
今天要介绍的这篇paper是南开大学程明明团队 & 字节跳动AI实验室联合投于CVPR2020的一篇关于自矫正卷积的改进方案。话说,最近通过对卷积操作进行不同方式的设计而达到提升模型性能的方法还挺多的,比如前两天亚马逊张航、李沐等人提出的ResNeSt、港中文贾佳亚团队提出的SAN、密歇根州立大学提出的MUXConv、南开大学程明明团队提出的Res2Net、蔡司公司提出的BSConv、华为提出的DyNet、MSRA提出的DynamicConv、谷歌提出的CondConv、清华大学提出的XSepConv与ACNet、新加坡国立大学颜水成团队提出的OctConv以及字节跳动提出并用于图像超分领域的SCN。感兴趣的小伙伴可以自己去看一下上述论文。
Abstract
作者提出通过改进CNN的卷积特征变换模块(即设计一种与卷积等价的模块)而无需调整网络架构达到提升性能的目的。作者提出一种新颖的自矫正卷积,它可以通过特征的内在通讯达到扩增卷积感受野的目的,进而增强输出特征的多样性。不同于标准卷积采用小尺寸核同时融合空域与通道信息,作者所设计的SCConv可以通过自矫正操作自适应构建long-range空域与通道间相关性。SCConv的这种特性可以帮助CNN生成更具判别能力的特征表达,因其具有更丰富的信息。作者所设计的SCConv极为简单且通用,可以轻易嵌入到现有CNN架构中,而不会导致参数量增加与计算复杂度提升。作者最后还通过实验证明:嵌入SCConv的模型(涵盖分类模型、检测模型、实例分割以及关键点检测模型)均可得到一定程度的性能提升。
Method
假设输入特征为



受限于上述计算方式,输出的卷积特征的感受野比较有限且所学习的特征模式具有相似性,进而导致所学习的特征具有较少的判别能力。为缓解上述缺陷,作者提出了self-calibrated convolution。
Self-Calibrated Convolutions
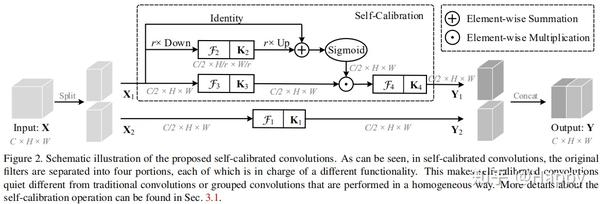
上图给出了作者所涉及的SCConv模块架构示意图。我们首先假定输入与输出具有相同的通道数,即


首先,将输入X均匀划分为


在自矫正分支,对于输入

所提的SCConv具有这样的三点优势:
- 自矫正分支可以极大的提升输出特征的感受野;
- 自矫正分支仅考虑空域位置的信息,避免考虑不想管的区域信息;
- 自矫正分支可以编码多尺度特征信息。
为验证所提方案的有效性,作者将其嵌入到ResNet中,采用所提SCConv替换Bottleneck中的第二个卷积,而保持其他不变。自矫正分支中的下采样率r默认设为4.
Experiments
首先,作者在ImageNet上验证所提方案改进的ResNet的性能。在Pytorch官方模型基础上进行魔改,训练过程参考ResNeXt一文,即避免因Tricks导致性能的较大差异。相关实验结果见下图。
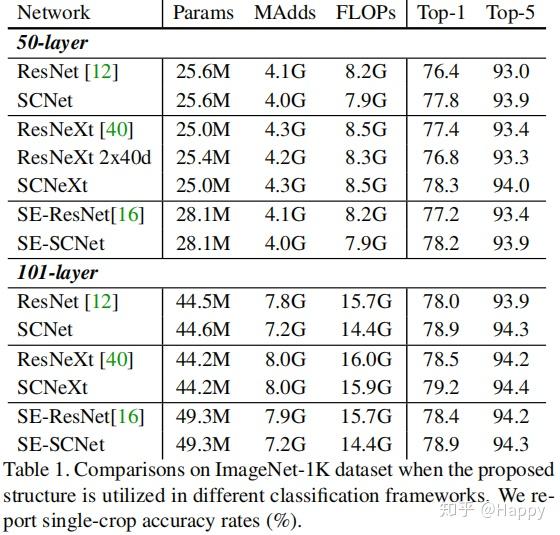
从上图可以看出:(1) 所提改进具有极好的泛化性能,无论ResNet、ResNeXt还是SE-ResNet均可得到一定程度的性能提升。
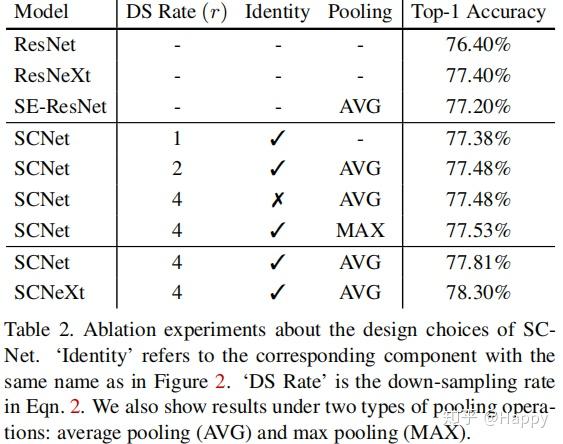
与此同时,作者还对所提方法进行不同配置的实验性分析,相关结果见上图。从中可以看出:当下采样率为4,池化方式为均值池化时具有最佳性能。
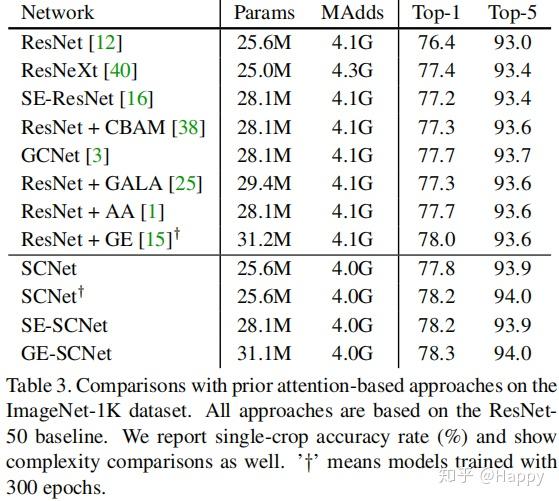
此外,作者还将其与其他注意力机制(CBAM、SENet、GALA、AA、GE等)方法进行了性能对比,见上图。从中可以看出:(1)其他注意力机制方法大多需要额外的可学习参数,而本文所提方法则无需额外可学习参数;(2) 所提方法具有更优的性能;(3)当所提方法与GE、SE组合时可以进一步提升模型性能,可以看出所提方法与注意力机制是两种不同类型的特征增广模块。
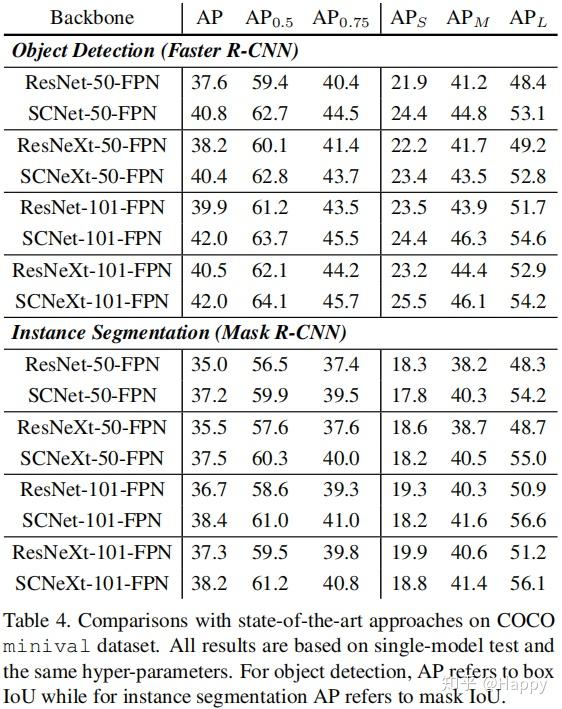
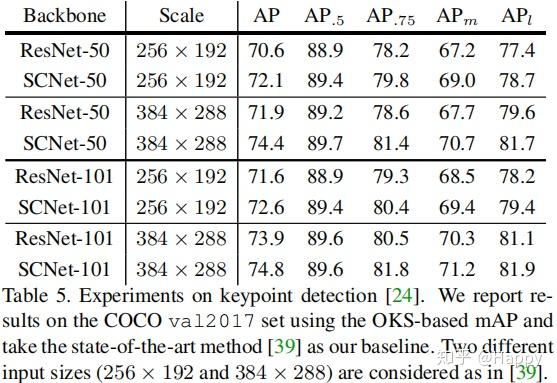
最后,作者将所提方案拓展到目标检测、关键点检测、实例分割等应用领域,进一步验证了所提方案的性能,可以一致性的提升改善模型的性能。
Conclusion
作者提出一种新颖的自矫正卷积,它可以多样化的利用卷积中的滤波器。为进一步提升输出特征的多样性,作者引入了自适应响应校正操作,所提出的自矫正卷积可以轻易嵌入到图像分类网络中并提升改善网络性能。
Coding
# Note: 作者在实现代码中并未进行K1部分特征变换。
class SCConv(nn.Module):
def __ini__(planes, stride, pooling_ratio):
super().__init__()
self.k2 = nn.Sequential(
nn.AvgPool2d(kernel_size=pooling_ratio, stride=pooling_ratio)
nn.Conv2d(planes, planes, 3, 1, 1, bias=False),
nn.BatchNorm(planes)
)
self.k3 = nn.Sequential(
nn.Conv2d(planes, planes, 3, 1, 1, bias=False),
nn.BatchNorm2d(planes)
)
self.k4 = nn.Sequential(
nn.Conv2d(planes, planes, 3, 1, 1, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU()
)
def forward(self, x):
identity = x
out = torch.sigmoid(torch.add(identity, F.interpolate(self.k2(x), identity.size()[2:])))
out = torch.mul(self.k3(x), out)
out = self.k4(out)
return out
推荐阅读:
本文章著作权归作者所有,任何形式的转载都请注明出处。更多动态滤波,图像质量,超分辨相关请关注我的专栏深度学习从入门到精通。

