
华为诺亚研究员联合中科院深圳先进院、悉尼大学提出加法网络极简硬件架构,相比乘法网络,加法网络硬件电路面积节省67.6%-71.4%,功耗降低47.85%-77.9%。论文提出了一个新型的加法网络量化方法,8bit/16bit量化无损。同时,针对加法网络的特性,设计了一种极简硬件架构,能够大幅降低电路面积和功耗,性能远超乘法网络、忆阻器、移位网络等计算架构。论文链接:
AdderNet and its Minimalist Hardware Design for Energy-Efficient Artificial Intelligence
引言
加法网络是华为诺亚提出的一种新型神经网络计算模式,其摒弃了复杂度高的乘法,只用加法来完成卷积计算。加法网络在降低硬件资源和功耗的同时,能够保持和CNN一样的识别效果,已经在图像识别、底层视觉等任务发挥价值,相关工作可以参考:
加法网络首提论文:
加法网络精度首次超越CNN:
王云鹤:加法网络再突破 | NeurIPS 2020 Spotlight
加法网络用于底层视觉:
AdderSR: Towards Energy Efficient Image Super-Resolutionarxiv.org
鉴于加法网络优越的理论性能,研究者提出一种极简硬件架构来对加法网络进行实际功耗验证。本文就设计了小型网络专用电路和大型网络通用电路架构,在FPGA上充分验证了加法网络的优越性,硬件电路面积节省67.6%-71.4%,功耗降低47.85%-77.9%。
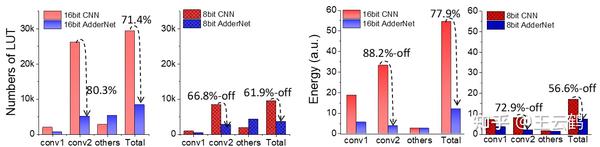
图1 加法网络和CNN电路面积/功耗对比
方法&实验
不同计算模式对比(加法网络、乘法CNN、忆阻器等)
在深度卷积神经网络中,卷积层通过计算滤波器和输入之间的相似性,使用一系列卷积核(滤波器)来进行特征的局部连接。我们分析了5种经典卷积计算模式:乘法网络、移位网络、基于忆阻器的网络、二值网络、加法网络。
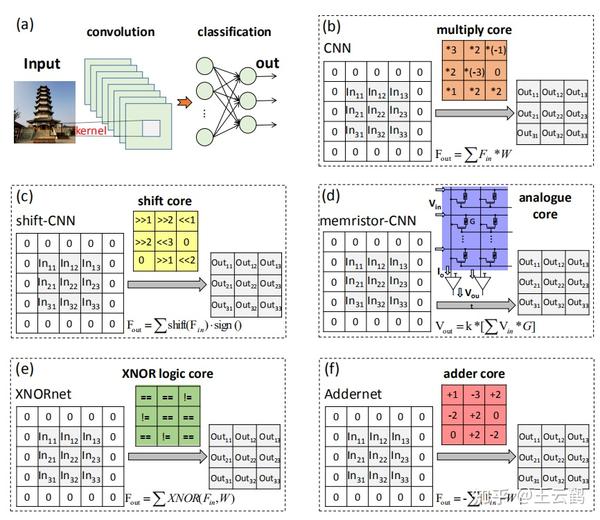
图2: (a) 广义上的卷积操作 (b) 乘法卷积核 (c) 移位卷积核 (d) 忆阻器核 (e) 二值卷积核 (f) 加法卷积核
同时,不同计算模式的实际效果也做了对比。在实际图像识别效果上,加法网络和乘法网络最具竞争力。在功耗上二值网络、忆阻器、加法网络相对较低。综合考虑识别效果和功耗,加法网络是最优选择。
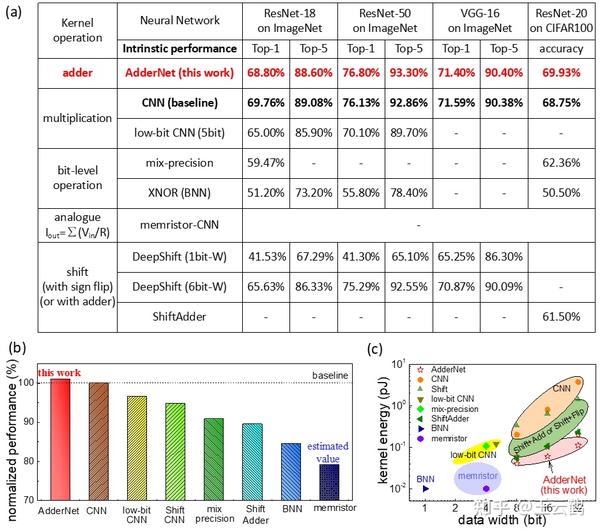
图3 (a)不同核操作的识别精度,其中CNN和我们的AdderNet在所有的神经网络中表现出最好的性能。注意,目前最大的忆阻器CNN模型只包含2个卷积层,因此比较表上没有可用的数据。(b) 不同内核方法的标准化性能,CNN作为基线。(c) 不同核操作的能耗。
量化加法网络
量化是一种重要的模型压缩技术,它用较低的比特值来表示权重和特征。为了在高精度和低功耗之间取得平衡,通常使用8bit或16bit量化方案。在CNN网络中,输入的特征和权值通常用不同的scale进行量化,因此特征和权值的小数点也不同。这不会给低位乘法操作带来麻烦。但是在加法网络络中,如果对特征和权值进行不同scale的量化,则在加法器运算之前,卷积参数必须首先与移位运算进行点对齐,从而增加了硬件的功耗和逻辑消耗。因此,我们提出共享scale的量化方法,共享scale保证了硬件中的加法器卷积核可以直接开始计算,而不需要点对齐,对硬件友好。全精度网络的原始Top-1和Top-5精度分别为68.8%和88.6%。经过8位量化后,Top-1和Top-5精度分别保持在68.8%和88.5%,精度损失接近于零。
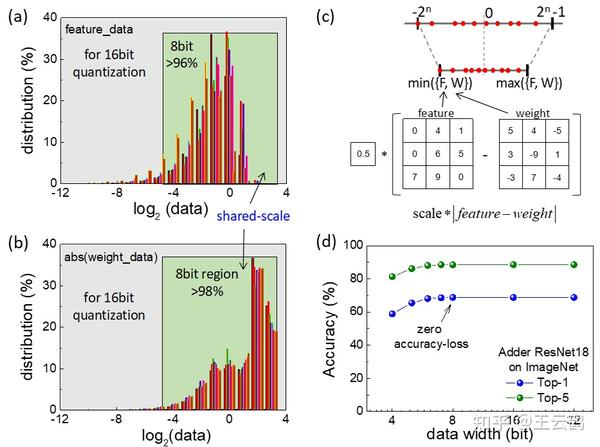
图4 (a,b) 加法网络Resnet18的不同层中的输入特征和权重的分布。(c) 对称量化模式。(d) 加法网络ResNet18的量化结果。
加法网络硬件设计
用于加速深度学习算法的最新硬件平台包括现场可编程门阵列(FPGA)、专用集成电路(ASIC)、中央处理器(CPU)、图形处理单元(GPU)和数字信号处理器(DSP)。在这些方法中,基于FPGA的加速器以其良好的性能(远优于CPU,与GPU相当)、高的能量效率、快速的开发周期(约几个月,远高于ASIC)和可重构性而备受关注。
FPGA卷积加速器的结构大致可分为4个部分:并行内核操作核心、数据存储单元和输入输出端口、数据通路控制模块以及池化和BN单元。通常,由于FPGA的单指令多数据(SIMD)结构,卷积核操作占用了大部分的逻辑资源。因此,对卷积核进行硬件简化和优化具有重要意义。
图5(b)显示了在Xilinx Zynq UltraScale+MPSoC系列板上实现的加法网络通用加速器的总体设计,该板将处理系统(PS,即ARM Cortex系列CPU)和可编程逻辑(PL,即可编程FPGA)集成在一起。卷积加速器由外部存储器、片上/片外互连、片上缓冲区和并行计算处理单元组成。PS和PL之间的数据传输由高级可扩展接口(AXI)互连协议控制,其中参数配置使用AXI-lite协议,权重/特征转换使用AXI-full协议。图5(a)展示了加法卷积核上的并行计算。加法卷积核主要包含两个加法器和一个数据选择器,CNN核包含一个乘法器。虽然AdderNet内核看起来更复杂,但实际上它比CNN要轻得多。
图5(c1-c2)在FPGA中分别合成不同并行度的16bit CNN和16bit加法网络的硬件资源占用百分比。这里为了公平比较,没有使用DSP资源。可以看出,随着并行度的提高,卷积核占用了越来越多的逻辑资源。图5(c3)卷积部分可以节省80%左右的逻辑资源,整个系统可以达到节省67.6%的逻辑资源占用。图5(d1-d3)8位网络中AdderNet和CNN的比较结果。卷积部分和全网的逻辑资源降低率分别约为70%和58%。
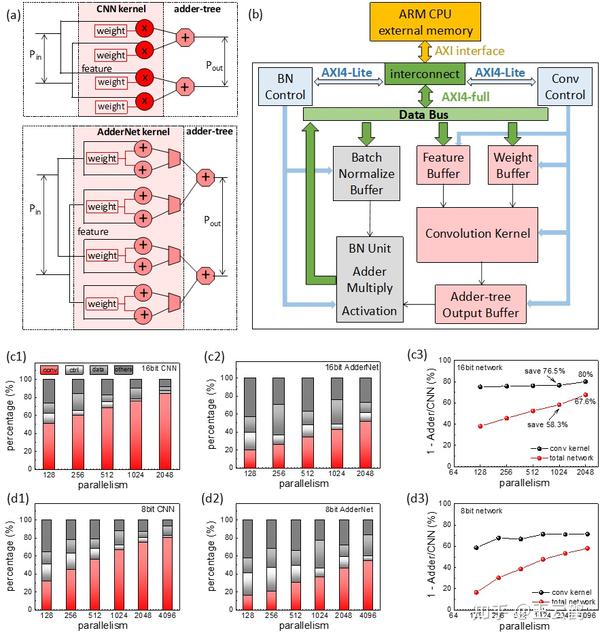
图5 加法网络硬件架构及资源占用结果
总结
该项研究提出了加法器神经网络(AdderNet)的低比特量化算法,以及在精度和硬件开销方面达到最优水平的硬件设计。具体来说,与传统的乘法核CNN、新型忆阻器核CNN和移位核CNN相比,加法网络具有高性能和低功耗的优点。此外,本文还提出了一种用于加法网络的共享比例因子量化方法,该方法不仅对硬件友好,而且在6bit以上量化的精度损失几乎为零的情况下,具有良好的性能保证。最后,我们设计了在FPGA上实现神经网络的专用和通用卷积加速器。在实际应用中,加法核理论上比乘法核(即传统的CNN)节省了81%的资源。实验结果表明,在相同的电路设计条件下,加法网络可获得约1.16倍的加速比,逻辑资源占用(电路面积)降低67.6%-71.4%,功耗降低47.85%-77.9%。
推荐阅读
文章首发知乎,更多深度模型压缩相关的文章请关注深度学习压缩模型论文专栏。

