
转载于:知乎
作者:于璠
OpenAI在今年一月份发布了120亿参数规模的DALL-E模型,能够根据一段文本描述生成效果惊人的图像,不管多么天马行空的文字都能应对,被称之为“图像版的GPT-3“。而在最近,清华大学公布了中文文本生成图像的新框架——CogView,除了支持中文语言外,在多项性能指标上超越DALL-E,且能通过finetune适应多种不同的下游任务。CogView的论文、代码及Demo网站皆已公布,下面让我们来一探究竟吧!
· 代码:
https://github.com/THUDM/CogViewgithub.com
· demo:
论文链接:
https://arxiv.org/abs/2105.1329arxiv.org
背景
文本图像生成(text-to-image)生成任务最早可以追溯到深度生成模型DRAW[1]的提出,而在之后很长一段时间里被GAN(Generative Adversarial Nets)类的方法所统治。虽然GAN天生对于生成类的任务有着很好的契合度,但是基于GAN的方法只在简单的或者特定领域中的数据集上取得了不错的效果,对于诸如MS COCO这类复杂且没有限定领域的数据集,其表现只能说差强人意。
近几年随着NLP领域“自回归“(auto-regressive)模型的崛起,以GPT(Generative Pre-Training)[2]为代表的大规模预训练语言模型在各个语言类任务中展现出来惊人的实力。同时,这类自回归模型纷纷开始涉足CV类的任务,但是现实世界中的图像往往具有数以百万级的像素,如果没有合适的特征压缩方法,单靠语言模型是难以处理的,而VQ-VAE[3]恰好就是那个“合适”的图像特征压缩方法。
VQ-VAE同VAE(Variational Auto-Encoder)最大的区别就在于,其隐变量 zz 的每一维都是离散的整数,这步离散化的操作是通过VQ-VAE结构中的embedding table实现的:具体操作就是将图片经过Encoder处理后得到的特征向量通过“查表操作“找到embedding table中与其最相近的一个embedding,并用该embedding的index进行离散化的表示。相比于直接进行降采样,VQ-VAE的离散化操作失真度低,同时保留了像素间的关系。
CogView的结构
CogView整体的算法框架与DALL-E相比更为简洁,文本部分的token转换已经十分成熟,下文不再做进一步介绍;图像则是通过一个离散化的AE(Auto-Encoder)转换为token。文本token和图像token拼接到一起之后输入到GPT模型中生成图像。最后在处理文本图像生成类任务时,模型会通过计算一个Caption Score对生成图像进行排序,从而选择与文本最为匹配的图像作为结果。
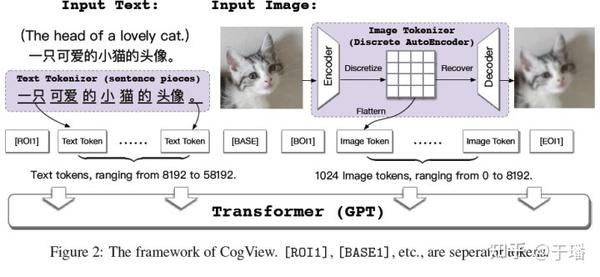
Image Tokenizer
前文提到CogView通过一个离散化的AE作为图像分词器,该结构同VQ-VAE或者是DALL-E中采用的d-VAE[4]的阶段一结构十分相似。具体而言,图像分词器首先通过Encoder 将H*W*3的图像转换为h*w*d特征向量,之后特征向量中每一个长度为d的向量都会通过“查表操作”转化为一个embedding的index,最终变为 h*w的量化向量。而Decoder 的作用是将量化后的特征重构为较为模糊的原始图像。整个Image Tokenizer的训练采用了VQ-VAE中的模式,这里不做过多介绍。
Transformer
如图1所示,CogView的骨架网络是一个48层的GPT网络,隐层大小为2560,attention头部数量为40,总计达到了4亿的参数量。输入格式方面,利用4个分隔符来作为文本token和图像token的边界,文本token数量固定为1088,过长或者过短的情况下需要通过clip和pad的操作进行处理;图像token数量设置为1024。
训练策略
大规模的文本图像生成预训练任务通常会由于训练数据之间的差异而变得不稳定,通常表现为Loss NaN和梯度弥散,CogView分别提出了PB-Relax(Precision Bottleneck Relaxation)和Sandwich-LN(Sandwich LayerNorm)来进行应对。
PB-Relax
作者发现预训练过程中的数值溢出主要发生在Transformer的瓶颈层的最后一个LayerNorm或者attention处。经过进一步探索发现,网络深处的层输出过大会导致后续的LayerNorm溢出,于是利用了LayerNorm的如下性质对输入进行缩放:
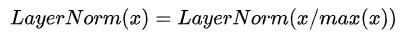
同时,attention分数的值过大也会导致数值溢出,这里利用了对 softmax的输入加上或者减去一个常数对于结果没有影响的性质,即:
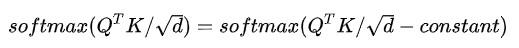
通过上述公式,attention层的计算改为如下公式:
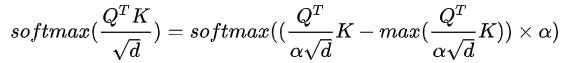
上述公式中的 alpha是一个非常大的数,通过除以 alpha 可以将attention分数的数值进行缩放,避免数值溢出。
Sandwich-LN
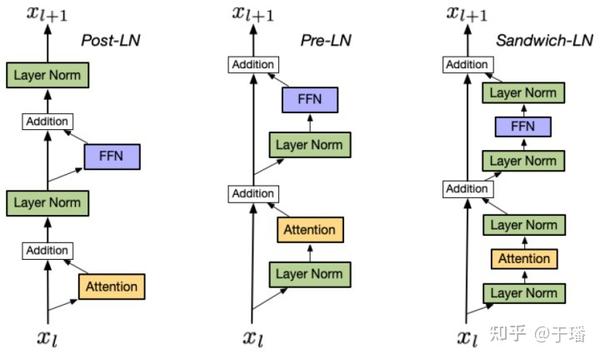
顾名思义,Sandwich-LN就是堆叠成“三明治”形状的Layer Norm组合,CogView对Transformer的结构进行了改进,在残差分支处的FFN(全连接层)和attention头的前后各加上了一个Layer Norm来对中间特征进行正则。实验证明,Sandwich-LN相较于早期提出的Post-LN和Pre-LN[5]能使训练过程变得更稳定。
多样化的能力
CogView训练完成之后,可以通过进一步的finetune来适应不同的下游任务,例如风格迁移,超分辨率,图像描述和排名,以及时装设计等等。
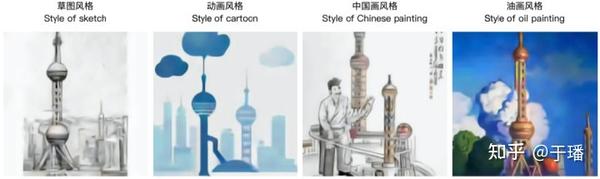
值得一提的是,CogView还提出了一种用来评估图像和文本之间关联度的指标Caption Score(CapS)来作为文本图像生成任务中对图像进行排名的依据。也正是通过CapS,CogView不像DALL-E一样需要通过外接CLIP模型[6]才能对生成的图像进行排序。
公开数据集表现
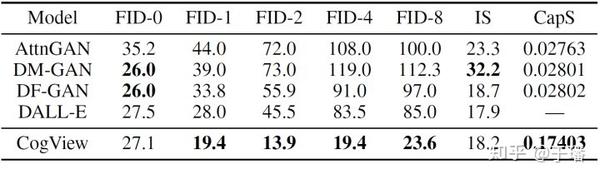
如上图所示,CogView在MS COCO的文本图像生成任务上不管是FID(Fréchet Inception Distance)指标还是IS指标都要优于DALL-E,而模型的总参数量仅为DALL-E的1/3。
总结
作为首个支持中文的VQ-VAE+Transformer的文本图像生成算法框架,CogView交出了一份令人满意的答卷。不管是在benchmark表现,通过finetune所能支持下游任务的种类,还是算法框架的简洁度上,CogView都要更胜DALL-E一筹。同时,从text-to-image领域的发展趋势看,“大规模,大数据,多模态“的AI发展浪潮迟早会席卷到各个领域。AI的未来,可能将会是一个拼数据、拼算力的战场。
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

