
本篇主要介绍MindSpore原创多跳问答检索模型TPRR,分享团队在复杂的开放域问答工作上的一些探索。十分欢迎各位一起探讨更多NLP任务场景的挑战和趋势。
·背景
自然语言处理中,问答(QA)一直是十分热门的领域,旨在希望AI想人类一样“具有推理能力”,能够根据已有知识自动回答提出的问题。与传统的信息检索相比,QA研究如何处理以自然语言的形式提出的问题,而不是一些查询语言。
在传统的抽取式简单问答中(如SQuAD)中,很多问题的答案只需要从原文中抽取与问题相关的一个句子就能回答。而在复杂的多跳问答中,系统需要通过收集多篇文档并通过推理才能回答一个问题。比如“where did Algeria qualify for the first time into the round of 16?”。如图1所示,仅依赖单个wiki的文档只能得到Algeria第一次进世界杯16强是在2014年。因此系统还需要2014 FIFA World Cup的wiki文档,通过多跳推理融合两个文档信息从而预测出正确答案“Brazil”。

图1 Algeria at the FIFA World Cup词条

图2 2014 FIFA World Cup词条
针对上述复杂的多跳问答场景,华为泊松实验室和MindSpore团队联合提出了一种解决开放域多跳问题的通用模型TPRR(Thinking Path Re-Ranker)。TPRR基于全路径建模和动态负样本构建并经过EPR(External Path Reranker)模块细粒度精排从而大幅提升系统多跳问答的的能力。自2021年1月,TPRR在国际权威多跳问答榜单HotpotQA Fullwiki Setting评测中荣登榜首。相关论文已被SIGIR2021录用,推理代码已基于MindSpore开源发布,欢迎大家使用。
论文链接:
http://playbigdata.ruc.edu.cn/dou/publication/2021\_SIGIR\_Ranker.pdf
代码链接:
https://gitee.com/mindspore/mindspore/tree/master/model\_zoo/research/nlp/tprr
·问题定义
解决复杂问答问题的流程主要包括:
1、 多轮信息检索器(retriever)根据问题从海量文档中检索出相关的线索文档候选集
2、 重排器(reranker)对于候选线索文档进行精排,选出最佳的线索文档序列
3、 阅读器(reader)从最佳线索文档多个句子中解析出答案span
以二跳问答举例。如图3所示,最右的概率表示已知问题q,选取一跳文档 的概率d\_i^1,是一跳文档检索的建模目标。中间的概率表示已知问题q和一跳文档d\_i^1,选取二跳文档d\_j^2的概率。在先前ICLR工作[1]中,二跳文档检索建模时是基于greedy search的思想,仅使用p(d\_j^2 |q,d\_i^1 )作为建模目标,即只优化当前的文档检索。
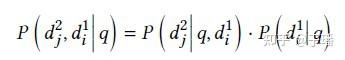
图3二跳路径概率公式
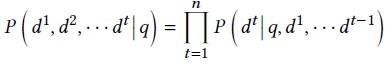
图4 全局路径概率公式
这种优化过程是次优的,因此TPRR采用全局路径建模的方式,进行多跳文档检索建模时,用“全局”的视角每次对于当前的路径检索进行建模。从理论上分析,如图4在第n跳检索建模的过程中,引入前n-1跳的概率,则可以根据当前跳的监督信号,在梯度反传过程中对于模型先前的检索进行监督“微调”,加大了对于正确文档检索的监督信号。结果如图5呈现,全局路径建模端到端的多轮检索效果更佳。
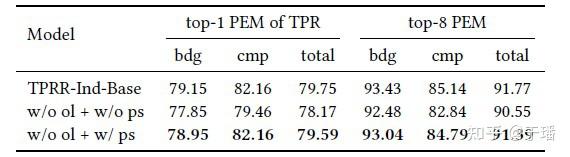
图5 全局路径建模消融结果
·动态负样本训练方式
在多跳检索的训练中,每一跳路径的优化目标如图6所示。通过rank loss计算,希望在所有训练路径排序中,最大化当前正确路径(d^1,…,d^(t-1),d\_c^t)概率。在检索模型的训练中,负样本的选取十分重要。微软先前的工作[2]指出,“容易”的负样本训练loss越小,梯度越小,对于训练收敛的帮助也很小。检索模型的训练收敛十分依赖于负样本的“信息量”,即难易程度。
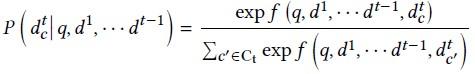
图6 检索优化目标
借鉴上述思想,TPRR设计了一种动态的负样本训练方式用来模拟人的学习思考过程,举个例子,在小学阶段,我们入门一些简单的加减法。到了中学阶段,学习一些函数和方程的思想。到了大学阶段,随着知识量的累积开始学习微积分等更难的数学课程。因此,我们在检索模型的训练过程中不断增加训练负样本的“难度”,从而使得模型学习过程更加“自然”。利用topk算子如图7,在_t_跳路径建模时,所有负样本输入_M_中只选择得分topk的输入进行反传。
在训练初期,模型检索能力较弱的时候,模型对于样本打分不能很好区分正负样本。此时,选取的_k_个负样本是比较“容易”的,训练检索模型对于一般样本的区分能力。随着训练步数的增加,模型检索能力变强,选取的_k_个负样本是“困难”的,此时“容易”的负样本训练对于模型的检索能力已经很少有提升。因此利用topk的选取负样本策略,模型的学习任务随着模型能力增强变得更加困难,模拟人的学习过程。
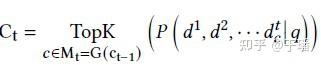
图7 topk选择负样本
最终结果如图8,动态负样本的训练方式大大提升了模型的检索能力。
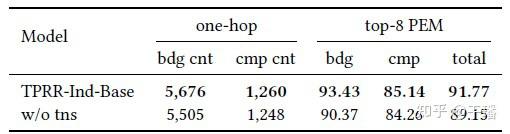
图8 动态负样本消融结果
·细粒度精排
通过上述的初步检索过程,从500w的wiki文档中筛选出top8的相关文档序列。TPRR使用了更细粒度的文档划分和多任务预测筛选最佳线索文档。在精排过程中,将相关文档拆分为标题、句子、段落的不同粒度构造相关的输入。同时在最终任务中,同时进行路径预测、检索段落预测、检索句子预测三个不同粒度的任务。如图9,额外的精排过程带来了巨大的top1检索准确率收益。
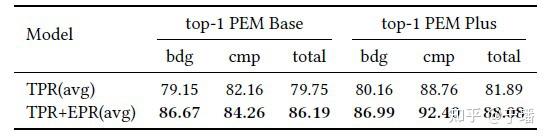
图9 精排消融结果
在多跳问答权威benchmark Hotpot QA中,多项创新技术的引入带来了巨大收益,如图10、图11,TPRR在答案、线索和联合准确率指标上均超越SOTA模型,在Fullwiki setting中名列榜首。
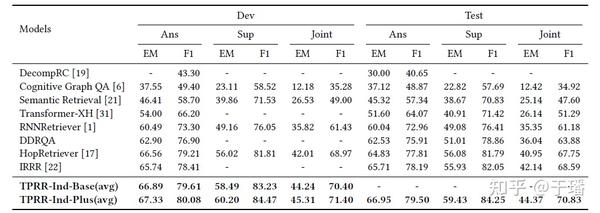
图10 Hotpot QA实验结果
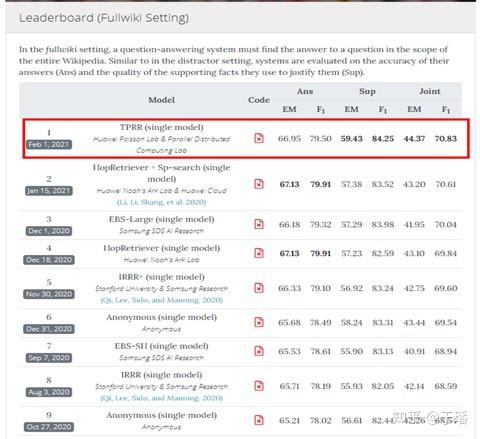
图11 Hotpot QA榜单
对于TPRR的介绍就到这里啦,欢迎大家多多讨论,批评指正。
最后给MindSpore打个广告,期待大家多多参与使用
MindSpore官网:https://www.mindspore.cn/
MindSpore论坛:https://bbs.huaweicloud.com/forum/forum-1076-1.html
参考文献:
[1] Asai A, Hashimoto K, Hajishirzi H, et al. Learning to retrieve reasoning paths over wikipedia graph for question answering[J]. arXiv preprint arXiv:1911.10470, 2019.
[2] Xiong L, Xiong C, Li Y, et al. Approximate nearest neighbor negative contrastive learning for dense text retrieval[J]. arXiv preprint arXiv:2007.00808, 2020.
END
原文:知乎
作者:于璠
推荐阅读
更多嵌入式AI技术干货请关注嵌入式AI专栏。

