
华为诺亚实验室的研究员们联合高校提出一系列用于高效视觉Transformer的网络架构和模型压缩算法,包含高效Transformer架构、视觉Transformer剪枝、量化以及知识蒸馏。相关技术已陆续发布,可以用于不同需求和场景,能给现有视觉Transformer带来模型精度、模型大小、计算复杂度等方面的增益。下面将一一介绍这些方面的系列工作。
高效视觉Transformer架构
Transformer in Transformer:https://arxiv.org/abs/2103.00112
CMT: Convolutional Neural Networks Meet Vision Transformers:https://arxiv.org/abs/2107.06263
Augmented Shortcuts for Vision Transformers:https://arxiv.org/abs/2106.15941
视觉Transformer压缩
Patch Slimming for Efficient Vision Transformers:https://arxiv.org/abs/2106.02852
Visual Transformer Pruning:https://arxiv.org/abs/2104.08500
Post-Training Quantization for Vision Transformer:https://arxiv.org/abs/2106.14156
Efficient Vision Transformers via Fine-Grained Manifold Distillation:http://arxiv.org/abs/2107.01378
Transformer in Transformer
论文题目:Transformer in Transformer
论文:https://arxiv.org/abs/2103.00112
代码:https://github.com/huawei-noah/CV-Backbones/tree/master/tnt\_pytorch
TNT网络架构
在本文中,作者提出一种用于基于结构嵌套的Transformer结构,叫做Transformer-iN-Transformer (TNT)架构。TNT同样将图像切块,构成Patch序列,不过,TNT不把Patch拉直为向量,而是将Patch看作像素(组)的序列。新提出的TNT block使用一个外Transformer block来对patch之间的关系进行建模,用一个内Transformer block来对像素之间的关系进行建模。通过TNT结构,既保留了patch层面的信息提取,又做到了像素层面的信息提取,能够显著提升模型对局部结构的建模能力,进而提升模型的识别效果。在ImageNet基准测试和下游任务上的实验表明了该方法在精度和计算复杂度方面的优越性。例如, TNT-S仅用5.2B FLOPs就达到了81.5%的ImageNet top-1正确率,这比计算量相近的DeiT高出了1.7%。
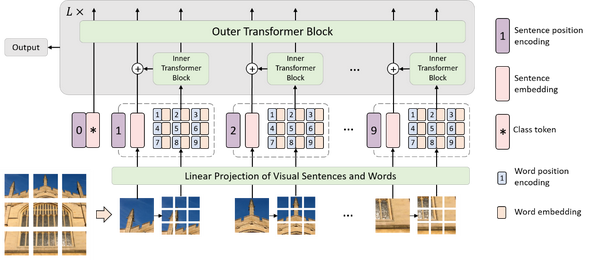
图: Transformer in Transformer架构
ImageNet实验
作者在ImageNet 2012数据集上训练和验证TNT模型。从下表可以看出,在纯transformer的模型中,TNT优于所有其他的纯transformer模型。TNT-S达到81.3%的top-1精度,比基线模型DeiT-S高1.5%,这表明引入TNT框架有利于在patch中保留局部结构信息。通过添加SE模块,进一步改进TNT-S模型,得到81.6%top-1。与CNNs相比,TNT的性能优于广泛使用的ResNet和RegNet。不过,所有基于transformer的模型仍然低于使用特殊depthwise卷积的EfficientNet,因此如何使用纯transformer打败EfficientNet仍然是一个挑战。
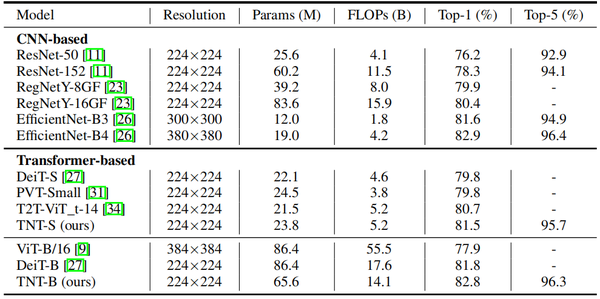
表: 在ImageNet数据集和SOTA模型对比
目标检测实验
为了证明TNT具有很强的泛化能力,作者在ImageNet上训练的TNT-S模型迁移到其他数据集。更具体地说,TNT和DETR结合构建了纯Transformer目标检测器,在COCO目标检测数据集上评估TNT模型,下表比较了TNT与ViT、DeiT和其他网络的迁移学习结果。TNT在优于DeiT和PVT,这表明在获得更好的特征时,对像素级关系进行建模的优越性。
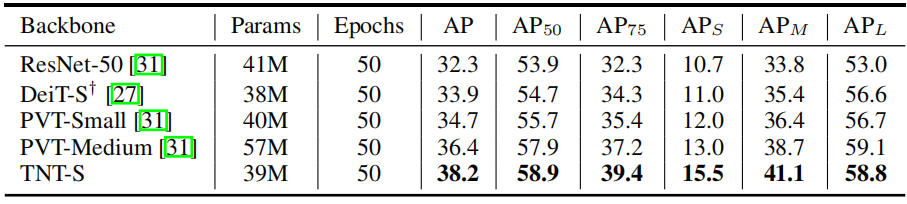
表: TNT在目标检测的表现
Convolution Meets Transformer
论文题目:CMT: Convolutional Neural Networks Meet Vision Transformers
论文:https://arxiv.org/abs/2107.06263
CMT网络架构
在本文中,作者提出一种用于基于Convolution和Transformer的混合结构,叫做CMT结构构。由局部感知模块(LPU)、轻量级多头注意力机制(LMHSA)和反向残差模块(IRFFN)组成。并基于CMT结构,利用传统的卷积Stem和全连接FC层来搭建完整的网络模型。该CMT模型相比于传统Transformer,利用卷积进行局部信息建模。相比于传统CNN,保留了全局层面的特征提取能力,进而极大提升模型的识别效果。并利用混合的缩放规则,产生不同计算量的一系列模型(CMT-Ti,CMT-XS,CMT-S,CMT-B和CMT-L)。在ImageNet基准测试,迁移任务和视觉下游任务上的实验表明了该方法在精度和计算复杂度方面的优越性。例如, CMT-S仅用4.0B FLOPs就达到了83.5%的ImageNet top-1正确率,这比计算量相近的EfficientNet-B4高出了0.6%,比Swin-T高出2.2%。
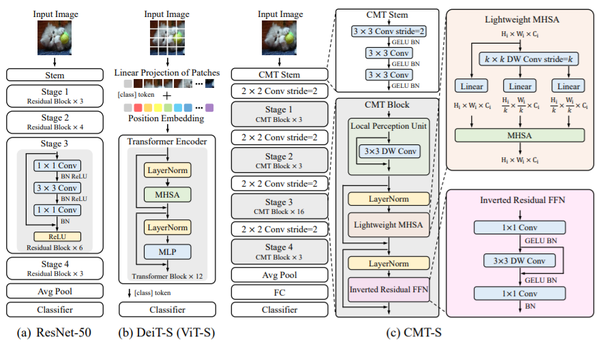
图: 传统CNN、传统Transformer和CMT模型结构对比
ImageNet实验
作者在ImageNet 2012数据集上训练和验证模型。从下表可以看出,在现有模型中,CMT优于所有其他的经典模型。
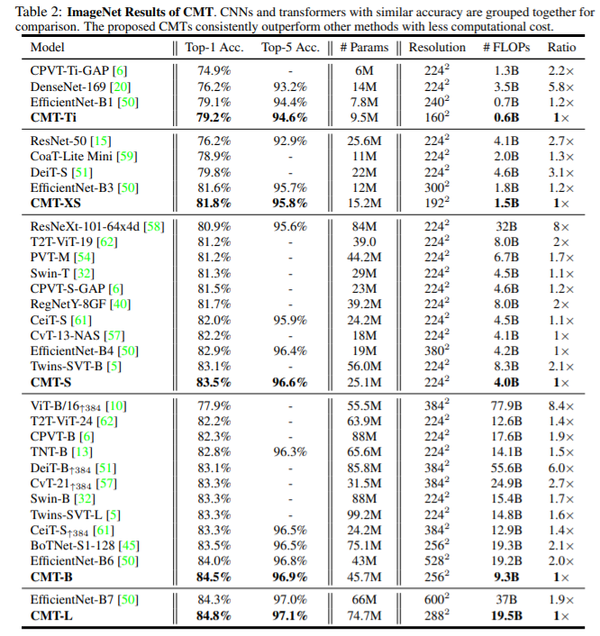
表: 在ImageNet数据集和SOTA的模型比较
目标检测及分割实验
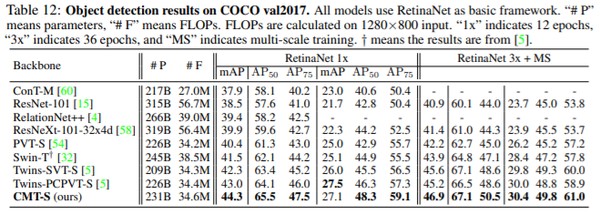
表: 基于RetinaNet框架在COCO数据集的性能
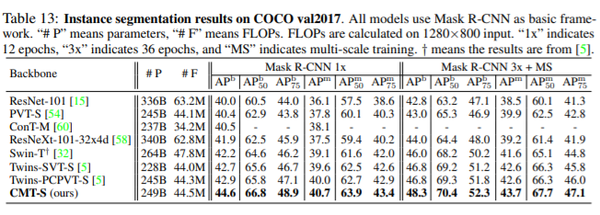
表: 基于Mask R-CNN框架在COCO数据集的性能
增强Shortcut
论文题目:Augmented Shortcuts for Vision Transformers
论文:https://arxiv.org/abs/2106.15941
方法
在本文中,作者提出了一个augmented shortcut模块,用于增强视觉Transformer特征的多样性,进而提高模型性能。随着transformer模型深度的增加,不同patch的特征会变得越来越相似,这限制transformer的表达能力。shortcut可以缓解这个现象,但传统的shortcut只是将输入特征简单复制到输出,无法最大程度地增强特征多样性。本文提出的augmented shortcut模块包含多条带参数的路径,每条路径都对输入特征做不同的变换,使得输出特征更加多样;同时,作者引入分块循环投影高效地部署各个路径,极大地节省了计算成本。 类似于经典的shortcut,augmented shortcut可以灵活地部署在不同的网络结构中,用于完成不同任务。标准分类数据集ImageNet上的结果显示,在几乎不增加参数量和计算量的前提下,多种SOTA的视觉Transformer模型(ViT, PVT, T2T等)的Top-1准确率均可提高1%左右。
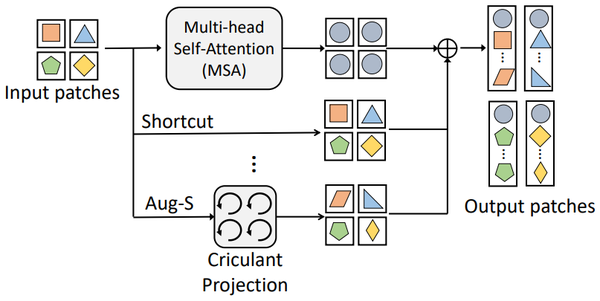
图:使用Augmented shortcut加强的多头自注意力模块(MSA)
ImageNet实验
作者在ImageNet数据集上进行大量实验验证Augmented shortcut 模块的有效性,结果如下表所示。将Augmented shortcut模块装配到标准的ViT 模型上,获得了超过1%的性能提升。PVT和T2T是ViT模型两种最新的变体,Augmented shortcut模块也可以进一步提升它们的性能。 一个有意思的现象是,Augmented shortcut对深度模型的性能提升更加有效,这将有助于帮助深度Transformer模型结构的设计。
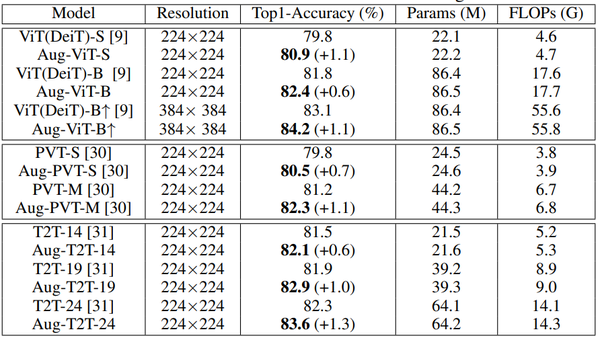
表: 不同模型在ImageNet数据集上的性能
目标检测实验
作者在COCO数据集上针对Object Detection任务也进行了实验,使用augmented shortcut模块的模型在各个指标上都优于baseline模型。
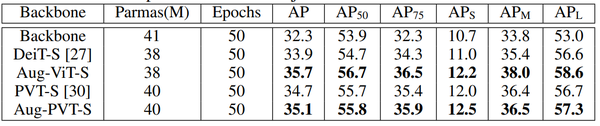
表: COCO数据集上的Object Detection实验
Patch剪枝
论文题目:Patch Slimming for Efficient Vision Transformers
论文:https://arxiv.org/abs/2106.02852
方法
在本文中,作者提出一种用于加速视觉Transformer的Patch修剪算法。相比于关注通道冗余的CNN剪枝,本文针对视觉Transformer,探索一个新维度的冗余性——无用的Patch计算。下图对比了CNN的通道剪枝和Transformer的Patch修剪,发现了Patch修剪需要特别考虑相邻层Patch的连贯性和不同层Patch冗余大小的差异。作者提出一种自上而下的修剪框架,以确保高层语义特征可以很好地保留。具体来说,Patch剪枝过程是从最后一层执行到第一层,每层Patch的有效性通过计算它们对最终分类特征的重要性分数来判别。为了保证信息连贯性,相邻层同一空间位置的Patch将被共同保留下来。一个全局的误差控制了Transformer各个层的修剪过程,自动决定各个层需要保留的Patch数量,因此修剪后的Transformer可以在显着降低计算成本的情况下保持原始性能。大量实验验证了Patch修剪方法的有效性。例如,在精度几乎无损的情况下,ImageNet 数据集上的ViT-Ti 模型的 FLOP可以减少45%以上。
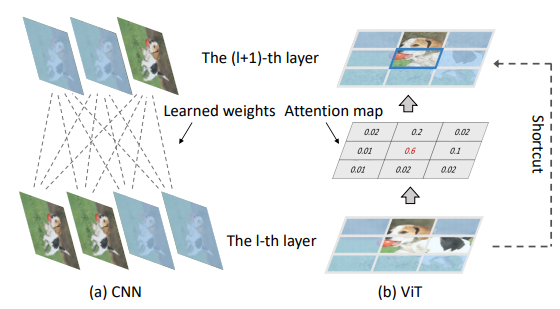
图: CNN的通道修剪和视觉Transformer的Patch修剪
ImageNet实验
作者在ImageNet数据集上进行大量实验验证Patch修剪的有效性,结果如下表所示。不同视觉Transformer模型在Patch维度均存在较大冗余,去掉冗余的Patch计算可以大幅减小计算量。比如,对于已经较为紧凑的ViT-Ti模型,在去除46.2%的计算量之后,只有0.2的准确率损失。除了标准的ViT模型,作者也在一些最新的变体(比如T2T-ViT)上验证了方法的有效性。
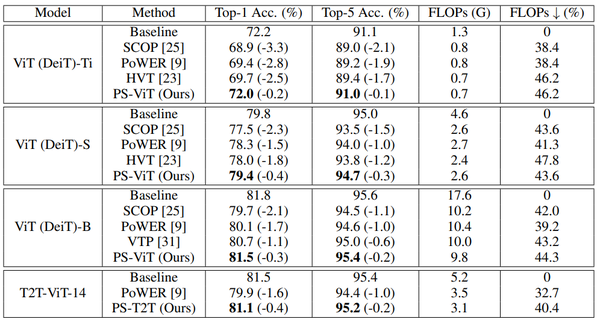
表: ImageNet数据集上不同视觉Transformer模型的Patch修剪
通道剪枝
论文题目:Visual Transformer Pruning
论文:https://arxiv.org/abs/2104.08500
方法
本文提出一种视觉Transformer剪枝方法,叫做Visual Transformer Pruning (VTP)算法。通过促进Dimension层面的稀疏性,VTP获取每一个Transformer block中Dimension的重要性分数,然后对分数较低的Dimension进行裁剪。如此一来,大量的不重要的Dimension将会被裁剪,而模型的准确率却几乎没有受到影响。VTP的流程如下所示:1.用L1稀疏正则进行训练。2.在Dimension维度裁剪Transformer Block中的线性映射层。3.微调。VTP方法既保留了Transformer强大的表征能力,又显著降低了模型的计算量和参数,进而提升了模型的总体表现。 在ImageNet-100和ImageNet-1K基准测试上的实验表明了该方法的有效性和优越性。 总体而言,VTP方法为后续的Transformer剪枝工作提供了一个坚实的Baseline方法。
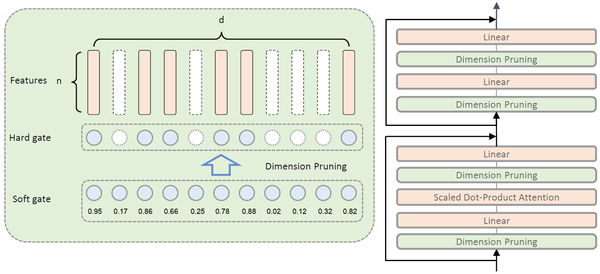
图: Visual Transformer Pruning架构
ImageNet实验
作者在ImageNet-1K (ImageNet 2012)数据集上训练和验证VTP算法。从下表可以看出,以DeiT-B作为baseline模型,当40%的dimension被裁剪时,VTP的准确率降低了1.1% 。当20%的dimension被裁剪时,VTP的准确率降低了0.5%。
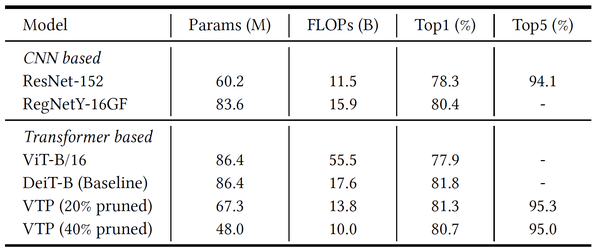
表: 在ImageNet数据集上的表现
模型量化
论文题目:Post-Training Quantization for Vision Transformer
论文:https://arxiv.org/abs/2106.14156
方法
在本文中,作者提出了一种针对视觉Transformer的后训练量化算法。研究人员首先将后训练量化建模为寻找最优的量化步长问题。为了更好地保留注意力层的功能,他们分析了注意力层量化前后特征的不同,引入了注意力层排序的损失函数。并与量化前后特征分布的相似度损失进行了联合优化。此外,论文还提出考虑到不同网络层的特征多样化不同,可以根据注意力特征和输出特征权重矩阵的核范数来决定每个网络层的量化比特。在不进行额外训练的情况下,Deit-B的8bit模型在ImageNet图像分类任务上可以实现81.29%的精度。
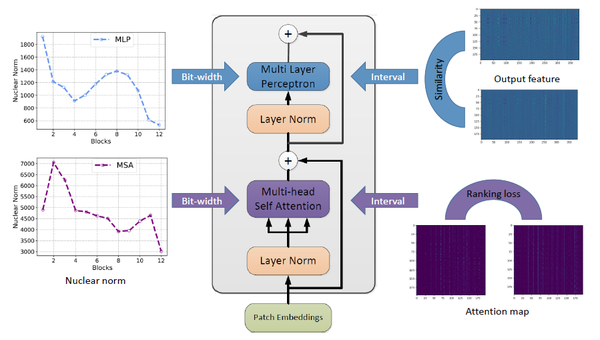
图: 视觉Transformer后量化方法
ImageNet实验
作者首先在图像分类任务上对后训练量化算法进行了验证。从下表可以看出,在ViT和DeiT两种经典的transformer模型上,论文的量化算法均优于之前的卷积神经网络量化算法。在较小的数据集CIFAR-10上,论文的算法都接近或超过了全精度的transformer模型的性能,在ImageNet数据集上,ViT-B和ViT-L的8比特模型都取得了与全精度模型近似的效果。而Deit-B模型也取得了81.29%的Top-1准确率。
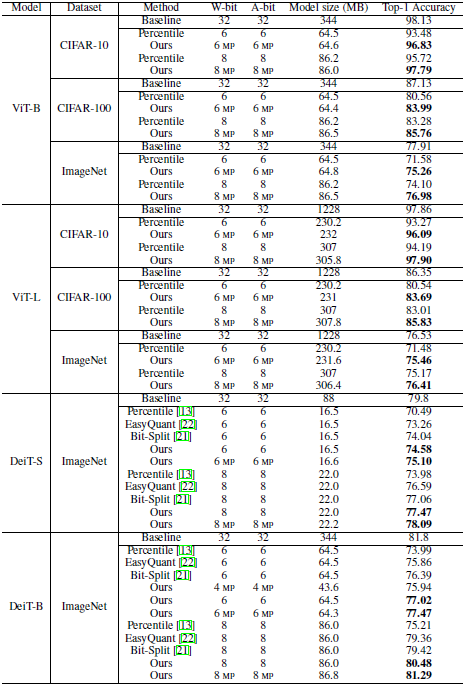
表: 在ImageNet数据集上的表现
知识蒸馏
论文题目:Efficient Vision Transformers via Fine-Grained Manifold Distillation
论文:http://arxiv.org/abs/2107.01378
方法
在本文中,作者提出了适用于视觉transformer的基于流形学习的蒸馏方法,其在教师transformer网络的各个block间构建当前batch内所有样本的patch之间的关系并将该关系传递给学生网络,以获取教师网络的中间特征,与对网络输出logits的蒸馏相结合,进一步辅助学生网络的训练。为了实际训练的方便,作者不直接构建batch内所有patch间的关系,而是按照特定的pattern对关系进行采样以减少内存消耗和计算量,同时添加随机采样项来减少采样误差。该蒸馏方法相比于其他适用于视觉transformer的蒸馏方法,对教师网络所携带信息的利用率更高,并且在提取网络中间特征时不要求教师网络和学生网络特征维度的对齐,因此具有较高的灵活性,在选择教师网络时更加灵活。该蒸馏方法显著提升了学生transformer网络的表现。例如,与DeiT中的蒸馏相比,本文所提出的蒸馏方法在ImageNet数据集和DeiT-Tiny学生网络中获得了0.6%的Top1准确率提升。
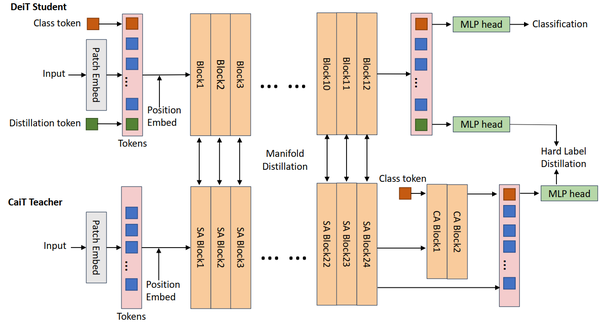
图:基于流形学习的知识蒸馏结构图
ImageNet实验
作者选择DeiT网络作为学生网络,CaiT网络作为教师网络,在ImageNet 2012数据集上进行了实验以验证方法的有效性。从下表和下表可以看出,无论是选择同样的CaiT网络作为教师网络,还是与DeiT蒸馏实验中所使用的CNN教师网络RegNetY-16GF相对比,本文所提出的蒸馏策略在使用同等参数量和精度的教师网络时的表现均明显优于DeiT的蒸馏结果,这证明了本文方法与现有视觉transformer蒸馏方法相比,在保持了方法灵活性的同时提升了蒸馏效果。
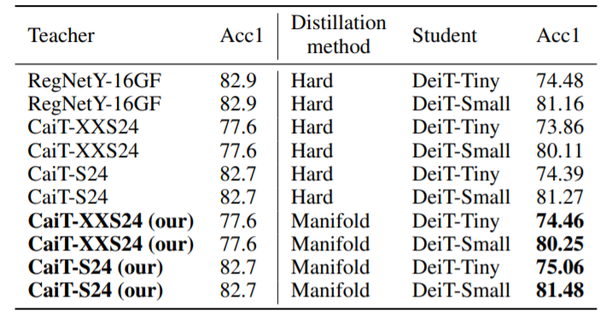
表:ImageNet实验与DeiT的hard-label蒸馏策略的结果对比
总结
高效视觉Transformer架构
Transformer in Transformer:https://arxiv.org/abs/2103.00112
CMT: Convolutional Neural Networks Meet Vision Transformers:https://arxiv.org/abs/2107.06263
Augmented Shortcuts for Vision Transformers:https://arxiv.org/abs/2106.15941
视觉Transformer压缩
Patch Slimming for Efficient Vision Transformers:https://arxiv.org/abs/2106.02852
Visual Transformer Pruning:https://arxiv.org/abs/2104.08500
Post-Training Quantization for Vision Transformer:https://arxiv.org/abs/2106.14156
Efficient Vision Transformers via Fine-Grained Manifold Distillation:http://arxiv.org/abs/2107.01378
推荐阅读
文章首发知乎,更多深度模型压缩相关的文章请关注深度学习压缩模型论文专栏。

