is 1 and the list element is 'John'
The index is 2 and the list element is 'Jane'
The index is 3 and the list element is 'J-Bot 137'现在,修改上述代码:1.起始索引可以为负;2.省略start=则默认从0索引位置开始。
teachers = ['Mary', 'Mark', 'Merlin']
for index, item in enumerate(teachers, -5):
print(f"The index is {index} and the list element is '{item}'")输出将是:
The index is -5 and the list element is 'Mary'
The index is -4 and the list element is 'Mark'
The index is -3 and the list element is 'Merlin'案例研究4:枚举元组
使用枚举元组遵循与枚举列表相同的逻辑:
colors = ('red', 'green', 'blue')
for index, value in enumerate(colors):
print(f"The item's index is {index} and its value is '{value}'")输出:
The item's index is 0 and its value is 'red'
The item's index is 1 and its value is 'green'
The item's index is 2 and its value is 'blue'案例研究5:枚举列表中的元组

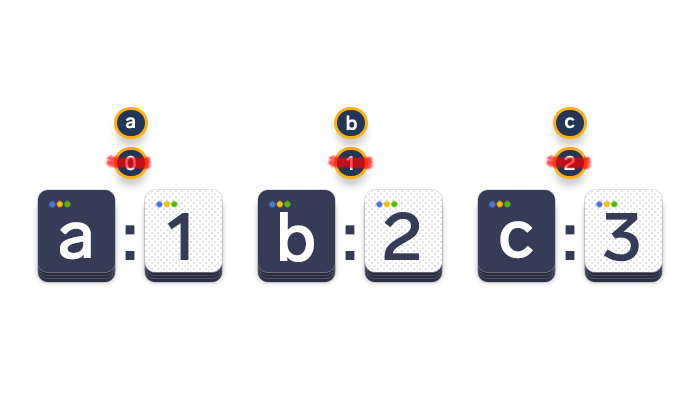
让我们提高一个档次,将多个元组合并到一个列表中……我们要枚举此元组列表。一种做法的代码如下:
letters = [('a', 'A'), ('b', 'B'), ('c', 'C')]
for index, value in enumerate(letters):
lowercase = value[0]
uppercase = value[1]
print(f"Index '{index}' refers to the letters '{lowercase}' and '{uppercase}'")但是,元组拆包被证明是一种更有效的方法。比如:
letters = [('a', 'A'), ('b', 'B'), ('c', 'C')]
for i, (lowercase, uppercase) in enumerate(letters):
print(f"Index '{i}' refers to the letters '{lowercase}' and '{uppercase}'")输出:
Index '0' refers to the letters 'a' and 'A'
Index '1' refers to the letters 'b' and 'B'
Index '2' refers to the letters 'c' and 'C'案例研究6:枚举字典
枚举字典似乎类似于枚举字符串或列表,但事实并非如此,主要区别在于它们的顺序结构,即特定数据结构中元素的排序方式。
字典有些随意,因为它们的项的顺序是不可预测的。如果我们创建字典并打印它,我们将得到一种结果:
translation = {'one': 'uno', 'two': 'dos', 'three': 'tres'}
print(translation)
# Output on our computer: {'one': 'uno', 'two': 'dos', 'three': 'tres'}但是,如果打印此词典,则顺序可能会有所不同!
由于索引无法访问字典项,因此我们必须利用for循环来迭代字典的键和值。该key — value对称为item,因此我们可以使用.items()方法:
animals = {'cat': 3, 'dog': 6, 'bird': 9}
for key, value in animals.items():
print(key, value)输出将是:
cat 3
dog 6
bird 9
本文由博客一文多发平台 OpenWrite 发布!

