
1 引言
交互式推理任务中的对时延的要求越来越高,因此深度神经网络推理任务大量向GPU进行迁移。为此,MindSpore 1.3.0版本对GPU推理性能进行优化,性能相比此前大幅提升。
2 推理和训练差异
2.1 学 vs 用
通常深度学习将“学以致用”的分为”学习“和”应用“两个阶段的任务。前者的目的是得到一个能够用于拟合经验数据的模型,在深度学习领域称为训练(training);后者是对未知数据上进行预测,在深度学习领域称为推理(Inference)。
2.2 吞吐率 vs 时延
与训练追求高吞吐率(Throughput)不同,推理强调低时延(latency),二者虽然都可以简单表述为“快”,但在本质上是有区别的。
在神经网络训练过程中,数据是一批一批处理的,其中 Batch Size是一个重要的参数:一个Batch Size中的所有样本共同决定模型参数更新的方向,当Batch Size过小时,这一批次数据不能反映整个数据集的全局特征,无法准确地给出参数收敛的方向,通常导致模型难以收敛。由于受限于显存容量,有时大模型需要采用“数据并行”、“梯度累积”的方式,进一步提升Batch Size,从而提升模型收敛速度。因此,对于训练任务,需要解决的是如何尽快的完成一个批次数据计算。
在推理任务中,请求往往是独立到达的,此时程序需要尽快给出响应,特别是交互式推理任务中对时延有极高要求,在服务合同中称为SLO(Service Level Objectives)。试想举着手机在拍照,还未等对焦完成,手不由自主的抖了一下,这时不得不再次对焦,这种体验并不友好。
3 低时延对框架的诉求
3.1高效Runtime:
一般我们不在GPU中做指令(算子到算子之间)跳转,模型中的算子需要由CPU下发;CPU和GPU之间采用pipeline方式执行,GPU在执行当前算子时,CPU可以继续构建并下发后续算子,这意味着最终的时延受限于二者中较慢的设备。对于典型CNN的网络,训练一个step约几十至几百毫秒,而处理一条推理请求只需要几毫秒。也就是说,推理任务对Runtime的性能要求是远高于训练的。从GPU的演进看,堆叠流处理器数量是提升Tensor处理速度的有效手段,通常每一代GPU相比上一代提升均在几倍到十几倍之间,而CPU的单核处理能力增长有限,此时CPU就更容易成为性能瓶颈。这也就意味着,随着GPU的迭代,留给Runtime的时间将越来越少。

3.2 更加丰富的图优化
相比于训练,通常推理具备更大的优化空间
3.2.1 常量折叠
以BatchNorm算法如下:
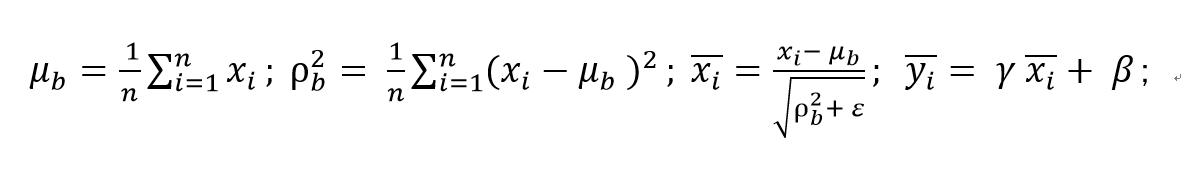
μ、ρ、γ、β是模型的权重,在训练阶段 μ和ρ通常以EMA方式进行更新,γ和β以梯度下降方式更新:
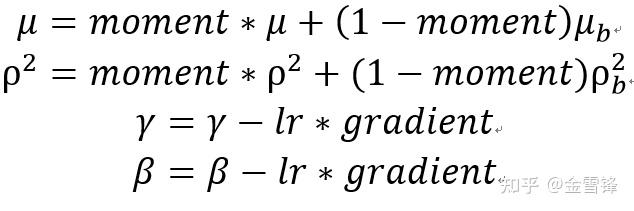
在推理阶段,μ、ρ、γ、β已经固定,因此可以将部分计算可以提前到部署推理任务之前。
令:
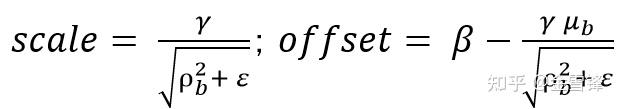
在模型部署后,BatchNorm仅需要计算
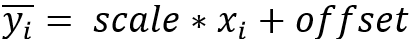
省去了add,sub,mul,div,pow,sqrt等计算,降低计算量,提升推理性能
3.2.2 算子融合
在图优化中,算子融合一向是提升执行性能最有效的手段之一。训练执行流程如下图所示,正反向算子之间往往需要数据通信,这一定程度上阻止了相邻算子之间的融合,或者降低融合的效果。
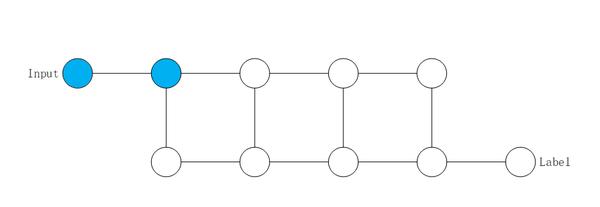
在推理时不存在反向图结构,这带来更大的算子融合空间。例如在推理时,我们可以将多个Conv2d融合成为一个算子,提升GPU的利用率
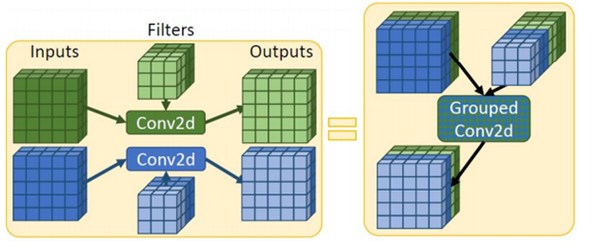
参考:https://arxiv.org/pdf/2102.02344.pdf
3.2.3 低精度计算
在深度神经网络中,梯度通常在0附近,优化器驱动权重以Learning Rate为步长更新。低精度数据类型表示的动态范围有限,容易出现梯度消失,导致模型得不到更新。
下图展示了激活函数的梯度分布,采用FP16训练时,将会丢弃大部分有效信息。因此,训练过程中,以FP32和FP16/BF16为主;在推理任务中不需要对模型的权重进行更新,可以采用更低的计算精度,得到无损、微损的计算结果。
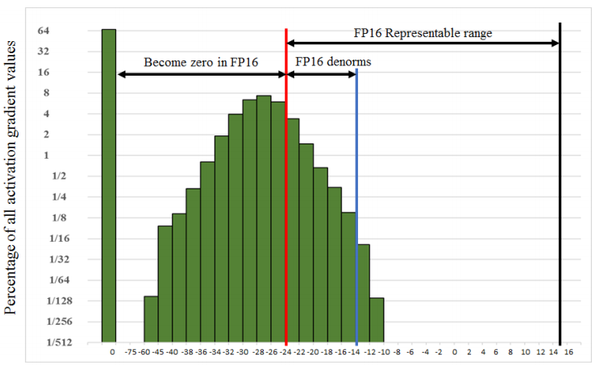
参考:https://arxiv.org/pdf/1710.03740.pdf
3.2.4 算子优化
Batch Size不同,导致算子对硬件资源利用率也会有差异,此时需要考虑算子调度策略和Tuning参数,有兴趣的同学可以参考:Rammer: Enabling Holistic Deep Learning Compiler Optimizations with rTasks (https://www.usenix.org/conference/osdi20/presentation/ma), IOS: INTER-OPERATOR SCHEDULER FOR CNN ACCELERATION (https://arxiv.org/pdf/2011.01302.pdf)
3.2.5 其它
例如剪枝和稀疏化,由于篇幅所限,这里不便展开分析,有兴趣的同学可以查阅相关文档。
4 MindSpore方案介绍
TensorRT是一款高性能推理库,同时还可更大限度地降低延迟。 TensorRT提供了Python和C++接口,允许开发者直接导入ONNX、Caffe、UFF格式的模型,同时也支持逐算子构建网络。TensoRT内置的图优化、内存管理,推理引擎,可以大幅提升推理性能。因此,目前业界主流框架,例如TensorFlow、Pytorch、MxNet、TVM等均已经集成了TensorRT。于此同时,TensorRT还提供了低精度推理,Int8量化校准、自定义插件等功能、优化后模型导出,进一步提升推理性能和适用网络。
另一方面,TensorRT也存在一定的限制:TensorRT支持float、half、int、bool数据类型,暂时不支持double或者int64数据。另一方面,TensorRT目前内置了约80个算子,而MindSpore目前已支持近300个正向算子。因此MindSpore很多现有模型无法在TensorRT库进行推理。
为了同时兼顾MindSpore算子多样性和TensorRT推理性能,MindSpore采用了自动子图拆分。具体实现可以分为四步:
- 第一步:在后端图优化中,根据TensorRT的能力,将MindIR中的算子进行标注,并将连续的标注算子拆分成一张子图

Conv2D, BN, ReLU节点首先被标注为“可以转换为TensorRT Network”,随后连续的算子被拆分为一张子图
在这个过程中,需要避免子图拆分后,整个MindIR形成dead loop。
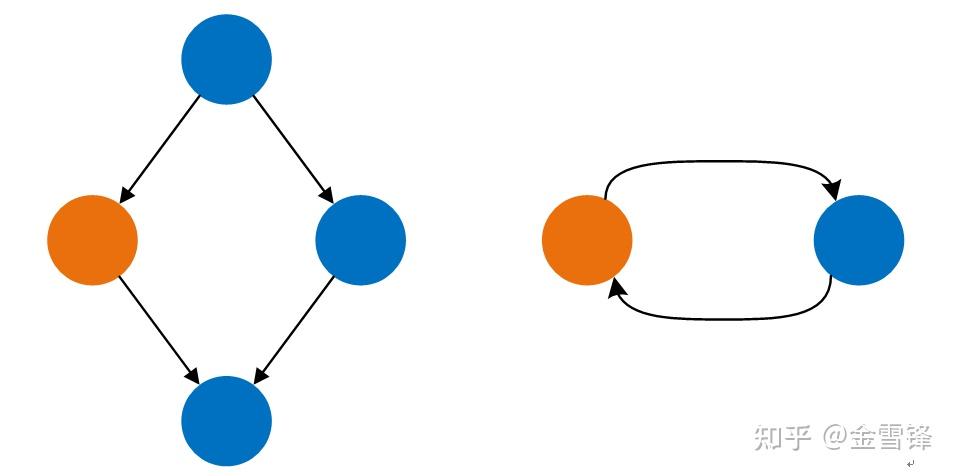
上图中,如果简单的将蓝色算子拆分为一张子图会导致形成dead loop,这种情况在需要避免
- 第二步:将MindIR子图传递给TensorRT,构建TensorRT Network

将MindIR子图转换为TensorRT的Network,部分算子可以简单映射,其它算子需要转换
- 第三步:将TensorRT Network进行序列化,使用序列化之后的数据构建TrtNode

TensorRT提供了Network的序列化。序列化数据中承载了网络结构,模型权重,和Auto Tuning信息。
序列化数据存储为TrtNode的Attribute
- 第四步:在模型推理时,TrtNode节点将被反序列化,并交由TensorRT 的cudaEngine执行,剩余算子则由MindSpore原生后端执行
5 性能测试
为了对比优化后的推性能,我们在model\_zoo目录下选择了一些典型的网络,分别使用MindSpore1.2.1和MindSpore1.3.0测试了10组数据,统计推理请求平均执行时间,平均推理延时降低了2~10倍。详细的测试环境和测试过程参考附录。

6 附录
1、测试环境软硬件配置如下:
2、测试过程如下

部署方法过程参考官网教程《基于MindSpore Serving部署推理服务》,https://www.mindspore.cn/tutorial/inference/zh-CN/r1.2/serving\_example.html
这里以AlexNet为例,其它网络类似
- 导出MindIR模型
对export.py做少量修改:导出模型格式为”MindIR”,设备类型为”GPU”
执行export.py文件,可以看到在当前目录下生成了alexnet.mindir模型
2)部署Serving

servable\_config.py配置如下,这里开启fp16推理模式

3)启动Serving
需要注意的是,这里我们需要将TensorRT的library路径加入到LD\_LIBRARY\_PATH中

4)重新打开一个terminal,发起推理请求

5)考虑到warm up带来的抖动,我们跳过前两次请求,仅统计后续10次的请求相应时间
Lenet

AlexNet

resnet50

vgg

InceptionV3

mobilenetv2

Mobilenetv3

Bert

Wide and Deep

本文转自:知乎
作者:金雪锋
推荐阅读
更多嵌入式AI技术相关内容请关注嵌入式AI专栏。

