
首发:知乎
作者:djh
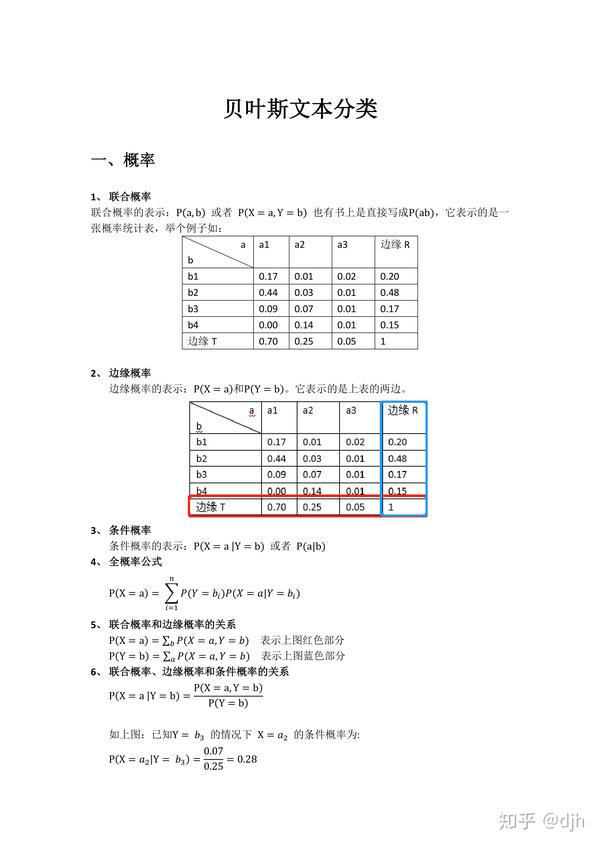



《NLP汉语自然语言处理原理与实践(郑捷著)》书中的算法,用是没什么用的,主要是理解。
# -*- coding: utf-8 -*-
import sys
import os
import numpy as np
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him','my'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1 is abusive, 0 not
return postingList,classVec
# 读取文件
def readfile(path):
fp = open(path,"rb")
content = fp.read()
fp.close()
return content
'''
#计算分类精度:
def metrics_result(actual,predict):
print '精度:{0:.3f}'.format(metrics.precision_score(actual,predict))
print '召回:{0:0.3f}'.format(metrics.recall_score(actual,predict))
print 'f1-score:{0:.3f}'.format(metrics.f1_score(actual,predict))
'''
#读取bunch对象
def readbunchobj(path):
file_obj = open(path, "rb")
bunch = pickle.load(file_obj)
file_obj.close()
return bunch
#写入bunch对象
def writebunchobj(path,bunchobj):
file_obj = open(path, "wb")
pickle.dump(bunchobj,file_obj)
file_obj.close()
class NBayes(object):
def __init__(self):
self.vocabulary = [] # 词典
self.idf=0 # 词典的idf权值向量
self.tf=0 # 训练集的权值矩阵
self.tdm=0 # P(x|yi)
self.Pcates = {} # P(yi)--是个类别字典
self.labels=[] # 对应每个文本的分类,是个外部导入的列表
self.doclength = 0 # 训练集文本数
self.vocablen = 0 # 词典词长
self.testset = 0 # 测试集
# 加载训练集并生成词典,以及tf, idf值
def train_set(self,trainset,classVec):
self.cate_prob(classVec) # 计算每个分类在数据集中的概率:P(yi)
self.doclength = len(trainset)
tempset = set()
[tempset.add(word) for doc in trainset for word in doc ] # 生成词典
self.vocabulary = list(tempset)
self.vocablen = len(self.vocabulary)
self.calc_wordfreq(trainset)
# self.calc_tfidf(trainset) # 生成tf-idf权值
self.build_tdm() # 按分类累计向量空间的每维值:P(x|yi)
# 生成 tf-idf
def calc_tfidf(self,trainset):
self.idf = np.zeros([1,self.vocablen])
self.tf = np.zeros([self.doclength,self.vocablen])
for indx in xrange(self.doclength):
for word in trainset[indx]:
self.tf[indx,self.vocabulary.index(word)] +=1
# 消除不同句长导致的偏差
self.tf[indx] = self.tf[indx]/float(len(trainset[indx]))
for signleword in set(trainset[indx]):
self.idf[0,self.vocabulary.index(signleword)] +=1
self.idf = np.log(float(self.doclength)/self.idf)
self.tf = np.multiply(self.tf,self.idf) # 矩阵与向量的点乘
# 生成普通的词频向量
def calc_wordfreq(self,trainset):
self.idf = np.zeros([1,self.vocablen]) # 1*词典数
self.tf = np.zeros([self.doclength,self.vocablen]) # 训练集文件数*词典数
for indx in xrange(self.doclength): # 遍历所有的文本
for word in trainset[indx]: # 遍历文本中的每个词
self.tf[indx,self.vocabulary.index(word)] +=1 # 找到文本的词在字典中的位置+1
for signleword in set(trainset[indx]):
self.idf[0,self.vocabulary.index(signleword)] +=1
# 计算每个分类在数据集中的概率:P(yi)
def cate_prob(self,classVec):
self.labels = classVec
labeltemps = set(self.labels) # 获取全部分类
for labeltemp in labeltemps:
# 统计列表中重复的值:self.labels.count(labeltemp)
self.Pcates[labeltemp] = float(self.labels.count(labeltemp))/float(len(self.labels))
#按分类累计向量空间的每维值:P(x|yi)
def build_tdm(self):
self.tdm = np.zeros([len(self.Pcates),self.vocablen]) #类别行*词典列
sumlist = np.zeros([len(self.Pcates),1]) # 统计每个分类的总值
for indx in xrange(self.doclength):
self.tdm[self.labels[indx]] += self.tf[indx] # 将同一类别的词向量空间值加总
sumlist[self.labels[indx]]= np.sum(self.tdm[self.labels[indx]]) # 统计每个分类的总值--是个标量
self.tdm = self.tdm/sumlist # P(x|yi)
# 测试集映射到当前词典
def map2vocab(self,testdata):
self.testset = np.zeros([1,self.vocablen])
for word in testdata:
self.testset[0,self.vocabulary.index(word)] +=1
# 输出分类类别
def predict(self,testset):
if np.shape(testset)[1] != self.vocablen:
print "输入错误"
exit(0)
predvalue = 0
predclass = ""
for tdm_vect,keyclass in zip(self.tdm,self.Pcates):
# P(x|yi)P(yi)
temp = np.sum(testset*tdm_vect*self.Pcates[keyclass])
if temp > predvalue:
predvalue = temp
predclass = keyclass
return predclass
主程序
import sys
import os
import time
from numpy import *
import numpy as np
from Nbayes_lib import *
# 配置utf-8输出环境
reload(sys)
sys.setdefaultencoding('utf-8')
dataSet,listClasses = loadDataSet()
nb = NBayes()
nb.train_set(dataSet,listClasses)
nb.map2vocab(dataSet[3])
print nb.predict(nb.testset)
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

