
本文转自:知乎
作者:djh
一、模型简介
据说百度出了个比较好的nlp框架,最近研究了下。
源码地址:
https://github.com/PaddlePaddle/LARK/tree/develop/ERNIEgithub.com
这个ERNIE,据说比bert好。
ERNIE 通过建模海量数据中的词、实体及实体关系,学习真实世界的语义知识。相较于 BERT 学习原始语言信号,ERNIE 直接对先验语义知识单元进行建模,增强了模型语义表示能力。
这里我们举个例子:
Learnt by BERT :哈 [mask] 滨是 [mask] 龙江的省会,[mask] 际冰 [mask] 文化名城。
Learnt by ERNIE:[mask] [mask] [mask] 是黑龙江的省会,国际 [mask] [mask] 文化名城。
在 BERT 模型中,我们通过『哈』与『滨』的局部共现,即可判断出『尔』字,模型没有学习与『哈尔滨』相关的任何知识。而 ERNIE 通过学习词与实体的表达,使模型能够建模出『哈尔滨』与『黑龙江』的关系,学到『哈尔滨』是 『黑龙江』的省会以及『哈尔滨』是个冰雪城市。
训练数据方面,除百科类、资讯类中文语料外,ERNIE 还引入了论坛对话类数据,利用 DLM(Dialogue Language Model)建模 Query-Response 对话结构,将对话 Pair 对作为输入,引入 Dialogue Embedding 标识对话的角色,利用 Dialogue Response Loss 学习对话的隐式关系,进一步提升模型的语义表示能力。
我们在自然语言推断,语义相似度,命名实体识别,情感分析,问答匹配 5 个公开的中文数据集合上进行了效果验证,ERNIE模型相较 BERT 取得了更好的效果(实际没有这么理想)。
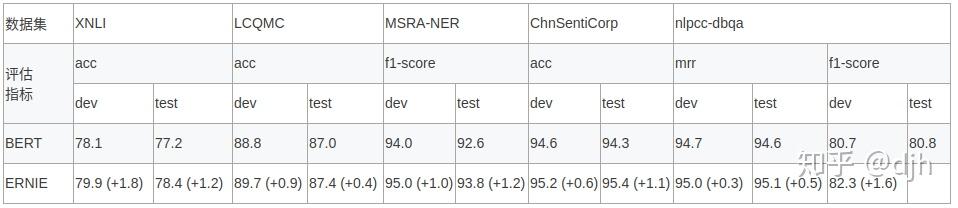
二、用ERNIE做下游的任务
OK,我们只想用这个ERNIE做下游的任务,如何做。
1、下载模型:
下载百度训练好的上游模型
预训练模型下载 https://ernie.bj.bcebos.com/ERNIE\_stable.tgz
2、准好你自己的训练数据
数据格式是tsv格式,大概如下
label text\_a
0 当当网名不符实,订货多日不见送货,询问客服只会推托,..
0 XP的驱动不好找!我的17号提的货,现在就降价了100元,而且还送杀毒软件!
1 <荐书> 推荐所有喜欢<红楼>的红迷们一定要收藏这本书,要知道当年我...
训练集测试集等存放成一个目录下,如下
trainData/dev.tsv
trainData/test.tsv
trainData/train.tsv 3、然后写一个脚本开始训练。
set -eux
python -u run_classifier.py \
--use_cuda true \
--verbose true \
--do_train true \
--do_val true \
--do_test true \
--batch_size 6 \
--init_pretraining_params kemu/params \
--train_set kemu/trainData/train.tsv \
--dev_set kemu/trainData/dev.tsv \
--test_set kemu/trainData/test.tsv \
--vocab_path config/vocab.txt \
--checkpoints ./checkpoints \
--save_steps 1000 \
--weight_decay 0.01 \
--warmup_proportion 0.0 \
--validation_steps 100 \
--epoch 10 \
--max_seq_len 512 \
--ernie_config_path config/ernie_config.json \
--learning_rate 5e-5 \
--skip_steps 10 \
--num_iteration_per_drop_scope 1 \
--num_labels 9 \
--random_seed 1
注意这个几个参数
--init\_pretraining\_params test/params \ 这个是你下载的 百度预训练模型地址,
--train\_set test/trainData/train.tsv \ 这个是你的训练集 测试集等等。
--dev\_set test/trainData/dev.tsv \
--test\_set test/trainData/test.tsv \
就可以进行训练了。
三、分析
ERNIE 模型。和bert模型比较。
在网络结构上是根本没有区别的。只不过ERNIE 模型在与训练的时候,采用的方式和bert不同,采用更加人性话,更加靠近中文的方式处理的。
所以在某些中文领域或许会更有优势。但是这个处理百度又没有公开只是给了编码好了的与训练数据。
请大家批评指正
其他
关注我不迷路,目前只是一些入门级的小文章,后面会有AI系列文章推送。
https://github.com/yazone/ai_learning_path更多嵌入式AI技术相关内容请关注嵌入式AI专栏。

