
来自华为诺亚方舟实验室,北京大学以及悉尼大学的研究者们提出了一种底层视觉任务上的预训练Transformer模型IPT,相比于传统的卷积神经网络,IPT模型在超分辨率、去噪、去雨等多项任务上取得了SOTA表现,并取得了大幅提升。

论文链接:
开源地址:
Github:
huawei-noah/Pretrained-IPTgithub.com
Mindspore:
[MindSpore/mindsporegitee.com ](https://link.zhihu.com/?targe...
](https://link.zhihu.com/?targe...
简介
深度卷积神经网络(CNN)在许多视觉任务中取得了很大成功,然而,近期有大量研究发现,只要有足够的预训练数据,NLP任务的Transformer模型在视觉任务上也可以取得很好的效果,例如谷歌提出的ViT模型在图像分类ImageNet数据集上取得了SOTA的结果,以及facebook提出了detr用于视觉检测任务,然而,这些论文主要聚焦于Transformer模型在高层语义计算机视觉任务上的研究。
在CVPR 2021的这篇论文中,我们将会研究Transformer模型在底层计算机视觉任务上的应用。我们提出的IPT模型具有和GPT-3等预训练模型相似的能力:即一个预训练模型处理多个不同任务,在超分、去噪、去雨等多个底层视觉任务中表现良好。我们首先介绍IPT模型的结构。
用于底层视觉任务的Transformer
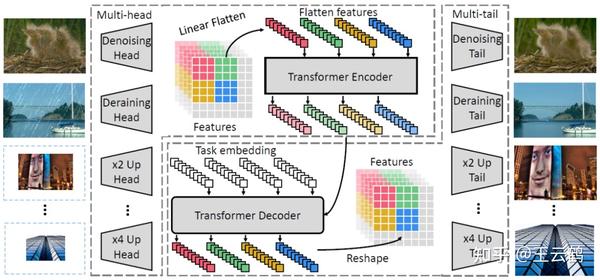
上图是IPT模型的具体结构,可以看到,IPT模型由多个头和多个尾构成,头和尾的具体结构由卷积层构成,不同的头和尾可以处理不同的任务,而他们共享同一个transformer的身体,从而在可以处理不同任务的情况下,提取更加具有泛化性的特征。
其中transformer身体的部分由encoder和decoder构成,encoder负责提取图像中的信息,而decoder来重构高质量的图像,这和高层视觉任务中常用的transformer结构有着很大的不同,在高层视觉任务中,由于它们只需要提取图像中的信息进行识别,它们的模型只具有encoder结构,而我们需要将图像进行重构,所以更需要decoder结构。
由于transformer的结构的输入是NLP的单词序列,我们无法直接将图像数据作为输入,所以,需要对图像进行切块后输入encoder,最后decoder的输出同样也是序列,我们需要将其重新reshape回图片进行输出。
底层视觉任务的预训练
由于Transformer模型相比CNN具有更多的参数量,所以常常需要更多的训练数据来达到更好的效果。在分类、检测等任务的预训练已经十分成熟,然而在底层视觉任务的预训练仍然未被探究。
针对这个问题,我们提出了使用ImageNet数据来对模型进行预训练。具体地,ImageNet数据集中包含了大量具有高质量的清晰图像,我们将这些清晰图像进行降质操作,例如,对于超分任务,我们将其图片进行下采样,对于去噪、去雨任务,我们人为的对他进行加入雨痕、噪声等操作。这样我们就可以得到大量的人造地高质量-低质量图像对,从而对我们的IPT模型进行训练。
为了得到更加具有泛化能力的预训练模型,我们对多个任务的训练数据进行同时训练,配合IPT模型的多头多尾结构,使得一个模型可以处理多个任务,我们使用监督的损失函数训练图像对:
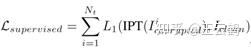
此外,为了提升模型在未预训练的任务上的性能(如不同倍率的超分辨率、不同噪声强度的去噪任务),我们根据特征块之间的相关性引入了对比学习方法作为自监督损失函数。具体来说,来自于同一图像的特征块之间的特征应当相互接近,来自于不同图像的特征块应当远离。这一自监督损失函数如下所示:
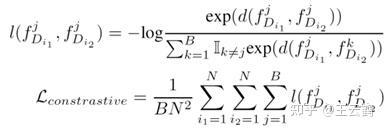
最后,经过预训练的 IPT 模型,只需要在特定任务的数据集上进行微调,即可在此任务上达到很好的效果。在微调阶段,只有特定任务所对应的头尾结构以及 Transformer 模块被激活训练,与此任务无关的头尾模块将被抛去。
实验结果
为了证明 IPT 的有效性,我们在多种底层视觉任务上测试了模型效果,包括 2 倍、3 倍和 4 倍的超分辨率任务、两种强度的去噪任务以及去雨任务、去模糊任务。每个具体任务所采用的 IPT 模型均为同一个预训练模型在特定任务上微调得到的。另外,研究者还做了一系列对照实验来确定 Transformer、对比学习损失函数等不同模块的重要性。
首先对于超分辨率任务,我们报告了在 Set5、Set14、B100 以及 Urban100 四个数据集上的结果,如下表所示。
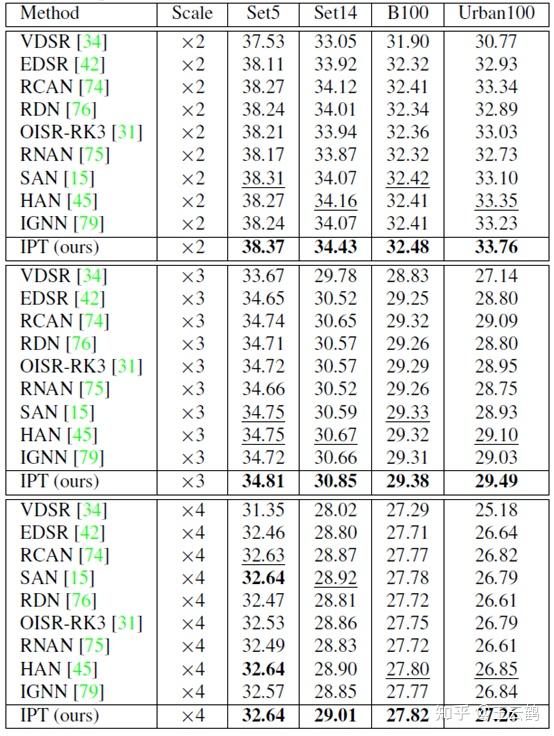
表 1:超分辨率任务实验结果
可以看出,IPT 模型在所有设定下均取得了最好的结果。尤其是在 Urban100 数据集上,对比当前最好的超分辨率算法,IPT 模型展现出了大幅度的优势,之前的算法相对提升基本都在0.1dB以内,而我们的IPT模型直接提升了0.4-0.5dB,是一个巨大的提升。
同样,在去噪和去雨任务上,IPT 模型也展现出了类似的性能。
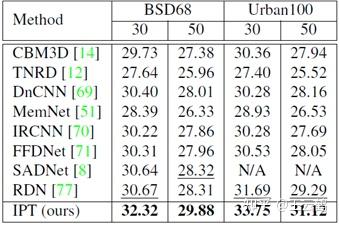
表 2:去噪任务实验结果

表 3:去雨任务实验结果
除了量化结果以外,我们发现在视觉效果上IPT模型也有着巨大的提升


随后,我们研究了IPT模型在没有预训练的任务上的性能,在表 4 中,对于噪声强度为 10 和 70 的设定下(预训练为 20 和 50),IPT 模型依旧展现出巨大的优势,展示了预训练模型良好的泛化性。
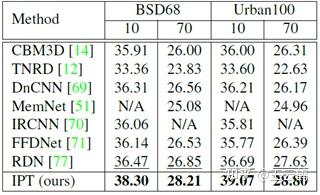
表 4:未见噪声强度实验结果
我们还在去模糊任务上也使用了IPT模型,值得注意的是,在预训练时我们没有进行去模糊任务的预训练,然而IPT模型仍然在这个任务上取得了SOTA的结果。

表 5:去模糊任务实验结果
最后,为了进一步验证我们的IPT模型本身的能力,我们将CNN模型也采用同样的预训练,并对比精度,我们发现,IPT模型在训练数据较少时结果较差,但是当训练数据足够时,可以大幅超越CNN模型,表现了transformer模型在底层视觉任务的潜力。
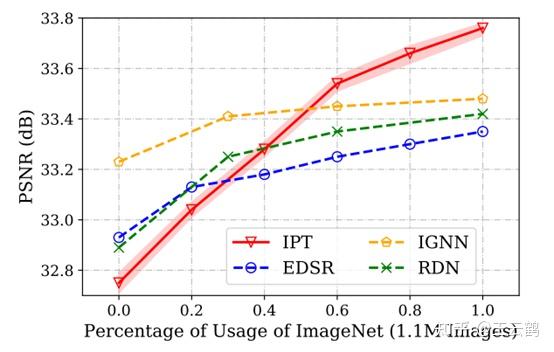
开源代码分析
IPT相应的代码和预训练模型已经开源在github和mindspore,我们在这里对开源代码做一个简单的解读,方便大家使用。
Github开源的是pytorch版本的测试代码:
huawei-noah/Pretrained-IPTgithub.com
首先需要安装对应的包才可以使用,包括:python 3、pytorch >= 1.4.0、torchvision。此外,还要下载对应的数据集和预训练模型(都已在github中提供链接)。
开源代码中包含多个文件和文件夹,我们接下来仔细解读每个文件的作用。
首先是option.py,其中定义了需要使用的参数:
https://github.com/huawei-noah/Pretrained-IPT/blob/main/option.py
对于不同的任务,我们需要使用不同的参数进行测试,同时在这里也进行了对数据路径和模型路径的指定。
例如我们需要测试srx2的任务,那么执行代码为:
python main.py --dir_data $DATA_PATH --pretrain $MODEL_PATH --data_test Set5+Set14+B100+Urban100 --scale $SCALE其中DATA\_PATH就是下载的数据集的存放位置,MODEL\_PATH是下载的预训练模型的位置,--data\_test参数代表了需要测试的数据集,SCALE对于srx2任务设置为2,代表输出图片是输入图片的2倍。
测试代码的运行文件为main.py,其中调用option.py进行参数设置,再调用model/ipt.py定义了模型,之后调用了trainer.py进行测试:
https://github.com/huawei-noah/Pretrained-IPT/blob/main/main.py
model/ipt.py中包含了我们模型的具体结构:
https://github.com/huawei-noah/Pretrained-IPT/blob/main/model/ipt.py

可以清晰地看到,我们的模型包括多头多尾结构,头通过self.head定义,尾通过self.tail定义,而transformer的body部分由self.body定义,我们再具体看VisionTrasnformer这个类,可以发现它主要包含了TransformerEncoder和TransformerDecoder这两个部分组成,其中的定义和论文中的一样。
定义完模型之后,trainer.py就可以对模型进行inference测试:
https://github.com/huawei-noah/Pretrained-IPT/blob/main/trainer.py

这是去雨部分的代码的例子,可以看到简单的将带有雨的图片输入ipt模型即可输出结果,最后和ground truth计算PSNR。
计算PSNR的代码包含在utility.py中:
https://github.com/huawei-noah/Pretrained-IPT/blob/main/utility.py
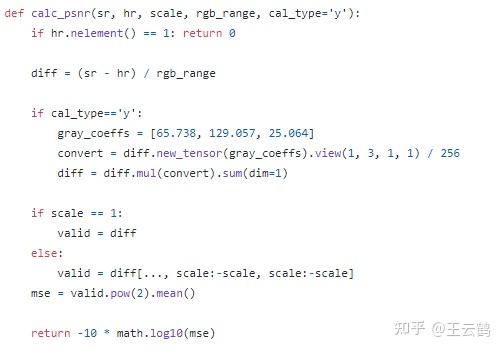
在trainer.py中,需要读取dataloader得到数据,具体代码可以参考data/srdata.py:
https://github.com/huawei-noah/Pretrained-IPT/blob/main/data/srdata.py
总结来说,模型定义在model/ipt.py中,数据读取定义在data/srdata.py中,trainer文件通过读取模型和数据来进行测试,最后main.py通过option.py中的参数执行trainer.py。如果想修改代码来对自己的数据集进行测试,只需要修改data/srdata.py即可轻松完成。
在Mindspore官网我们开源了IPT的训练代码:
https://gitee.com/mindspore/mindspore/tree/master/model\_zoo/research/cv/IPT
相关代码结构如下:

IPT模型文件与pytorch版本相似。
我们将模型的结构,以及超参数的设置汇总到了相关代码仓的/src文件夹下,我们正在/scripts文件夹中同时提供了多卡分布式训练的启动脚本。
模型预训练运行命令如下:
python train.py --distribute --imagenet 1 --batch_size 64 --lr 5e-5 --scale 2+3+4+1+1+1 --alltask --react --model vtip --num_queries 6 --chop_new --num_layers 4 --data_train imagenet --dir_data $DATA_PATH --derain --save $SAVE_PATH或者执行如下运行脚本:
sh scripts/run_distributed.sh RANK_TABLE_FILE DATA_PATH以超分任务为例,下游任务finetune命令为:
python train_finetune.py --distribute --imagenet 0 --batch_size 64 --lr 2e-5 --scale 2+3+4+1+1+1 --model vtip --num_queries 6 --chop_new --num_layers 4 --task_id $TASK_ID --dir_data $DATA_PATH --pth_path $MODEL --epochs 50其中TASK\_ID代表要finetune的任务ID,0, 1, 2分别代表2x, 3x, 4x超分任务。
以超分任务为例,精度评估命令为:
python eval.py --dir_data $DATA_PATH --data_test $DATA_TEST --test_only --ext img --pth_path $MODEL --task_id $TASK_ID --scale $SCALE或者通过下面脚本对所有任务进行评估:
sh scripts/run_eval.sh DATA_PATH DATA_TEST MODEL TASK_ID
推荐阅读
文章首发微信公众号,更多深度模型压缩相关的文章请关注深度学习压缩模型论文专栏。

