
eyeriss是MIT提出的深度学习加速器,目前总共有2代芯片,v1和v2。第一代是基础结构,第二代在v1的基础上提供了稀疏化和更灵活的网络结构。eyeriss的结构和我们熟知的TPU,DLA,Thinker等有所不同,主要体现在其PE计算的方法和数据复用的结构上,应该更类似于功能弱化的DPU的PE。本文通过分析eyeriss的具体结构,探讨这种独立PE控制结构的优劣。
作者:MikesICroom
原文:https://zhuanlan.zhihu.com/p/91864795
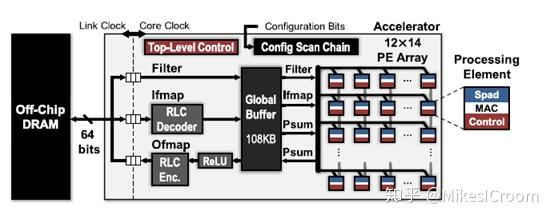
eyeriss的整体框架看起来没有什么太特殊之处。仍然是独立的memory和core分离的结构,通过总线进行通信。核内包含一个L1 memory(global buffer),整体控制模块(Top-level Control),数据数据的align(RLC),和核心运算矩阵:一个12x14的PE array。虽然有一定的配置性,eyeriss仍然是一个典型的ASIC加速器。仅可以对单个PE的运算进行控制,但是对于数据流的方向和形式,以及运算的组成是无法配置的。换句话讲,eyeriss并不是以控制流决定数据流,而是数据流驱动的执行模式,控制流是预先配好的。这一点也是很多深度学习加速器所推崇的。不过数据流驱动的方式和软件通常所能理解的方式并不相同,也不符合传统的编程语言和思维方式,这样不但需要全新的编译环境和语言,也需要软件人员能够转换思维。这是这类加速器所面临的最大问题。如CUDA这样的并行编程语言,可以说现在能熟练掌握的人也并不多,而并行编程相比传统串行编程的跨越度要远小于data flow编程。如果说只是研究,或者不面向通用化,eyeriss类的结构当然也可以仅仅面向几种模型做手动优化,但这样就大大缩小了适用的范围。因此数据流驱动的编译和编程上还有很长的路要走。
eyeriss的另一个特点是主要针对CNN模型,因此集中于视觉和图像方面的加速。现在大多数加速器也都集中在这里,也是最可能率先落地的领域。针对CNN的特点,eyeriss设计了独立的input feature map和out feature map的data align模块,用来做数据重排以适应后边的MAC矩阵的运算特点。同时也设计了单独的ReLu负责activation层运算。这都是很专用化的模块。后边可以看到整个PE的运算和复用也都是针对CNN的特征的,因此eyeriss在通常乘累加运算上效率较低。这一点的运算效力上不如TPU,对于使用im2col方式执行卷积的阵列也没有太大优势。那么eyeriss的优势在哪里?我认为并不在算力上,而是在能效。也就是说eyeriss更主要着眼在通过有效的数据复用,降低了对数据和权重的重复访问,从而降低整体功耗。因此eyeriss的结构更利于做低算力低功耗的端侧加速。当然它的结构也更适合于低算力。
另外,eyeriss的PE并不是简单的网格结构连接,而是支持更复杂的NoC结构。可以根据当前运算,支持纵横传输,斜向传输和单点广播。这种复杂的结构体现了eyeriss的研究性较重。复杂的连接在大规模的矩阵上会有很大的布线和时序问题,这也是eyeriss将矩阵设定在12x14的规模上的原因。因此eyeriss并不是个扩展性很强的结构
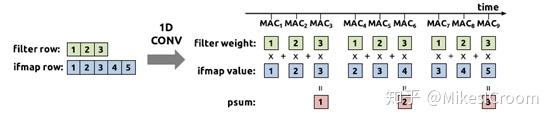
eyeriss把自己的卷积运算方式身称为RS flow(Row Stationary)。RS flow是一个一维卷积运算的方式。简单来说weight拆成一维向量,如1x3,在图像的行方向依据stride滑动,计算每个重复部分的结果。注意每个卷积的结果上,weight都是一样的,如果stride=1,那么图像上有2个数据也是一样的。这两方面都可以进行数据复用。因此执行上weight会预先pre-load到每个PE里,数据从横向进入,每个PE根据自己计算的部分将数据抓下来,执行乘累加操作,结果就累积在PE内部。每个PE内部包含一个成为Spad的小型存储单元就是用来存放内部权重和累加结果的。因此计算上每个PE可以不同步,只要抓到自己需要的数据计算就可以,并不需要如systolic那样全局的脉动控制。这里着重体现了数据流驱动的计算模式。eyeriss的计算方式有几个优点,首先是控制在PE内部,PE之前通过数据流驱动,这样不需要全局的同步控制,设计和时序上可以异步处理。其次权重可以存储多个数据在PE内部,而不是像TPU那样一个节点一个数据,这样单个PE的功能也更强一些,可以支持更复杂一些的运算。第三,这种一维复用的方式对于2D的卷积效率会高于TPU,因为它可以在图像行上复用,而不像TPU那样需要在channel方向操作。 不过一维复用会导致多个PE内的权重是一样的,而TPU的计算方式决定其每个节点的权重不同,这样eyeriss在权重存储方面会有较大的浪费,这也是其不能适应太大的模型的限制所在。因此,在3D卷积运算上,除了winograd这种特殊模式外,在计算效率上还没有能超过TPU这种systolic的阵列运算的。
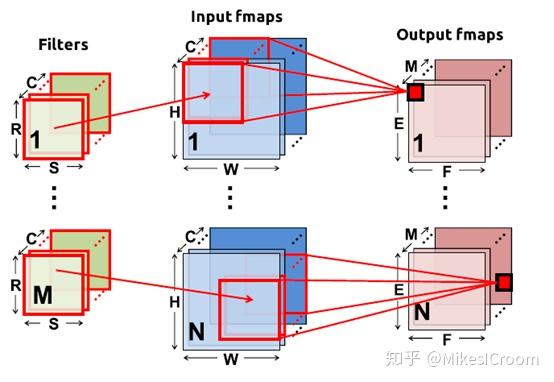
因此eyeriss的主要侧重点还是在能效。它提出了三重复用方式,首先是weight通过广播方式发送给每个PE,存储在其内部Spad。数据输入会首先考虑将对应该weight的全部数据都发送完再更换,体现了filter的reuse;数据一维横向输入后,每个卷积数据有有重叠,这样是输入数据的复用。同时输出可以在垂直方向上做output channel方向的累加。这些复用的主要来源是PE内部的SPad存储能力以及网络的广播能力。这样在数据复用上优于通过im2col方式计算卷积的加速器(即使用乘累加计算卷积)。不过其Spad存储首先就是面积上的代价,其次网络广播的方式也限制了单个core的PE数目,导致单位面积的计算密度上有所下降
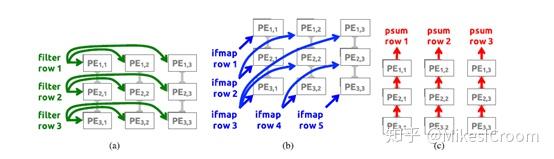
这个图可以看到PE矩阵数据传输的方式,控制上并不如TPU那样简单明了,对权重和数据的格式和输入方式需要完全固定,只有每个PE的执行可以不同步计算。这样虽说不需要systolic的全局控制,不过扩展性也大大降低了。当然,执行2D卷积上eyeriss的RS flow还是有较大优势,可以有效利用全部的MAC算力,这类运算主要是CNN第一层的卷积,将单层图像或者3层图像(3原色)进行第一次的channel扩展。2D卷积这并不是CNN的主要计算所在。后边多层的多channel 卷积(3D卷积)占据了绝大多数的算力,TPU在这里的优势比较大。论文之后还推导了当图像大于PE矩阵容量时如何进行切分和合并,这些细节就不一一描述,有兴趣可以去看原始论文。
总结一下,eyeriss主要在能效方面,通过PE的一维运算模式和多种网络数据发送模式,提供了更好的数据复用来降低CNN模型的功耗,提高单位算力的能效比。从2016年起eyeriss发表多篇论文,也算是研究领域比较火的项目了。不过由于其算力较小和复杂的复用模式,在工程上并不是一个很有优势的结构,而面向CNN的加速器通常都是非常大的算力需求,对功耗反而不是十分敏感。比如tesla的设计,中规中矩,但算力很强悍,在这方面eyeriss没有太大竞争力。同时为了复用还需要对数据和权重进行重排,也会耗费不小的面积。因此eyeriss的贡献主要还是在学术方面,对其一维卷积的运算方式以及数据复用思路还是可以好好的思考和借鉴。
[1] Y.-H. Chen, T. Krishna, J. Emer, V. Sze, "Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks," IEEE International Conference on Solid-State Circuits (ISSCC), pp. 262-264, February 2016
[2] Eyeriss Project
推荐阅读
更多AI处理器架构设计的技术干货,欢迎关注公众号MikesICroom,
同时欢迎关注AI处理器架构设计专栏。

