
首发:https://zhuanlan.zhihu.com/p/85153394
作者:张新栋
目前主流的CNN训练框架,如pytorch、mxnet、tensorflow2.0中都已经集成了autograd的机制,自动求导的机制相较于传统训练框架如caffe、tensorflow 1.x等粒度要精细。caffe、tensorflow 1.x一般以单层Op作为BP的节点,pytorch、mxnet、tensorflow 2.0中集成了autograd的机制,以单个math op作为bp节点。
本文通过算例跟大家讨论一下卷积Op在CNN训练过程中的一些求导细节,采用的记号和形式主要参考caffe、tensorlfow 1.x的设计模式,粒度为单个layers(如Conv2D layers)。卷积的数学符号的计算图,一般可以用如下图表示:

上图中,我们一般称x为features,k为conv kernel,b为bias。卷积的inference path可以参考上图中的红线方向箭头,其back-propagation path可以参考上图中的蓝色方向箭头。通过观察不难反向,在卷积Op中如果想实现反向传播,我们需要考虑三个数据项的求导过程,即y关于x的偏导、y关于b的偏导、y关于k的偏导。我们先来看一个简单的算例:
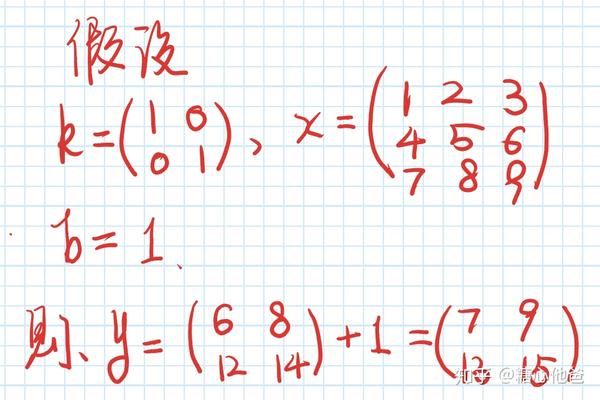
卷积算例
为了方便进行求导的表示,我们需要将上述卷积过程线性化,即转化成矩阵相乘的表达形式。如果能转化成矩阵相乘的表达形式,首先从数据重用角度上可以增加计算过程的locality,从数学表达上也可以方便我们进行符号表示。下面我们先看看关于数据项x的数据重排,
- 关于x的偏导
在进行y关于x的偏导计算时,我们需要先将k进行数据重排。下图是k的数据重排(大家注意x左边的矩阵上面还有一个转置符号),我们将conv2d的slide-windows采样模式转化成了矩形相乘的表达形式。通过观察我们可以发现,slide-windows的采样形式在数学表达上面,跟采用一个sparse matrix来对数据项进行作用是等价的。我们也可以这么理解,conv2d的空间结构信息是通过稀疏采样进行实现的。

关于k的数据重排
知道可以对conv2d进行数据重排之后,很容易的可以得出y关于x的偏导为下图中的稀疏矩阵A。

y关于x的偏导
- 关于k的偏导
同样的,在计算y关于k的偏导前,我们需要将数据项x进行数据重排,转化成矩阵相乘的表达形式。如下图:
关于x的数据重排
进行数据重排后,我们也很容易的可以得出y关于k的偏导,请看下图:

y关于k的偏导
其中X为对x进行数据重排后的矩阵,该矩阵的构造形式可参考slide-windows的采样过程。
- 关于b的偏导
y关于b的偏导计算比较简单直接,因为其计算过程为elementwise作用在k*x的结果中,所以其偏导为一个全1向量,对应上面的卷积例子,其偏导为:

y关于b的偏导
- 最后
本文跟大家讨论了卷积Op的求导(BP)过程,采用的符号和表达形式接近caffe、tensorflow 1.x,表达粒度为layer-wise的形式。后续将会跟大家继续讨论其他Op的求导(BP)过程,autograd的构图和计算模式的文章后续也会跟进。欢迎大家留言、关注专栏,谢谢大家!
推荐阅读
专注嵌入式端的AI算法实现,欢迎关注作者微信公众号和知乎嵌入式AI算法实现专栏。
更多嵌入式AI相关的技术文章请关注极术嵌入式AI专栏


