
k-means算法中文名叫做k均值。它是一种聚类算法,这是什么意思呢?就是现在我有一堆数据,但是我知道这些数据有k个类。但是具体每一个数据点所属分类我就不知道了。此时就需要用k-means聚类算法,它可以把原先的数据分成k个部分,注意这k个部分包含的数据点的数量不一定相等的。相似的数据就聚在一起。
作者:司南牧
k-means算法操作步骤
1. 设定k的取值(你觉得有多少个类就设置是多少,不知道那就把点描出来你分析下有几个类)
2. 随机选取k个点。将这k个点作为聚类中心点。
3. 遍历所有点计算该点到那k个聚类中心点的距离。此时有k个距离,哪个距离最短,就认为当前这个点是属于这个聚类。
4. 执行完3.后,我们得到了k个聚类。现在我们需要重新计算聚类中心。此时聚类中心就是当前这个聚类的包含的点的平均值。也就是说各个点加起来取平均作为当前聚类的中心(此时的聚类中心已经不是数据中的某个点了,而是一个坐标值)。
5. 重复3.和4.这两个步骤很多次。(至于多少次你自己决定)
k-means和k-NN有什么区别?
答:
- k-means是无监督学习算法。什么叫做无监督学学习?就是给一堆水果的照片给你计算机看,告诉它一共有k种水果。至于这k种水果到底是什么计算机是不知道的。它只知道把相似的照片分类在一起凑成k个类就可以。然后新来一张照片它就计算这张照片到k个聚类中心的距离,哪个近就认为新来这个照片属于哪个聚类。至于它具体是什么水果算法是不知道的。。
- k-NN([k近邻算法]是有监督学习算法。你得告诉它什么每张照片是什么水果,然后新来一张照片它就计算这张照片与其他所有照片的距离(假设可以计算),然后它统计下和它最近(最相似的)那k张照片是哪种水果。如果那k个照片“苹果”这个标签出现次数最多,那么认为新来的照片就是苹果。
数据图演示k-means的操作步骤
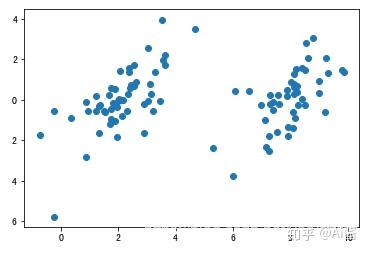
1. 加载数据(分析有几个聚类,k的值等于聚类数量)
现在我们分析出大致有2个类。于是我们设置k=2。
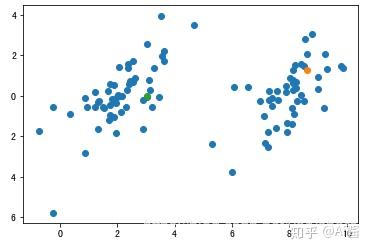
2. 随机选k个点作为聚类中心
在本文章第1.步提到了k=2.所以我们随机选2个点作为聚类中心。可以看到下面有两个点已经被选中作为聚类中心了。一个是绿色一个是橘黄。
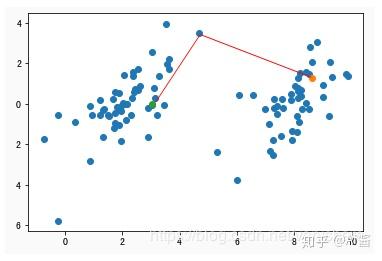
3. 遍历所有点计算这些点到k个聚类中心点的距离
举个例子,现在我们到了一个点。然后计算了它到两个聚类中心的距离。可以看到它离绿色点比离橘黄色近。所以认为当前这个点属于绿色这个点所在的聚类里面。我们需要遍历所有点。
第一轮遍历所有点,并把这些点归类后的结果。(橘黄色那堆是上图绿色点所代表的聚类,蓝色点是橘黄色那个点代表的聚类)
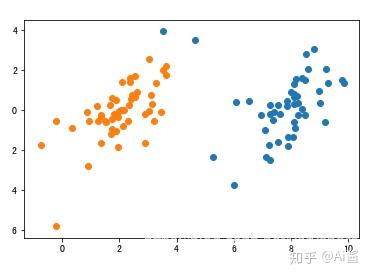
4. 根据3.中得到的两个聚类,重新计算聚类中心
绿色点是橘黄色那堆点的新聚类中心,红色点是蓝色那堆点的新聚类中心。
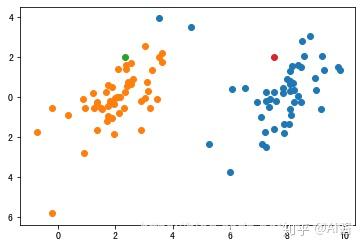
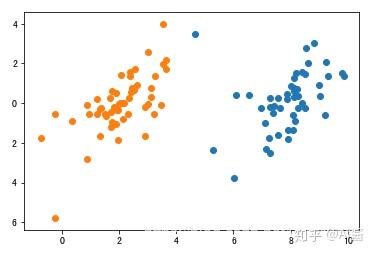
5. 重复步骤3.和4.(重复多少次你自己决定)
这是重复循环3.和4.三次后的结果(效果还是非常惊艳的)。
Python 代码实现
下面是以上分析的数据+Python代码实现。
import matplotlib.pyplot as plt
import numpy as np
##########加载数据############
def load_data_set():
"""
加载数据集
:return:返回两个数组,普通数组
data_arr -- 原始数据的特征
label_arr -- 原始数据的标签,也就是每条样本对应的类别
"""
data_arr = []
label_arr = []
# 如果想下载参照https://github.com/varyshare/AiLearning/blob/master/data/6.SVM/testSet.txt
# 欢迎follow的我github
f = open('myspace/svm_data.txt', 'r')
for line in f.readlines():
line_arr = line.strip().split()
data_arr.append([np.float(line_arr[0]), np.float(line_arr[1])])
label_arr.append(int(line_arr[2]))
return np.array(data_arr), np.array(label_arr)
x,label = load_data_set()
# 绘制出数据点分析看有几个聚类
#plt.scatter(x[:,0],x[:,1])
##############k-Means算法#################
# 创建k个聚类数组,用于存放属于该聚类的点
clusters = []
p1 = [6,4]
p2 = [1,3]
cluster_center = np.array([p1,p2])
k = 2
for i in range(k):
clusters.append([])
epoch = 3
for _ in range(epoch):
for i in range(k):
clusters[i]=[]
# 计算所有点到这k个聚类中心的距离
for i in range(x.shape[0]):
xi = x[i]
distances = np.sum((cluster_center-xi)**2,axis=1)
# 离哪个聚类中心近,就把这个点序号加到哪个聚类中
c = np.argmin(distances)
clusters[c].append(i)
# 重新计算k个聚类的聚类中心(每个聚类所有点加起来取平均)
for i in range(k):
cluster_center[i] = np.sum(x[clusters[i]],axis=0)/len(clusters[i])
plt.scatter(x[clusters[0],0],x[clusters[0],1])
plt.scatter(x[clusters[1],0],x[clusters[1],1])
推荐阅读:
- pytorch神经网络实践(1): 安装与初次使用pytorch搭建神经网络实践手写数字识别教程
- 如何理解那个把嫦娥送上天的卡尔曼滤波算法Kalman filter?
- 啤酒与尿布?机器学习之Apriori算法挖掘商品之间的关联性Python实现
- 概率统计与机器学习神经网络的联系?
欢迎关注我的知乎专栏适合初学者的机器学习神经网络理论到实践。

