
本文是关于稀疏卷积的一点感触,作者进行整理与分析,也许会对某些童鞋产生一丢丢灵感,这也是整理本文的一点期待。
首发知乎:https://zhuanlan.zhihu.com/p/76829900
文章作者: Happy
在进行更深入介绍之前,先简单说明一下稀疏卷积的定义。我个人是这样定义稀疏卷积的:
如果某个卷积的任意输入神经元与任意输出神经元均存在连接,那么这类卷积称之为常规卷积(非稀疏卷积);反之,如果存在输入神经元与输入神经炎之间无连接,那么这类卷积称之为稀疏卷积。比如组卷积就是稀疏卷积的一种。
此外,进一步对卷积进行抽象为下图表示方式,即将卷积的参数进行更进一步的抽象。

如上图所示,最右侧表示输入神经元,最左侧表示输出神经元,中间矩阵表示输入与输出之间的连接关系。连接关系中的每个小方块表示输入与输出之间是否存在连接,简单定义如下:

在这里,我们提供这样一个比较简单的评价卷积是否为稀疏卷积的规则。对于卷积而言,其权值参数为
定义滤波器绝对值和为


即如果输入神经元与输出神经元之间存在连接,那么就非0。下面将结合一些网络架构说明一下稀疏卷积在模型设计中的应用。
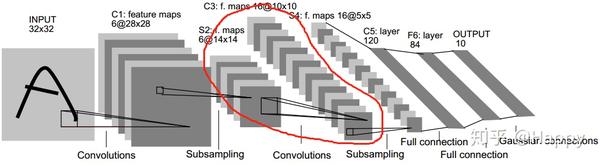
LeNet
也许,最早将稀疏卷积应用到卷积神经网络中的当属LeCun老爷子很早之前提出的LeNet5 1了。该网络架构如下所示。它的稀疏卷积主要体现在S2与C3之间,对于为什么进行这样的稀疏配置,原文是这样解释的:
The reason is twofold. First, a noncomplete connection scheme keeps the number of connections within reasonable bounds. More importantly, it forces a break of symmetry in the network. Different feature maps are forced to extract different features (hopefully complementary) because they get different sets of input.
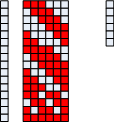
关于S2与C3的配置如下图所示(按照原文重新绘制),每一行表示S2的每一个通道,每一列表示C3的每一个通道,X表示存在连接关系。
需要注意的是:目前很多深度学习框架(如Tensorflow, Pytorch, Caffe, MxNet等)中提供的LeNet网络均为非稀疏卷积,暂未发现哪个框架有提供稀疏连接形式LeNet(如有请告知)。
均匀分组稀疏卷积
自LeNet之后,另一个用到稀疏卷积的是AlexNet2。AlexNet采用稀疏卷积则是优于硬件约束问题导致,当时作者采用的GTX580(仅3G显存)进行网络训练,单个GPU限制了网络的大小,因而作者采用两个GPU进行训练,仅在特定层进行GPU之间的通讯。比如第三层的kernels接收第二层的所有特征,而第四层则只接收第三层的一部分。
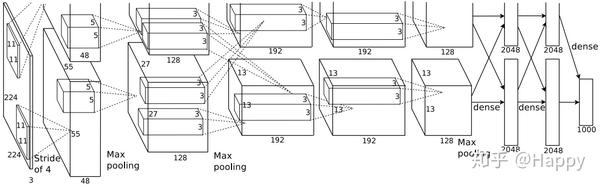
在AlexNet一文中,它将这种稀疏卷积称之为组卷积。它是一种均匀分组的稀疏卷积模式,这种均匀分组的稀疏卷积模式可以用下图来说明。即将输入神经元分为G组,输出神经元分为G组,第i组输入神经元与第j组神经元之间为非稀疏卷积模式。
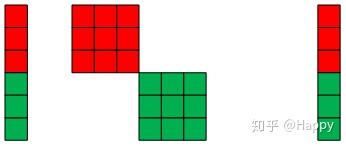
组卷积最极端的情况是每组只包含一个输入与一个输出神经元,这就是MobileNet3中的深度分离卷积的由来,MobileNet是目前很经典的架构之一,关于它的内容介绍烦请查阅原文,这里不再赘述。深度分离卷积可以用下图进行描述。

非均匀分组稀疏卷积
既然均匀分组的稀疏卷积称之为组卷积,那么是不是可以进行非均匀分组呢?当然可以,SeesawNet4就是一种非均匀分组的稀疏卷积模式。比如,我们可以采用下图来描述非均匀分组稀疏卷积。
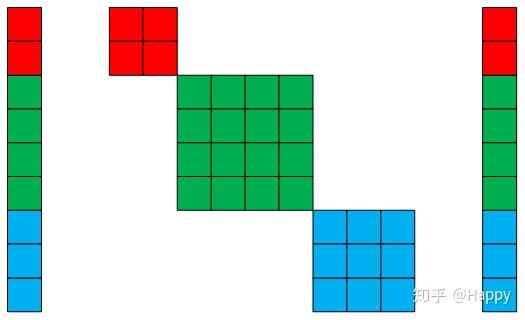
如上图所示,输入与输出的分组是非均匀的,但类似的,第i组输入与输出之间认为非稀疏卷积模式。当然,输入与输出之间的划分方式可以不同,比如第i组输入神经元数为2,输出神经元数为3。但同组输入与输出之间必然为非稀疏卷积模式。
基于该规则,是不是可以手工设计出大量的非均匀分组稀疏卷积呢?但是哪一种是最有的呢?论文作者采用NAS方式进行分均匀分组稀疏卷积模块设计。对此感兴趣者可以参考论文原文。本文旨在分析介绍稀疏卷积在模型设计的应用探索,故关于原文详细内容略过不计。
乱序稀疏卷积
前面所提到的几种稀疏卷积,在分组后的连接顺序上都是相同的。那么是否可以顺序不同呢?当然可以,ShuffleNet5与IGCV678系列即为这种乱序稀疏卷积(乱序可能不太正确,理解本质即可)。
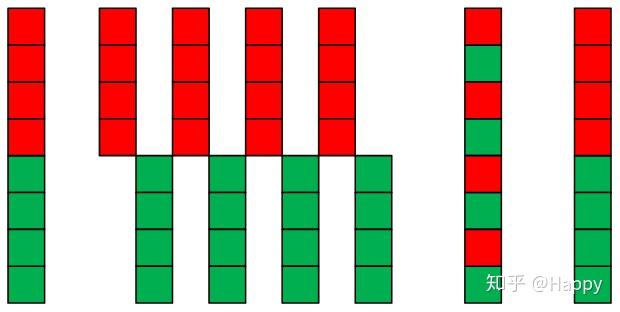
下面首先给出IGCV的可视化稀疏卷积图,从中可以看出:第2组输入神经元与第3组输出神经元之间相连接;而第三组输入神经元则与第2组输出神经炎之间连接。

顺序地,我们继续给出ShuffleNet的可视化稀疏卷积图。结合ShuffleNet的思想,下图很容易即可理解,故而不再赘述。
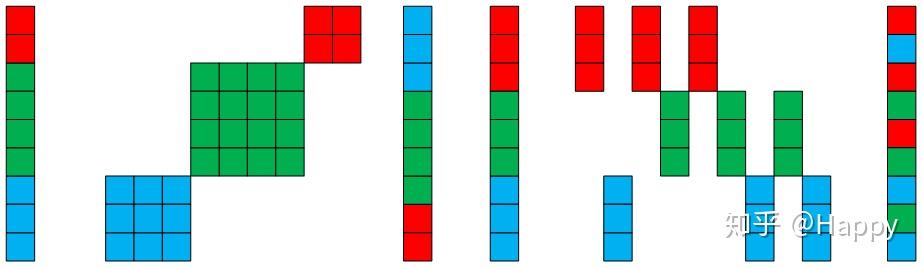
当然,乱序稀疏卷积不仅仅局限于上面两种形式,通过设计与输入神经元与输出神经元的组序关系,我们可以轻易的设计出各式各样的乱序稀疏卷积,比如以下两种形式:
可变卷积核尺寸稀疏组卷积
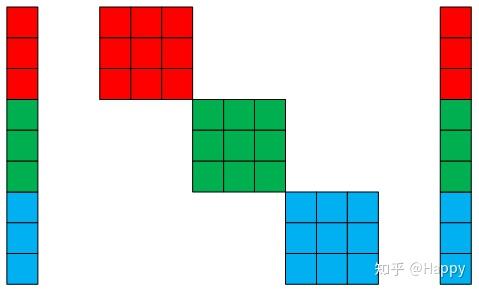
前面稀疏卷积中有一个潜在的卷积,即所有组的卷积核尺寸是相同的,比如。那么,是否可以将不同组之间的卷积核设置成不同尺寸的卷积核呢?当然可以,比如MixNet网络架构即可视为这种可变卷积核稀疏组卷积,以下图为例,假设红色块之间卷积核尺寸为,绿色快之间的卷积核尺寸为,蓝色块之间的卷积核尺寸为。因而,MixNet也可以是为稀疏卷积的一个特例。类似的,Squeezenet9、Inception10均可视为稀疏卷积的一个特例,感兴趣的童鞋可以去多多挖掘更多的网络架构,欢迎补充。
自学习稀疏卷积
前面提供的稀疏卷积网络基本都是手工设计的稀疏,那么是否可以通过其他方式达到这种稀疏目的呢?当然可以,FLGC11与CondenseNet12分别提出一种稀疏卷积构建方式。
首先,给出FLGA中的稀疏卷积构建方式。在训练过程中,通过指定分组数,自适应学习分组方式。而在测试过程中,则添加一个通道重组操作促使后接组卷积以适应现有深度学习框架。关于如何自适应构建稀疏卷积原理,感兴趣者可以参考原文。

其次,给出CondenseNet构建稀疏卷积的方案流程。CondenseNet采用多阶段方式构建稀疏卷积,是一种渐进式方式。类似的,在测试阶段,它同样添加一个冲到重组操作。感兴趣者可以参考原文。

最后,构建稀疏卷积的方案远不止上述两种。比如,可以参考文献13与ScaleNet14中的方案进行稀疏卷积的构建。下图给出了文献[13]中构建的稀疏卷积。事实上,还采用采用低秩分解15的方式进行稀疏卷积的构建。感兴趣者可以查阅原文。
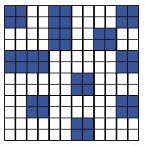
稀疏卷积在模型剪枝中的应用
事实上,很多童鞋可能已经想到了模型剪枝中的滤波器剪枝、通道剪枝不就是稀疏卷积吗?是的,当然是的。比如文献16-19所列的几篇经典模型剪枝文献都可用于稀疏卷积的构建。只不是滤波器剪枝可以很自然的视为稀疏卷积;反而通道剪枝由于后处理步骤看上去不像稀疏卷积。我相信,对上述内容理解透彻的童鞋可以很轻松的理解为什么说通道剪枝也是稀疏卷积的一种。
基于滤波器剪枝的稀疏卷积构建方式可参考文献19中所列出的多种方法;基于通道剪枝的稀疏卷积构建方式可参考文献16-18中的剪枝方法。
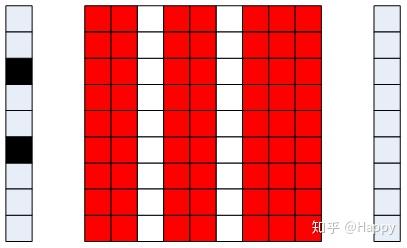
最后补上通道剪枝为啥是稀疏卷积的示意图(注:连接关系矩阵中,红色表示存在连接,白色表示无连接,输出神经元中黑色表示被剪枝通道),烦请自行理解。
小结
关于稀疏卷积的简要总结到此就算结束了,也算是对曾经轻量型网络设计、模型剪枝领域研究的简单总结。经过前面内容的简单分析介绍,可以很轻易的想出各式各样的改进型工作。比如将稀疏卷积构建与NAS组合搜索更轻量型的架构;比如已有的将模型剪枝与NAS相结合的工作AMC16等。
基本上关于稀疏卷积的点滴思考已经汇总了,事实上还有很多更细致的无法用文字描述的方案。不过,我想列出以上种种分析与探讨已经足以启发模型剪枝与轻量型网络的设计了。以上内容都比较简单,没有进行过于深入,但图示应该已经比较清晰了,如有疑问可以沟通交流。
内容到此结束,后续如有其他关于稀疏卷积的想法会持续补充,各位童鞋如果有其他认知也可反馈沟通学习。
参考文献
1 Gradient based Learning Applied to Document Recognition.↩
2 ImageNet Classification with Deep Convolutional Neural Networks.↩
3 MobileNets Efficient Convolutional Neural Networks for Mobile Vision Applications.↩
4 SeesawNet Convolution Neural Network with Uneven Group Convolution.↩
5 ShuffleNet An Extremely Efficient Convolutional Neural Network for MobileNet Devices.↩
6 Interleaved Group Convolutions for Deep Neural Networks.↩
7 Interleaved Structured Sparse Convolutional Neural Networks.↩
8 IGCV3 Interleaved Low Rank Group Convolution for Efficient Deep Neural Networks.↩
9 SqueezeNet Alexnet-Level Accuracy with 50x Fewer Parameters and < 0.5MB Model Size.↩
10 Going Deeper with Convolutions.↩
11 Fully Learnable Group Convolution for Acceleration of Deep Neural Networks.↩
12 CondenseNet An Efficient DenseNet using Learned Group Convolutions.↩
13 Balanaced Sparsity for Efficient DNN Inference on GPU↩
14 Data Driven Neuron Allocation for Scale Aggregation Networks.↩
15 Speeding up Convolutional Neural Networks with Low Rank Expansions.↩
16 AMC AutoML for Model Compression and Acceleration on Mobile Devices。↩
推荐阅读:
本文章著作权归作者所有,任何形式的转载都请注明出处。更多动态滤波,图像质量,超分辨相关请关注我的专栏深度学习从入门到精通。

