
文章转载于:知乎
作者:于璠
本篇是深度概率学习系列的最后一篇文章啦,前几篇的内容可以戳下面的专栏进行回顾哦。
本篇主要聚焦于对贝叶斯深度学习的应用进行分享,也非常欢迎大家一起探讨下贝叶斯深度学习在继深度学习后会带来什么样的发展和突破,以及相应的应用场景。
1. 深度概率特性
2. 深度概率推断算法与概率模型
3. 深度神经网络与贝叶斯神经网络
4. 贝叶斯应用工具箱
我们知道,深度学习在过去一段时间取得了很大的成功,包括计算机视觉、自然语言处理和语音识别等领域,可以理解为AI系统的看、读和听能力,这相当于是一种感知能力。但如果希望构建一个全面的AI系统,同样也应具备思维能力。
怎么理解呢,举个例子,在医学诊断中,除了医学图像和患者的描述这种感知外,医生还需要找到各症状间的联系,推断出病因,在这里,医生的思维能力十分关键。这种思维能力包括因果推理、条件依赖和不确定性建模等,这些传统深度学习是达不到的。而贝叶斯深度学习将感知任务和推理任务结合,相互借鉴,使得一方面医学图像有助于医生的诊断和推断,另一方面,诊断和推断反过来有助于理解医学图像。
下面我们具体来讲下贝叶斯深度学习应用的几个典型场景。
Uncertainty Estimation(不确定性估计)
关于不确定性评估的应用我们在第一篇文章中有简单的提及,这里稍微详细地展开一下。
首先,不确定性分为两种:偶然不确定性和认知不确定性。
· 偶然不确定性(Aleatoric Uncertainty):描述数据中的内在噪声,即无法避免的误差,这个现象不能通过增加采样数据来削弱,也叫做数据不确定性。在一般网络中,观测噪声参数往往作为模型权值衰减的一部分被忽略。因此,一般会修改损失函数来学习这部分误差以获取数据这类不确定性。
· 认知不确定性(Epistemic Uncertainty):模型自身对输入数据的估计可能因为训练不佳、训练数据不够等原因而不准确,可以通过增加训练数据等方式来缓解,也叫做模型不确定性。一般会通过改变网络结构来近似贝叶斯神经网络的方法,例如Monte Carlo dropout和Monte Carlo BN等。
在MindSpore深度概率编程库中,我们提供了不确定性评估的工具箱,可以很方便的获取分类模型和回归模型的偶然不确定性和认知不确定性。
在使用前,需要先训练好模型,以LeNet5为例,使用方式如下:
from mindspore.nn.probability.toolbox.uncertainty_evaluation import UncertaintyEvaluation
from mindspore.train.serialization import load_checkpoint, load_param_into_net
if __name__ == '__main__':
# get trained model
network = LeNet5()
param_dict = load_checkpoint('checkpoint_lenet.ckpt')
load_param_into_net(network, param_dict)
# get train and eval dataset
ds_train = create_dataset('workspace/mnist/train')
ds_eval = create_dataset('workspace/mnist/test')
evaluation = UncertaintyEvaluation(model=network,
train_dataset=ds_train,
task_type='classification',
num_classes=10,
epochs=1,
epi_uncer_model_path=None,
ale_uncer_model_path=None,
save_model=False)
for eval_data in ds_eval.create_dict_iterator():
eval_data = Tensor(eval_data['image'], mstype.float32)
epistemic_uncertainty = evaluation.eval_epistemic_uncertainty(eval_data)
aleatoric_uncertainty = evaluation.eval_aleatoric_uncertainty(eval_data)
print('The shape of epistemic uncertainty is ', epistemic_uncertainty.shape)
print('The shape of aleatoric uncertainty is ', aleatoric_uncertainty.shape)eval\_epistemic\_uncertainty计算的是认知不确定性,也叫模型不确定性,对于每一个样本的每个预测标签都会有一个不确定值;eval\_aleatoric\_uncertainty计算的是偶然不确定性,也叫数据不确定性,对于每一个样本都会有一个不确定值。uncertainty的值位于[0,1]之间,越大表示不确定性越高。
完整的使用代码可以戳这里Toolbox of Uncertainty Estimation
除了分类模型和回归模型外,不确定性评估也应用在目标检测和语义分割网络中,目标检测比较有代表性的是通过贝叶斯理论来改进模型。例如Gaussian YOLOv3,其将预测框中心坐标和长宽引入高斯分布,进行不确定性建模,从结果来看,相比于原来的YOLOv3,其效果得到了一定的提升。
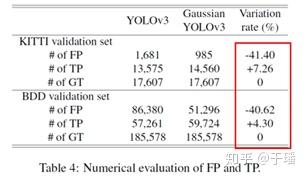
Gaussian YOLOv3对比YOLOv3
另外还有Bayesian YOLOv3,其通过在网络中加入Monte Carlo dropout及修改损失函数来进行不确定性建模,以获取目标检测框及分类的不确定性。

Bayesian YOLOv3效果图
同样地在语义分割领域,Bayesian Segnet通过在原网络中使用Monte Carlo dropout来获取分割后图像的不确定性。

Bayesian Segnet
当然,除了在计算机视觉任务中应用较多之外,在自然语言任务中也有了一定的研究,大家感兴趣的可以看下这篇文章《Quantifying Uncertainties in Natural Language Processing Tasks》。
Out-of-distribution Detection(OOD检测)
在深度概率学习系列中的第一篇文章中有提到,假如深度学习网络训练的时候是猫狗数据集,在测试阶段传入了兔子的图片,此时模型的预测输出肯定还是猫狗之一,但其实兔子的图片属于数据集分布外的样本,即OOD样本,贝叶斯深度学习在该领域中也具有一定的应用。
这里参考 @kinredon 的介绍,主要讲一下基于Uncertainty和Generative Model的OOD检测方法。
基于Uncertainty的方法
这个方法也是基于上文中不确定性评估做的,也就是说,在得到样本的不确定性值后,假如测试样本是在样本内的,那不确定性低;但如果是OOD样本,则不确定性比较高。
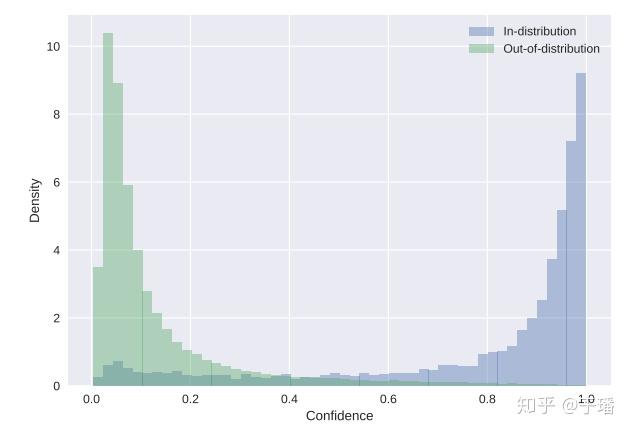
ID样本和OOD样本
上图则展示了根据预测结果的置信度来衡量样本是否是OOD样本,详细的内容大家可以看这篇文章Learning Confidence for Out-of-Distribution Detection in Neural Networks
基于Generative Model的方法
通过例如VAE网络来进行检测,具体的方法是:VAE网络的隐空间能学习出样本内数据的分布,但对于OOD样本的话,重构误差会比较大,这样就可以检测出来。关于VAE网络的原理有在第二篇文章中进行分享,链接戳这里。
于璠:MindSpore深度概率推断算法与概率模型zhuanlan.zhihu.com
有文章也指出,只基于VAE进行重构误差的比较很难得到一些特定的异常样本,这些样本在隐空间中距离样本距离很远,但是在流形空间中距离很近。因此,作者使用马氏距离来衡量样本在流形空间中的距离,这样结合重构误差和马氏距离一起来检测出OOD样本。下图是文章中OOD样本的检测效果图。
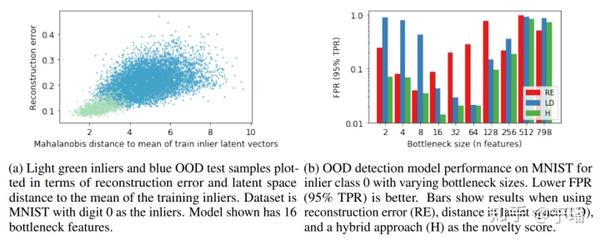
OOD样本的检测效果图
Active Learning(主动学习)
深度学习中存在着一个重要的问题:如何使用尽可能少的标注数据集训练一个模型,这个模型的性能可以达到一个由大量的标注数据集按照随机选择数据的得到的模型的性能。尤其在医疗领域,标注数据成本很高,需要有专业知识的医生来标注。
主动学习的主要目标是有效地发现训练数据集中高信息量的样本,并高效训练模型。和传统方法相比,主动学习可以从较大训练数据集中选择有辨别能力的样本点,减少训练数据的数量,并同时减少人工标注成本。
主动学习的研究主要是两个部分:选择策略和查询策略,选择策略指导模型从哪里选择未标注样本,查询策略指导模型如何确定未标注样本是否需要被标注。
下图表明了主要的三种选择策略方法,分别是Membership Query Synthesis、Stream-Based Selective Sampling和Pool-Based Sampling。
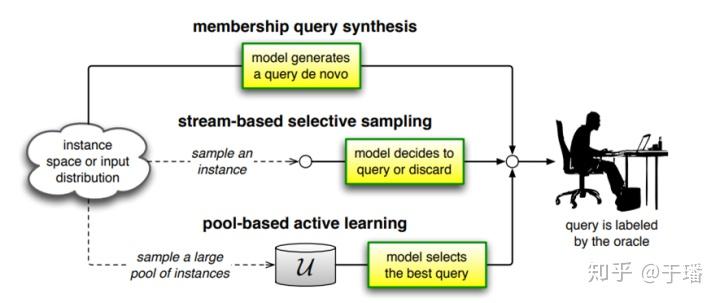
主动学习主要的三种选择策略方法
根据选择策略,在这里主要对Pool-Based Sampling(基于池的样例选择策略)进行展开,其当中涉及了较多的概率方法和贝叶斯方法。其他方法大家可以参考《Active Learning Literature Survey》这篇文章。
基于池的方法每次从系统维护的未标注样例池中按预设的选择规则选取一个样例交给基准分类器进行识别,当基准分类器对其识别出现错误时进行人工标注。提到的选择规则例如包括概率分布值和模型投票差异等。
概率分布值:最低置信度;边际采样;熵采样
模型投票差异:投票熵;KL散度
除了根据上述方法去做选择外,也有研究通过贝叶斯神经网络来做,该篇文章《Deep Bayesian Active Learning with Image Data》通过Bayesian CNN来改进原来的acquisition functions(BALD,Variation Ratios,Max Entropy和Mean STD)
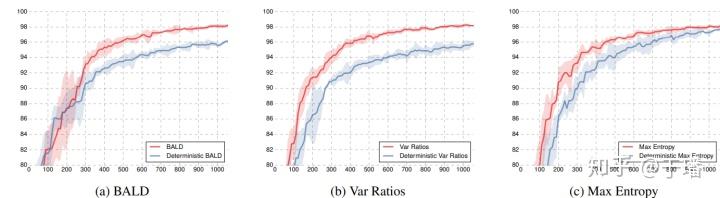
Bayesian CNN及基础的选择
上图中,红线代表的是引入了MC dropout的曲线,可以看到在几类基础的选择策略方法上,Bayesian CNN更快地达到了相同的准确率。
另外,贝叶斯也应用于强化学习、在线学习和优化等领域,感兴趣的欢迎大家一起讨论学习。
深度概率学习系列就到这里啦,总共写了四篇文章和大家一起分享,如有不足欢迎批评指正哈。也非常欢迎大家参与到深度概率学习的社区开发来,从底层的概率分布和概率映射的开发到上层贝叶斯应用工具箱的完善,一起来完善深度概率特性。
参考文献:
[1] Y. Gal and Z. Ghahramani, “Dropout as a bayesian approximation: representing model uncertainty in deep learning,” Proceedings of the 33rd International Conference on Machine Learning, 2015.
[2] Mattias Teye, Hossein Azizpour and Kevin Smith (2018). Bayesian Uncertainty Estimation for Batch Normalized Deep Networks. ICLR 2018 Conference.
[3] https://arxiv.org/abs/1904.04620
[4] Uncertainty Estimation in One-Stage Object Detection
[5] https://arxiv.org/abs/1511.02680
[6] DeVries, T., & Taylor, G. W. (2018). Learning confidence for out-of-distribution detection in neural networks. arXiv preprint arXiv:1802.04865.
[7] Denouden, T., Salay, R., Czarnecki, K., Abdelzad, V., Phan, B., & Vernekar, S. (2018). Improving reconstruction autoencoder out-of-distribution detection with mahalanobis distance. arXiv preprint arXiv:1812.02765.
[8] https://minds.wisconsin.edu/bitstream/handle/1793/60660/TR1648.pdf?sequence=1
[9] https://arxiv.org/abs/1703.02910
- The End -
推荐阅读
更多嵌入式AI技术相关内容请关注嵌入式AI专栏。

