
本文转自:知乎
作者:金雪锋
本次小伙伴带来《A Distributed Graph-Theoretic Framework for Automatic Parallelization in Multi-core Systems》论文分析。
论文作者:Guixiang Ma(Intel), Yao Xiao(USC), Theodore L. Willke(Intel), Nesreen K. Ahmed(Intel), Shahin Nazarian(USC), Paul Bogdan(USC)
论文链接:https://proceedings.mlsys.org/paper/2021/file/a5e00132373a7031000fd987a3c9f87b-Paper.pdf
论文talk:
背景与动机
一方面越来越强的多核处理器被设计出来,另一方面机器学习和大数据分析类任务也越来越复杂。如何将复杂的应用自动化地部署到多核处理器上,进而发挥出硬件的能力成为了关键问题。本文关注于单台服务器上多处理器的并行,即如何将编译得到的计算图分割成多个clusters,进而将clusters映射到处理器上,以期得到更优的并行执行效率。
目标
本工作考虑的是指令级别(instruction-level)的并行粒度,即将不同的指令分配到不同的处理器上执行。经过多种类型的应用分析得到,发现编译后的LLVM IR图具有power-law degree distribution特性,也就是:计算图中的只有少数几个点的度数较高,其余点的度数很少。因此,本工作的目标是针对这种power-law degree distribution graph切分图,使得切分后的各个cluster (instructions的集合)拥有balanced workloads,同时跨cluster之间的通信少。
问题建模及解决方案

如上图所示,提出的方案大致分三个步骤:1) 构造 LLVM IR graph;2) 图切分;3) 切分后的clusters映射到多处理器上。
- 构造LLVM IR graph (V, E, W),其中V表示点的集合,每个点表示一个指令(instruction);E是边的集合,每条表示两条指令的数据依赖关系;W是边的weight,表示的是每条边对应的数据传输所需的内存操作的时间。
如何从IR文件中构造图呢?本工作从前端编译器编译的IR图出发,首先在IR文件中增加一些输出打印信息,用于测量内存操作的时间,进而将IR文件放到后端执行以得到每个内存操作的真实时间。图当中的边是由分析IR文件中分析指令的源寄存器和目的寄存器地址得来的: 如本指令从寄存器A中读数据,而上一条指令向寄存器A找那个写数据,那么就将这两条指令对应的点创建一条边。下图展现的是图构造的过程。
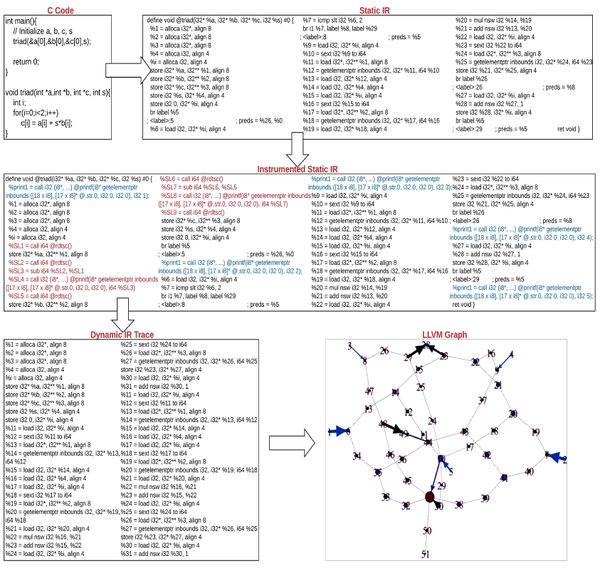
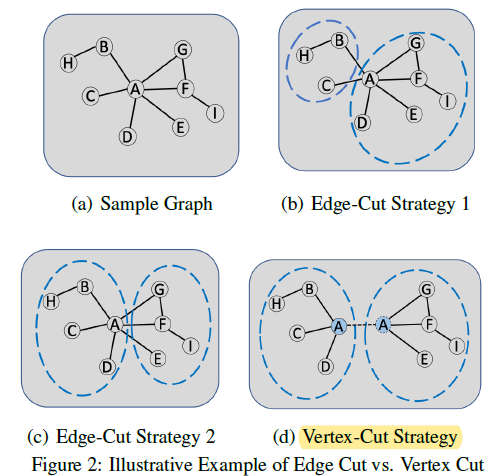
- 图切分。在构造好graph后,选择合适的图切分方式是核心问题。这时,有两种基本的图切分方式,边切分(Edge-Cut)和点切分(Vertex-Cut)。如下图所示,边切分中跨cluster的边会产生通信,而点切分中被切分的点在不同cluster中都有replica,通信来源于replica之间的同步信息。由于本工作的目标是最小化跨cluster的通信,且保持各个cluster之间的workload balanced,点切分相比于边切分是更好的方式。
选定点切分的方式后,问题的目标就变成了如下优化问题,其中A(v)表示的是每个点v被切分到的cluster的集合,M(e) = m表示的是边e被分配到了cluster m中。公式(2)表示的是跨cluster的通信最小化。公式(3)表示的是每个cluster分得的边的权重的和(workload)是balanced,其中lambda是imbalance factor。
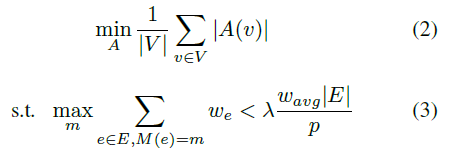
PowerGraph[1]算法将边分配到各个cluster中去,同时平衡各个cluster的边的数量;Libra[2]针对高度数的点附着的边优先处理。这两个工作都是针对非weighted graph的,本工作在PowerGraph和Libra的基础上给出了weighted graph的切分方式,分别称作Weighted PowerGraph和Weighted Libra;进一步,在分配边时,考虑到(3)的约束条件,又有Weighted-balanced PowerGraph和Weighted-balanced Libra。
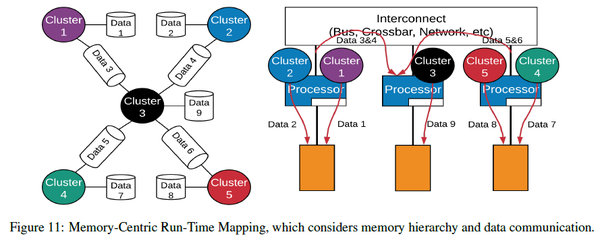
- Cluster映射。将切分好的cluster映射到处理器上,需要考虑多处理器的拓扑连接关系。本工作考虑的是NUMA架构:处理器对local memory有较快的访问速度,而对其他memory的访问速度较慢。为了获得较优的并行加速,同时考虑到跨cluster的通信和资源利用率,本工作提出了cluster到处理器映射的几个原则:多个cluster若操作于同一数据结构,那么它们应该被映射到同一核上;有通信的clusters应该被映射到相邻的处理器上;相互独立的clusters可以被映射到不同区域的处理器上;同时,为了避免很多clusters被映射到同一处理器上,给每个处理器设置了cluster数上限。下图是cluster映射的一个例子。
实验
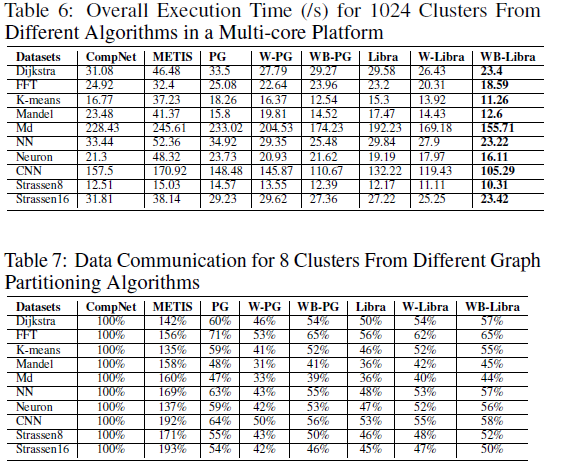
本工作使用gem5模拟器实验,模拟了NUMA架构的不同配置。应用用例包括:图计算,傅里叶变换,CNN,矩阵计算等。衡量指标包括执行时间,通信代价等。提出的四种算法都优于SOTA;在大多数场景中,Weighted-balanced Libra是表现最好的算法。下表是节选的两个实验结果。
总结及comments
本文考虑了复杂应用在多处理器上自动并行的问题,提出了针对LLVM IR graph切分的指令级并行的方案。依赖于程序的profiling获取数据操作的时间信息,进而对图进行点切分,在已有算法的基础上提出了针对weighted graph的切分方式,在模拟实验中验证了并行性能的提升。
Comments:1) 本工作并未在真实硬件环境上验证;2) 文章并未讨论关于多replica同步机制的问题,同步机制依赖于硬件的架构;3) 文章理论分析的(1-1/e)-approximation并不是提出的算法的近似度,而是naïve greedy algorithm针对submodular function with cardinality constraint,而本文要解决的问题与submodular function with cardinality constraint问题不同,导致(1-1/e)近似度在这里并不适用;4) 本文的基于profiling的方案在指令级别的图切分方式中有独特的优势,因为指令级别的数据操作涉及到的寄存器的读写时间相对稳定,而在非指令级图切分的方式中,profiling方案容易产生variance过大的问题,不稳定。同时,本文提到的点切分的方式,在非指令级的切分是否适用需视情况而定,因为replica的同步方式会很不一样。
Reference
[1] Joseph E. Gonzalez, Yucheng Low, Haijie Gu, Danny Bickson, Carlos Guestrin:
PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs. _OSDI 2012_.
[2] Cong Xie, Ling Yan, Wu-Jun Li, Zhihua Zhang: Distributed Power-law Graph Computing: Theoretical and Empirical Analysis. _NIPS 2014_.
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

