
今天开讲本系列的之二,主要继续上一部分的内容,讨论片上多核系统对自身的互联子系统到底有什么需求。
没有看过的同学请先回顾:
详说片上网络之一:片上多核系统与片上网络的发展
在第一部分我们已经阐述清楚了,片上多核系统分为CMP和MPSoC两种架构。CMP架构的特点是采用共享存储来交换数据,换言之就是每一个核心其实是可以“看见”完整的地址空间的。而MPSoC则更像是多个独立的子系统在单个芯片上的集成,一般是“按需设计”,多个系统之间的存储空间一般相互不可见。
所以对于CMP而言,可以大致划分为CPU/处理单元和存储子系统两部分。整个系统运行的过程就是多个核心在一个共享的存储空间上运行多种程序。由于程序空间是共享的,因此程序可以在多个核心之间自由的调度,不同核心之间的数据交互也相对容易。对于数据交互的过程可以理解为CPU/处理器单元私有存储器与共享存储器之间的数据交换/Cache Line替换。
如果把这个过程抽象出来,那么可以看到下面这个图。
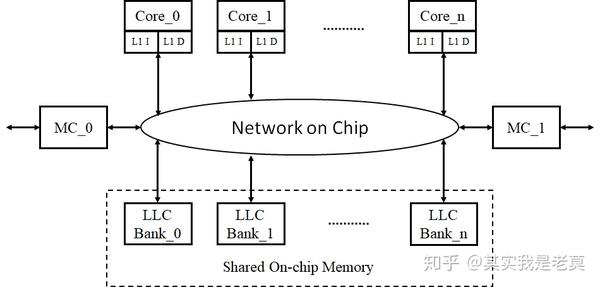
图1 基于NoC的CMP架构多核片上系统逻辑抽象图
从图1可以看出LLC(Last Level Cache)可以被分成多个Bank,但在逻辑上是是一个完整的共享区域。而每个Core以及L1 Cache是相互独立的,可以看做在不同的核心上运行不同的程序或者进程。
不同层级存储器之间的数据交换过程如图2所示。

图2 不同层级存储器之间的数据交换过程
从图2可以看出,整个数据交换过程与Cache的替换有关系。当发生Cache Miss以后,L1会去LLC中取数据。而当LLC也Miss以后,会通过存储器控制器去片外的存储器(内存)中取数据。因此在程序运行的过程中,实际上会不断的发生由于上一级Cache Miss而产生的访存行为。而当由于LLC是共享的,因此每个核在运行是可以访问任意的LLC的。这就造成了一个访问冲突的问题,
如果我们是以总线来互联各个Core和LLC,那么总线本身就成为了一个竞争性的资源。而如果我们用片上网络来互联Core和LLC,会在很大程度上消解访问冲突。因此对于CMP架构的多核片上系统而言,采用NoC的目的就在于消解访问冲突。而且NoC上运行的流量很多也是由于Cache一致性协议而产生的。因此在CMP架构的多核片上系统中,通常把NoC和Cache协同在一起考虑设计与优化,被统称为“Un-Core System”。
再仔细分析可以发现,采用NoC互联以后,存储器控制器会变成一个“竞争性”资源。LLC各个Bank出现Miss以后都需要通过它来访问外部的片外存储器。所以为了提升访存带宽需要设计多个存储控制器并设计多个片上通道来传输数据。
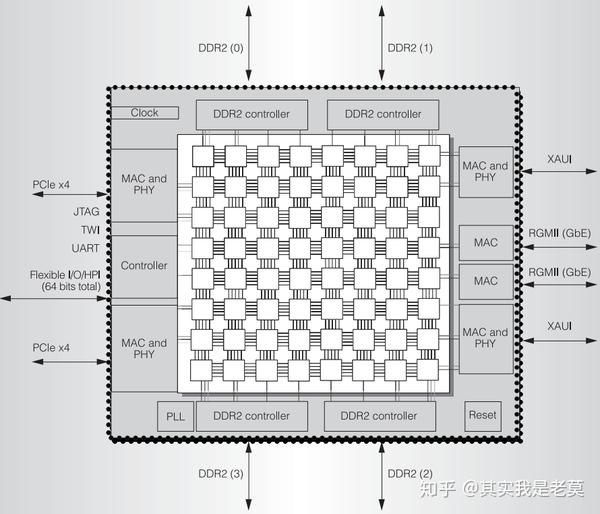
图3 CMP架构的片上多核系统与接口IP互联方案[1]
从图3[1]可以看出,在芯片中使用了四个DDR2的控制器。每个DDR2的控制器和不止一个片上网络节点连接。其它的如PCIe 以太网控制器也是类似的接法。
总而言之,在CMP中由于存在大量共享资源,因此使用NoC实现片上互联的根本目的就是尽可能的消解、缓和共享资源的访问冲突。因此NoC需要考虑和这些资源一起作为“Un-core System”协同优化。
而MPSoC的互联就更像通过网络的形式实现多个子系统的互联。具体的抽象如下图所示:
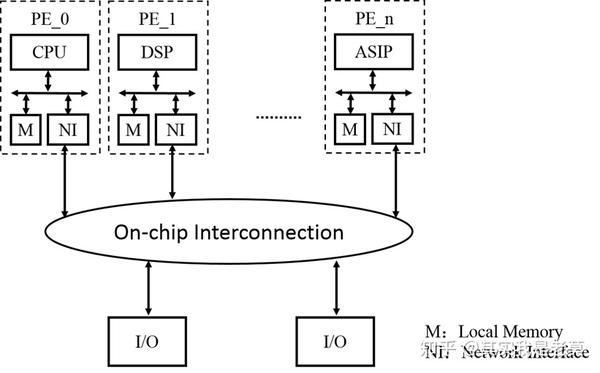
图4 基于NoC的MPSoCP架构多核片上系统逻辑抽象图
从图4中可以看出,采用片上网络互联的MPSoC每个处理单元(PE)是相对独立的子系统。一般情况下各个子系统之间的存储部分并不互通,没有一个共享的存储空间来存放共享数据和并行程序。各个子系统独立运作,分别执行不同的任务。一旦数据处理完毕,则通过网络发送到下一个需要继续处理的节点。
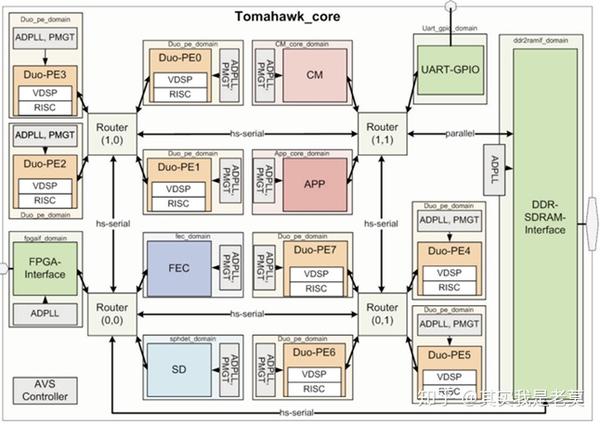
图5 一个实际的基于NoC的MPSoCP架构多核片上系统案例[2]
如果图4还过于抽象的话,那图5[2]就是一个具体的例子。这是一个用于无线通信的MPSoC,具有多个独立工作的运算单元以及专用电路。每个单元内部是一个DSP+一个RISC处理器。通过对于这些PE进行编程,可以灵活的支持多种无线通信处理协议。而采用NoC的目的是提高互联的灵活性并降低互联的复杂度。
对于基于NoC的MPSoCP架构多核片上系统有一种设计方法,叫做基于任务图的映射方法。其本质上是把需要完成的大型系统分割成若干任务,并将任务之间的依赖关系和通信量表示为图的形式。设计MPSoC的过程,可以看成是把任务图中的任务分配到对应的处理单元上的过程。如图6所示。
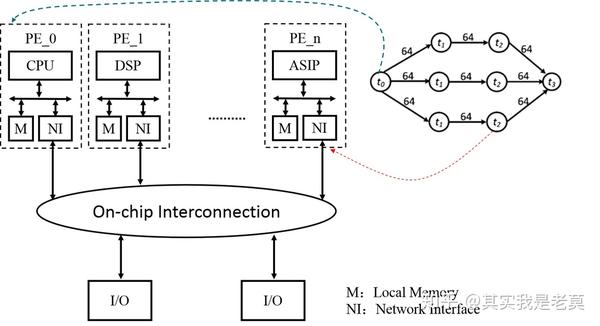
图6, 映射的示意图
通过映射可以比较灵活的调整任务在系统中的位置,从而起到减少流量和冲突的作用。
在设计阶段实施,映射被称为静态映射。既任务和PE静态的对应,最终的产出是一个专门的MPSoC设计方案。相应的NoC也可以进行定制化的优化。而在运行阶段映射则被称为动态映射,这种映射假设各个模块都是通用的PE。动态映射实际上在真实的应用中并不太常见,却是学术研究的“常客”。因为通过这种方法可以实现“轻量级”的研究,在不用太费劲的情况下就能得到一定的“研究成果”。
当然,现在的真是处理器中,CMP和MPSoC两种架构实际上是共存的。因此ARTERIS实际上同时支持这两种形式的NoC互联融合,具体方案如图7所示。

图7 ARTERIS公司给出的融合两种架构需求的互联方案[3]
图7中Ncore Cache Coherent Interconnect是带Cache一致性协议的互联,可以看出这是一个很明显的CMP架构的子系统。而 FlexNoC Non-coherent Interconnect则是用于互联多个独立的外围子系统或加速器系统的。
今天先暂时聊到这里,后续慢慢再更新。
参考文献
[1]Wentzlaff D, Griffin P, Hoffmann H, et al. On-chip interconnection architecture of the tile processor[J]. IEEE micro, 2007 (5): 15-31.
[2]Noethen B, Arnold O, Adeva E P, et al. 10.7 a 105gops 36mm 2 heterogeneous sdr mpsoc with energy-aware dynamic scheduling and iterative detection-decoding for 4g in 65nm cmos[C] 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), IEEE, 2014: 188-189.
[3]Arteris Announces Ncore Cache-Coherent Interconnect
END
知乎:https://zhuanlan.zhihu.com/p/65501500
推荐阅读
更多内容请关注其实我是老莫的网络书场专栏

