
文章转载于:知乎
作者:金雪锋
最近在考虑AI框架(MindSpore)如何帮助模型开发者提升精度调优效率的问题,总结了一些思路供参考。
模型准确率不高的常见原因
模型的准确率不高,模型的metrics达不到预期,常见的原因有以下几方面:
1、数据集问题
- 数据集中缺失值过多
- 数据集每个类别的样本数目不均衡
- 数据集中存在异常值
- 数据集中的数据对预测结果帮助不大(例如使用年龄预测性别)
2、数据处理算法设计和实现问题
- 数据处理参数有误
- 未对数据进行归一化
- 特征提取算法(如果使用了)存在错误
- train和validation数据处理方式不一致
3、算法设计和实现问题
- API使用错误
- 没有遵循深度学习框架约束
- 算子使用错误
- 计算图结构错误
- 权重共享错误
- 权重冻结错误(例如忘记冻结应冻结的权重)
- 节点连接错误(例如应连接在图中的节点未连接)
- loss函数错误
- 优化器错误
- 权重初始值错误
- 算法本身设计有缺陷导致精度无法达到预期。
4、超参设置问题
5、普通python编程错误
6、环境问题
- 依赖软件问题
- 环境变量配置问题
- 云上环境问题
问题分析整体思路
分析模型准确率不高的问题,就是要分析数据集、数据处理、算法设计、算法实现等方面是否存在问题。这一过程是有章可循的,建议参考下面五步,逐步定位模型表现问题:
第一步 检查代码和超参
第二步 检查模型结构
第三步 检查输入数据
第四步 检查loss曲线
第五步 检查准确率是否达到预期
代码是准确率问题的重要源头,检查代码重在对脚本和代码做检查,力争在源头发现问题;模型脚本体现了AI模型在AI框架上的表达和映射,检查模型脚本重在检查脚本表达和算法工程师的设计是否一致;有的问题要到动态的训练过程中才会发现,检查输入数据和loss曲线正是将代码和动态训练现象结合进行检查;检查准确率是否达到预期则是对整体分析过程的重新审视。此外,充分准备,熟悉模型也是很重要的。下面将分别介绍这些思路。
模型问题分析准备
1、回顾算法设计,全面熟悉模型
分析前,要先对算法设计做回顾,确保算法设计明确。如果参考论文实现模型,则应回顾论文中的全部设计细节和超参选择情况;如果参考其它脚本实现模型,则应确保有一个唯一的、精度能够达标的标杆脚本;如果是新开发的算法,也应将重要的设计细节、超参选择、参考论文和脚本明确出来。这些信息是后面检查脚本步骤的重要依据。
分析问题前,还要全面熟悉模型。只有熟悉了模型,才能准确理解各种现象中蕴含的信息,判断是否存在问题,查找问题源头。因此,花时间理解模型算法和结构、理解模型中算子的作用和参数的含义、理解模型所用优化器的特性是很重要的。动手分析问题细节前,建议先带着问题加深对这些模型要素的了解。
2、使用小数据集测试目标脚本能否成功拟合
若模型不能拟合(fit)小数据集,说明模型本身的设计存在问题。
第一步 检查代码和超参
代码是模型问题的重要源头,超参问题、模型结构问题、数据问题、算法设计和实现问题会体现在脚本中,对脚本做检查是定位模型问题很有效率的手段。
检查代码主要依赖代码走读和单元测试。代码走读建议使用小黄鸭调试法:在代码走读的过程中,耐心地向没有经验的“小黄鸭”解释每一行代码的作用,从而激发灵感,发现代码问题。检查脚本时,要注意检查脚本实现(包括数据处理、模型结构、loss函数、优化器等实现)同设计是否一致,如果参考了其它脚本,要重点检查脚本实现同其它脚本是否一致,所有不一致的地方都应该有充分合理的理由,否则就应修改。
还可以通过编写单元测试的方法检查脚本,将脚本在逻辑上拆分为多个模块或函数,然后编写单元测试,依次对这些模块和函数进行验证。
检查脚本时,也要关注超参的情况,超参问题主要体现为超参取值不合理,例如:
- 学习率设置不合理;
- loss\_scale参数不合理;
- 权重初始化参数不合理等。
第二步 检查模型结构
在模型结构方面,常见的问题有:
- 算子使用错误(使用的算子不适用于目标场景,如应该使用浮点除,错误地使用了整数除);
- 权重共享错误(共享了不应共享的权重);
- 权重冻结错误(冻结了不应冻结的权重);
- 节点连接错误(应该连接到计算图中的block未连接);
- loss函数错误;
- 优化器算法错误(如果自行实现了优化器)等。
建议通过检查模型代码的方式对模型结构进行检查。此外,还可以借助各种计算图可视化工具检查计算图。若有标杆脚本,还可以同标杆脚本对照查看计算图,检查当前脚本和标杆脚本的计算图是否存在重要的差异。
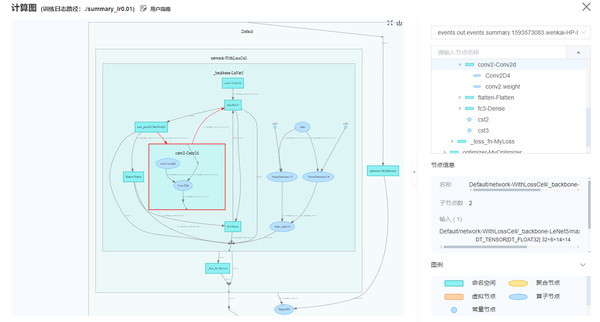
通过计算图可视化检查模型结构-来自MindSpore的可视化工具MindInsight
考虑到模型结构一般都很复杂,期望在这一步就能发现所有的模型结构问题是不现实的。只要通过可视化的模型结构加深对计算图的理解,发现明显的结构问题即可。后面的步骤中,发现了更明确的问题现象后,我们还会回到这一步重新检查确认。
第三步 检查输入数据
通过检查输入模型的数据,可以结合脚本判断数据处理流水线和数据集是否存在问题。输入数据的常见问题有:
- 数据缺失值过多;
- 每个类别中的样本数目不均衡;
- 数据中存在异常值;
- 数据标签错误;
- 训练样本不足;
- 未对数据进行标准化,输入模型的数据不在正确的范围内;
- finetune和pretrain的数据处理方式不同;
- 训练阶段和推理阶段的数据处理方式不同;
- 数据处理参数不正确等。
建议借助工具可视化输入数据,若数据明显不符合预期(例如数据被裁剪的范围过大,数据旋转的角度过大等),可以判断输入数据出现了一定的问题。

可视化查看输入模型的数据
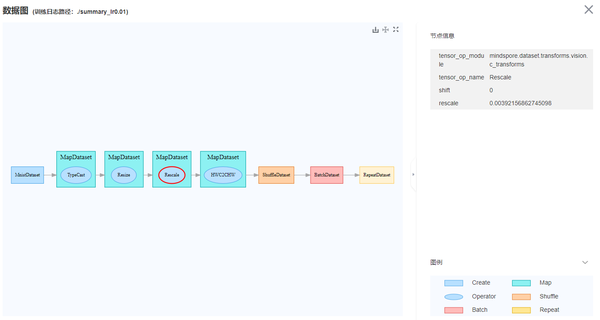
可视化查看数据处理流水线--来自MindSpore的可视化工具MindInsight
如果有标杆脚本,还可以同标杆脚本对照,检查数据处理流水线输出的数据是否和标杆脚本的数据相同。例如,将数据处理流水线输出的数据保存为npy文件,然后使用numpy.allclose()方法对标杆脚本和当前脚本的数据进行对比。如果发现不同,则数据处理阶段可能存在精度问题。
若数据处理流水线未发现问题,可以手动检查数据集是否存在分类不均衡、标签匹配错误、缺失值过多等问题。
第四步 检查loss曲线
很多模型问题会在网络训练过程中通过观察loss曲线发现,常见的问题或现象有:
- 权重初始化不合理(例如初始值为0,初始值范围不合理等);
- 权重中存在过大、过小值;
- 权重变化过大;
- 权重冻结不正确;
- 权重共享不正确;
- 激活值饱和或过弱(例如Sigmoid的输出接近1,Relu的输出全为0);
- 梯度爆炸、消失;
- 训练epoch不足;
- 算子计算结果存在NAN、INF;
- 算子计算过程溢出(计算过程中的溢出不一定都是有害的)等。
loss曲线能够反映网络训练的动态趋势,通过观察loss曲线,可以得到模型是否收敛、是否过拟合等信息。loss跑飞和loss收敛慢是模型准确率不高时的主要loss现象。当loss跑飞时,模型的准确率可能只有随机猜测的水平。当loss收敛慢时,若epoch不够多,loss始终也无法收敛到预期值,模型准确率将无法达到预期。
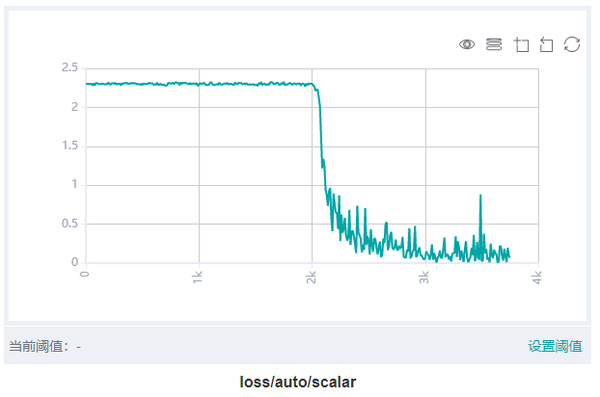
可视化查看loss曲线。图中展示了训练集上的loss随训练迭代数的变化情况。
部分问题(例如错误地冻结了不该冻结的权重)难以直接通过loss曲线观察出来,建议同时查看参数分布图,观察模型参数的变化情况,可以得到权重是否更新过快、过慢,权重分布范围是否正常等信息。
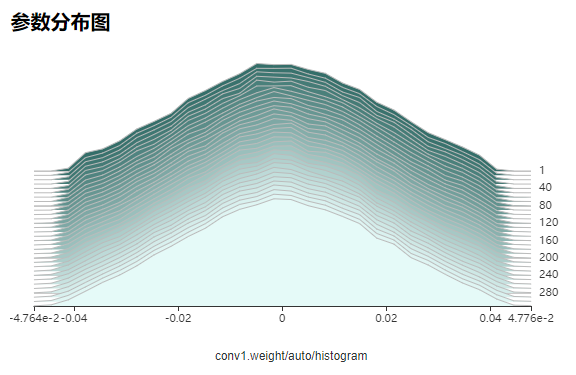
可视化查看训练过程中的权重变化情况。图中为conv1卷积的权重分布随训练迭代数的变化情况。
更进一步地,还可以使用深度学习领域的调试器,例如MindSpore框架的调试器(https://mindspore.cn/tutorial/training/zh-CN/master/advanced\_use/debugger.html )等工具,对训练现场进行检查,更准确地发现问题。
定位loss跑飞问题
loss跑飞是指loss中出现了NAN、+/-INF或者特别大的值。loss跑飞一般意味着算法设计或实现存在问题。定位思路如下:
- 回顾脚本、模型结构和数据:检查超参是否有不合理的特别大/特别小的取值,检查模型结构是否实现正确,特别是检查loss函数是否实现正确,检查输入数据中是否有缺失值、是否有特别大/特别小的取值。
- 观察参数分布图,检查参数更新是否有明显的异常。若发现参数更新异常,可以结合调试器定位参数更新异常的原因。
- 使用调试器对训练现场进行检查。
- 若loss值出现NAN、+/-INF,可使用“检查张量溢出”条件添加全局监测点,定位首先出现NAN、+/-INF的算子节点,检查算子的输入数据是否会导致计算异常(例如除零)。若是算子输入数据的问题,则可以针对性地加入小数值epsilon避免计算异常。
- 若loss值出现特别大的值,可使用“检查过大张量”条件添加全局监测点,定位首先出现大值的算子节点,检查算子的输入数据是否会导致计算异常。若输入数据本身存在异常,则可以继续向上追踪产生该输入数据的算子,直到定位出具体原因。
- 若怀疑参数更新、梯度等方面存在异常,可使用“检查权重变化过大”、“检查梯度消失”、“检查梯度过大”等条件设置监测点,定位到异常的权重或梯度,然后结合张量检查视图,逐层向上对可疑的正向算子、反向算子、优化器算子等进行检查。
定位loss收敛慢问题
loss收敛慢是指loss震荡、收敛速度慢,经过很长时间才能达到预期值,或者最终也无法收敛到预期值。相较于loss跑飞,loss收敛慢的数值特征不明显,更难定位。定位思路如下:
1、回顾脚本、模型结构和数据,
- 检查超参是否有不合理的特别大/特别小的取值,特别是检查学习率是否设置过小或过大,学习率设置过小会导致收敛速度慢,学习率设置过大会导致loss震荡、不下降;
- 检查模型结构是否实现正确,特别是检查loss函数、优化器是否实现正确;
- 检查输入数据的范围是否正常,特别是输入数据的值是否过小
2、观察训练看板中的参数分布图,检查参数更新是否有明显的异常。若发现参数更新异常,可以结合调试器定位参数更新异常的原因。
3、使用调试器模块对训练现场进程检查。
- 可使用“检查权重变化过小”、“检查未变化权重”条件对可训练(未固定)的权重进行监测,检查权重是否变化过小。若发现权重变化过小,可进一步检查学习率取值是否过小、优化器算法是否正确实现、梯度是否消失,并做针对性的修复。
- 可使用“检查梯度消失”条件对梯度进行监测,检查是否存在梯度消失的现象。若发现梯度消失,可进一步向上检查导致梯度消失的原因。例如,可以通过“检查激活值范围”条件检查是否出现了激活值饱和、Relu输出为0等问题。
4、若认为loss的收敛速度正常,可以尝试增加epoch数目继续训练,看epoch数目增加后,loss能否收敛到预期值。
第五步 检查准确率是否达到预期
1、检查训练集准确率
若训练集上loss已收敛,但是训练集上的准确率未达到预期,首先应重点检查loss函数是否实现正确,使用前文介绍的方法走读代码、编写单元测试对loss函数进行检查。必要时重新进行前四步,回顾代码、模型结构、输入数据和loss曲线:
- 检查脚本,检查超参是否有不合理的值
- 检查模型结构是否实现正确
- 检查输入数据是否正确
- 检查loss曲线的收敛结果和收敛趋势是否存在异常
若未发现问题,则应考虑优化超参取值。若多组超参均没有好的效果,则应考虑优化模型结构和算法,尝试新的idea。
2、检查验证集准确率
若训练集准确率和验证集准确率都未达到预期,则应首先参考上一节检查训练集准确率。若训练集准确率已达到预期,但是验证集准确率未达到预期,大概率是模型出现了过拟合,处理思路如下:
- 检查验证集评估脚本的评估逻辑有无错误。特别是数据处理方式是否与训练集一致,推理算法有误错误,是否加载了正确的模型checkpoint。
- 增加数据量。包括增加样本量,进行数据增强和扰动等。
- 正则化。常见的技术如参数范数惩罚(例如向目标函数中添加一个正则项),参数共享(强迫模型的两个组件共享相同的参数值),提前中止训练等。
- 适当降低模型的规模。例如减少卷积层数等。
3、检查测试集准确率
若验证集和测试集准确率都未达到预期,则应首先参考上一节检查验证集准确率。若验证集准确率已达到预期,但是测试集准确率未达到预期,考虑到测试集的数据是模型从未见过的新数据,原因一般是测试集的数据分布和训练集的数据分布不一致。处理思路如下:
- 检查测试集评估脚本的评估逻辑有误错误。特别是数据处理方式是否与训练集一致,推理算法有误错误,是否加载了正确的模型checkpoint。
- 检查测试集中的数据质量,例如数据的分布范围是否明显同训练集不同,数据是否存在大量的噪声、缺失值或异常值。
小结
准确率低等问题的分析有章可循,首先检查代码和超参,然后检查模型结构,检查输入数据,检查loss曲线,最后确认准确率达到预期。由于准确率低可能存在多个原因,每一步中的问题修复后,都要重新执行训练和评估,确认是否还有其它的潜在问题。希望这些分析思路能起到良好的引导的作用,帮助你训练出满意的模型。
注1:部分调试器检查功能仅在MindSpore调试器(https://mindspore.cn/tutorial/training/zh-CN/master/advanced\_use/debugger.html )中可用。
注2:文中截图全部来自MindSpore可视化调试调优工具MindInsight(https://mindspore.cn/tutorial/training/zh-CN/master/advanced\_use/visualization\_tutorials.html )。
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

