
转载自:智能单元
作者:Flood Sung
1 前言
近几年来,以DeepMind和OpenAI为首的AI明星公司基于深度强化学习创造了前所未有的突破,包括AlphaGo,AlphaStar,OpenAI Five, OpenAI Robot Hand,可以说掀起了深度学习革命的高潮。
这两年来,国内渐渐有AI公司围绕深度强化学习做落地,包括了腾讯,网易,字节跳动,启元世界,超参数等等,主要围绕游戏AI方向。当然也有其他公司考虑用深度强化学习做调度,推荐系统,比如阿里和滴滴等,但相对来说更小众一点。
目前,我们观察到一个严重的现象:CV算法岗位已经严重饱和,内卷,以至于大厂的竞争变得无比剧烈,就算是985,有顶会论文,也不见得能获得面试机会。然而以此同时,深度强化学习的岗位却存在严重稀缺,很难找到满足要求的人,大概10个简历有一个还可以就不错了。按道理AlphaGo 2016年就出来了,更早的DQN 2015年Nature(实际上是2013年NIPS)就出来了,应该已经吸引了很多童鞋进来才对,事实上却不是。可能很多童鞋担心深度强化学习落地难的问题,从我的角度看,这些童鞋确实不应该来研究深度强化学习(完全没有技术信仰的人不值得讨论),但是未来几乎可以肯定的是深度强化学习技术的应用领域会远超CV,毕竟一个是做决策,一个只是视觉。
所以,这篇博客首先是想跟童鞋们分享为什么要搞深度强化学习,然后就是深度强化学习的强者之路应该怎么去打。
2 为什么要搞深度强化学习?
首先也是最重要的原因是
这是一条通往通用人工智能的道路!
不说别的,什么算智能?懂得决策才算!猫猫狗狗都懂得识别物体,但是猫猫狗狗可不会打星际争霸!
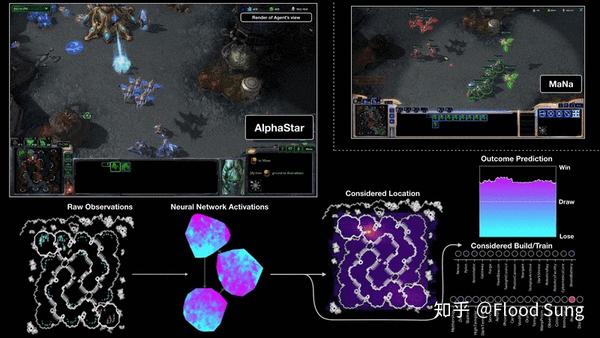
https://deepmind.com/blog/art...
当你通过AI打游戏第一次感受到AI是有智能的,那种触动是足够美妙的。
深度强化学习已经在事实上证明了其可行性,展现出了AI的智能。在通往AGI的路上,一定会有它的存在。至少,从David Silver的观点上:
AGI = DL + RL
可能现在我们再加一个东西Open-Endedness:
AGI = DL + RL + Open-Endedness
所以,当有一条很有潜力的道路摆在我们面前,我们为什么不去研究它呢? 这或许是了解人类智能真理的关键。
虽然如此,深度强化学习最被人诟病的问题就是怎么落地?
这恐怕是很多人面对现实放弃它的原因。
所以,这里我们需要来论证一下,深度强化学习到底能不能落地的问题。
这里我先提供我的观点:
深度强化学习在游戏AI上能够直接落地,在机器人,自动驾驶上还需要更多的时间!
这个观点实际上在业界已经得到了验证!感觉不算是什么秘密了。
首先是学术界的研究成果,已经攻克了:
- 围棋
- 象棋
- 德州扑克
- 麻将
- 其他简单棋牌类游戏
- Dota
- 王者荣耀
- 星际争霸
其次是国内工业界已有的落地情况:
- 腾讯的觉悟王者荣耀
- 网易的格斗游戏,三人篮球等
- 超参数的吃鸡
- 。。。
国外的Obisoft,EA也都有深度强化学习的尝试。
什么是未来呢?
DRL-based NPC!!!
或者就称 AI-based NPC
这可以给游戏带来前所未有的体验。一方面你玩游戏有可能不知道队友是AI,另一方面你会更愿意跟AI玩!游戏不再是游戏,而是虚拟世界!
这种感觉不比通用人工智能差,同样很吸引人。
并且将游戏做好了,未来就有机会迁移到真实的物理世界,实现机器人革命。
当前,由于新冠,人们的生活方式发生了巨大改变,远距离工作生活慢慢变成常态,游戏也会越来越多的成为人们生活的一部分(腾讯股票这么涨不是看不到呀)。所以,研究深度强化学习没有理由让你失业,相反,你将掌握未来!
所以,还在担心内卷的童鞋,考虑一下哦。
接下来,我们来聊聊深度强化学习如何从入门到强者!
3 深度强化学习的强者之路
3.1 深度强化学习的知识体系
深度强化学习不得不说是一个门槛相对CV更高的方向,因为它需要考虑很多CV不需要考虑的问题。下图是深度强化学习研究所需的知识体系:
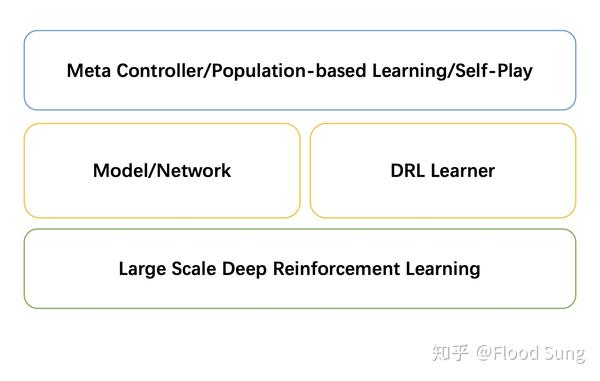
3.1.1 Large Scale Deep Reinforcement Learning 大规模深度强化学习
深度强化学习的成功依赖于算力,并且是远高于CV问题的算力。这是由于深度强化学习reward稀少,网络更新信号少,采样非常低效(sample inefficiency)导致的。所以,实现大规模的深度强化学习是必不可少的。因为深度强化学习的数据是通过和环境交互产生的,所以和CV的数据处理是完全不一样的。
如何才能高效并行的产生海量的数据供神经网络进行学习是大规模深度强化学习的关键。
为此,学术界工业界都开发了很多实现大规模深度强化学习的框架和理论:
- Ray/Rllib
- Fiber
- OpenAI Rapid
- Google Seed RL
3.1.2 Model/Network
由于是面向决策,深度强化学习的神经网络模型有其特别的需求,和一般CV问题的网络模型设计很不一样,比如AlphaStar的网络模型:
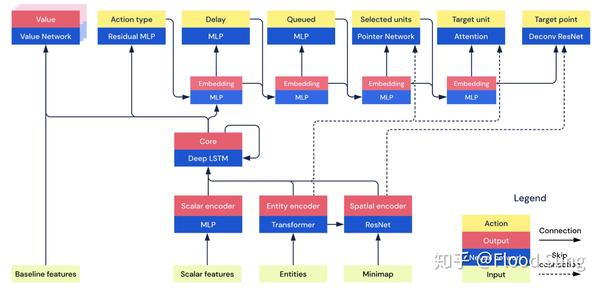
需要,Attention,Scatter Connection,Autoregressive Model,Pointer Network,LSTM等等网络结构。
3.1.3 DRL Learner
这是深度强化学习的算法部分,研究怎么采集数据利用数据更新神经网络模型从而获得更好的效果。
最经典的就是PPO了

3.1.4 Meta Controller/Population-based Learning/Self-Play
仅有DRL Learner还不够,很多游戏是对抗性的多智能体游戏,Agent训练面对的对手是不断变化的,因此我们需要给agent提供合适的对手才能让DRL learner能够学出好的智能体。这一点从AlphaGo的self-play就开始了,到了AlphaStar已经发展出了League:
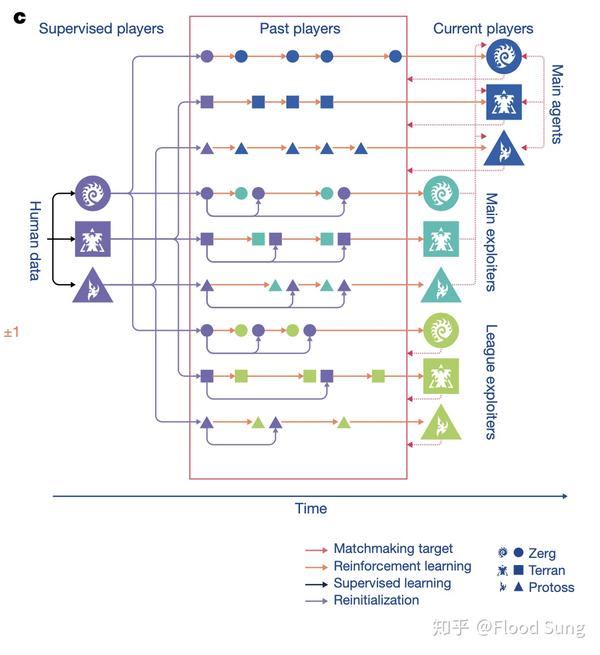
有了以上的组件,深度强化学习的AI才能真正运转起来,获得我们希望得到的效果。
那么对于要入门的童鞋,怎么开始,如何变强呢?
3.2 从零开始构建深度强化学习的知识体系
显然,要成为一个合格的深度强化学习研发人员,需要对整个知识体系有完全的了解,并且对其中的主要部分有深刻的理解和实践。
一般,我们分以下几步来构建知识体系:
Step 1:深度学习,掌握神经网络的各种基本模型
当前,对于构建深度强化学习的网络模型,主要会用到这些组件:
- CNN
- RNN/LSTM
- Attention, Transformer, Pointer Network
- Memory Network, DNC,...
- Graph Network (目前还比较少)
Step 2:深度强化学习算法
这部分是深度强化学习的核心,目前主流包括:
- DQN
- Rainbow,Distributional Q Learning
- IMPALA,UPGO
- SAC
- R2D2,R2D3,APE-X
- PPO,APPO
除此之外,深度强化学习算法理论还包括了:
- Model-based Learning
- MCTS (有些问题可以用到比如围棋)
- Exploration
- Imitation Learning
- Multi-task Learning
- Meta Reinforcement Learning
- Hierarchical Reinforcement Learning
这些额外的部分都是为了辅助核心的算法让agent学的更快更强。
对于额外的部分,知道的越多当然越好了。
Step 3:Large Scale Deep Reinforcement Learning 大规模深度强化学习
这部分的核心是理解掌握大规模深度强化学习的框架构建,目前主流的可以通过以下几种去理解(有的是框架,有的是开源代码,有的是理论):
- IMPALA
- Rapid
- Fiber
- Seed RL
- Rllib
- R2D3
这部分工作一般需要有研究MLsystem的童鞋配合,要不然搭不起来。目前K8s是比较好的选择,比如Fiber就完美支持K8s,OpenAI的集群也都是基于K8s搭建。
Step 4: Meta Controller/Population-based Learning/Self-Play
只有有了self-play,深度强化学习才能展现其魅力,这部分包括了:
- AlphaGo self-play
- AutoCurricula
- Domain Randomization
- AlphaStar League
- Reward Shaping, Meta-learned Reward Shaping
- Meta Gradient, Self-tuning reinforcement Learning
- AI-generated Envs,Open-Endedness, Quality Diversity
总的来说,这部分是在Meta层面去控制Agent的训练。
前面三个step只能保证你可以训起来,能把Agent训成什么样,这部分是至关重要的。
Step 5:理解学术界核心的大工作
这个就不用多说了,基本上彻底理解了AlphaStar,OpenAI Five等巨型项目的实现,也就彻底的掌握了当前深度强化学习的最前沿了。
4 小结
深度强化学习已经发展出了比较完善的知识体系,虽然变得越来越复杂,但是真的越来越有意思了,希望以上分享的内容能够对深度强化学习感兴趣想进入的童鞋有所帮助。
由于本人水平有限,必然有所疏漏,望批评指正。
推荐专栏文章
更多嵌入式AI算法部署等请关注极术嵌入式AI专栏。

