
本文转自:知乎
作者:djh
短文本相似度的计算在nlp自然语言处理中是十分重要的知识,它运用于很多领域,例如文本分类,文本去燥等等。
今天来看几种文本相似度的计算算法,有些会讲原理有些会直接给出算法。
基于文本字符的相似度计算
Jaccard
最长公共子序列(LCS)
最小可编辑距离
基于词频向量的相似度计算
余弦相似度
主要有这么几种吧,接下来我们一一介绍。
基于文本字符的相似度计算
Jaccard :
Jaccard index , 又称为Jaccard相似系数(Jaccard similarity coefficient),对于字符串A、B,分别做分词得到分词集SA,SB,那么Jaccard系数=SA与SB交集/SA与SB并集。jaccard index 巧妙的把文本,变成数学的集合运算:
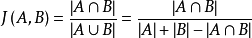
基础代码如下:
def jaccard_similarity(str_a,str_b):
seta = split_words(str_a)
setb = split_words(str_b)
print(seta)
print(setb)
sa_sb = 1.0 * len(seta & setb) / len(seta | setb)
return sa_sb 最长公共子序列(LCS)
- 1. 子序列(subsequence): 一个特定序列的子序列就是将给定序列中零个或多个元素去掉后得到的结果(不改变元素间相对次序)。例如序列<A,B,C,B,D,A,B>的子序列有:<A,B>、<B,C,A>、<A,B,C,D,A>等。
- 2.公共子序列(common subsequence): 给定序列X和Y,序列Z是X的子序列,也是Y的子序列,则Z是X和Y的公共子序列。例如X=<A,B,C,B,D,A,B>,Y=<B,D,C,A,B,A>,那么序列Z=<B,C,A>为X和Y的公共子序列,其长度为3。但Z不是X和Y的最长公共子序列,而序列<B,C,B,A>和<B,D,A,B>也均为X和Y的最长公共子序列,长度为4,而X和Y不存在长度大于等于5的公共子序列。
- 3.最长公共子序列问题(LCS:longest-common-subsequence problem):及在公共子序列中最长的表示。
def lcs_similarity(str_a, str_b):
# 得到一个二维的数组,类似用dp[lena+1][lenb+1],并且初始化为0
lengths = [[0 for j in range(len(str_b)+1)] for i in range(len(str_a)+1)]
for i, x in enumerate(str_a):
for j, y in enumerate(str_b):
if x == y:
lengths[i+1][j+1] = lengths[i][j] + 1
else:
lengths[i+1][j+1] = max(lengths[i+1][j], lengths[i][j+1])
result = ""
x, y = len(str_a), len(str_b)
while x != 0 and y != 0:
if lengths[x][y] == lengths[x-1][y]:
x -= 1
elif lengths[x][y] == lengths[x][y-1]:
y -= 1
else:
assert str_a[x-1] == str_b[y-1] #后面语句为真,类似于if(a[x-1]==b[y-1]),执行后条件下的语句
result = str_a[x-1] + result #注意这一句,这是一个从后向前的过程
x -= 1
y -= 1
longestdist = lengths[len(str_a)][len(str_b)]
ratio = longestdist/min(len(str_a),len(str_b))
return ratio 最小可编辑距离
最小编辑距离问题是指两个字符串之间存在差异,例如abcd 和 acd,或者happy 和 huppy ,如何通过最小的手段让两个字符一样。可以用的操作为,插入,删除和替换。
代码如下:
def med_similarity(str_a,str_b):
len_sum = float(len(str_a) + len(str_b))
long_str = None
short_str = None
if len(str_a) > len(str_b):
long_str,short_str = str_a,str_b
else: long_str,short_str = str_b,str_a distances = range(len(short_str) + 1) for long_str_index,char_in_long_str in enumerate(long_str): new_distances = [long_str_index+1] for short_str_index,char_in_short_str in enumerate(short_str): if char_in_short_str == char_in_long_str: new_distances.append(distances[short_str_index]) else: del_distance = distances[short_str_index] # 删除 insert_distance = distances[short_str_index+1] # 插入 replace_distance = new_distances[-1] # 变换 new_distances.append(1 + min((del_distance,insert_distance,replace_distance))) distances = new_distances mindist = distances[-1] ratio = (len_sum - mindist)/len_sum return ratio 基于词频向量的相似度计算
余弦相似度
还是老规矩将两个字符串转换成数组或者说是向量,ok。
如果两个向量的夹角为0,说明 a 向量和 b 向量相等。考虑向量的概念,结合向量的余弦定理。
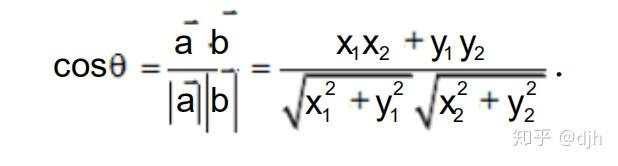
a = np.array(vec_a)
b = np.array(vec_b)
print(a)
print(b)
ret = np.sum(a*b) / (np.sqrt(np.sum(a ** 2)) * np.sqrt(np.sum(b ** 2)))
print('分数:'+str(ret))
return ret 代码如上,至于你用什么把文本转换成向量有多种方法。
以下是大体的结果
句子:
你好我是英国人<--->你好我是中国
各种算法结果:
Jaccard 0.6
LCS 0.8333333333333334
最小可编辑距离 0.8461538461538461
余弦相似度 0.75
其他
关注我不迷路,目前只是一些入门级的小文章,后面会有AI系列文章推送。
https://github.com/yazone/ai_learning_path更多嵌入式AI技术相关内容请关注嵌入式AI专栏。

