
为了不拖更,现在也只能把原来比较宏伟的写作计划往简化了去搞。(此处应该有一配图,但是找不到那张图了所以先暂时空在这里)目的呢还是能尽快的把片上网络的相关内容都给大家过一遍。
本次将重点来讨论一下芯片进入深亚微米以后片上互联出现的新情况和新需求,反过来再讨论片上网络研究的意义何在。
首先来看一个图
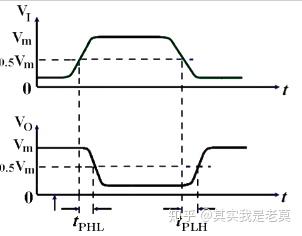
图1 数字信号的传播延迟
对于数字信号而言,其0到1/1到0的变换过程不是瞬间完成的,是需要有时间的。在图1中为我们展示了这样一个变化的过程。从输入变化(上面的波形)到引起输出变化(下面的波形)是有一个时间间隔的。图中的_t_PHL表示从高电平(通常表示逻辑1)到低电平(通常表示逻辑0)的变化时间间隔,而_t_PLH表示从低电平到高电平的变化时间间隔。这个时间间隔被称为延迟(Delay)。
延迟是由于底层器件的物理因素引起的,主要可以分为由于晶体管(Transistor)和互连线(wire)两种器件的物理性质引起的延迟。由于晶体管引起的延迟主要是晶体管的寄生参数(主要是电容)导致的充放电时间和晶体管自身导通关断的特性造成的。而线延迟则是由于连线非理想特性引入的阻容效应以及电磁信号在导体中传播速度的限制等因素引起的。具体的延迟分析涉及到大量的数学公式和微电子器件相关的知识点,在这里我就不详细解释了。有兴趣的同学可以去翻阅数字集成电路与系统设计相关的书籍。
在集成电路工艺没有进入深亚微米(100nm以下)之前,晶体管特性造成的延迟远远高于互连线造成的延迟。随着工艺不断的演进,晶体管的尺寸在不断缩小。因此带来的效果是晶体管的开关速度不断变快,在本系列的第一讲对此做过简要的分析和介绍。但工艺演进造成的特征尺寸缩小反过来是造成了互连线横截面和线之间的距离缩小。前者增大了等效电阻而后者则对于寄生电容有较大影响。而随着工艺的进步,单位面积上晶体管数目的增加,使得互连线的总长度和互连结构的复杂性是在不断提升的。这就使得互连线延迟在总延迟中所占比重越来越高,已经成为影响芯片性能提升的瓶颈。最典型的就是在最新的几代FPGA中,由于互连线造成延迟早已到了80%以上的比重。这是因为FPGA这种可编程器件互连结构更为复杂且为了满足可编程需求内部要插入可编程的互连晶体管节点,这使得其互连线延迟要高于普通的数字集成电路。
减少互连线延迟可以从材料、器件、电路优化和互连结构等多个方面来优化。例如,在130nm工艺以后,铜就取代了更为廉价的铝作为互连线的材料。这是由于铜有更小的电阻率和更强的抗电迁移能力,在降低连线延迟的同时延长了连线的使用寿命。又如Intel在其FPGA中采用了HyperFlex技术,在在FPGA的布线网络上,加入很多名为hyper-register的小型寄存器,这样可以把原本比较长的时序路径分割成多个较短的路径,从而达到频率提升的作用。
从物理设计的角度来看,片上网络的作用其实和hyper-register思想类似。即把较为复杂的“全局性”互连线划分为路由器之间的“局部性”连线,这样在布局布线时会显著的降低复杂性。除了将全局性连线“局部化”之外,片上网络还起到了协议的“封装”和“转换”的作用。这样可以使得大规模的集成电路被划分为若干个Block,每个Block内部实现自己的局部互连,当需要长距离互连的时候则通过片上网络。目前由于片上互连延迟已经发展到了难以控制的地步,FPGA也在开始使用片上网络来解决互连问题。从2014年左右由多伦多大学提出NoC-FPGA,到Xilinx最新推出的ACAP中使用了片上网络来解决多核异构互连。如何在FPGA中使用片上网络也一直在被探索和权衡。
综上所述,减少全局性长互连线,简化大规模集成电路的互连结构,最终减少大规模集成电路中越来越严重的互连线延迟是片上网络研究的第一个出发点。从这一点出发开展的研究主要关注片上网络的“物理层面”,也就是电气特性、信号传播和电路组织。发展到后期,各种新的片上通信技术也在被尝试引入到片上网络的研究中来。例如片上光通信的基础上,讨论如何引入光路设计和光器件的结构实现交换结构从而实现“光片上网络”的。在3D-IC的基础上讨论如何结合TSV的特性,实现3D片上网络的。以及我觉得无比扯淡的“无线片上网络”的。从这个视角出发开展研究的人一般具备很强的微电子/芯片设计背景,对于芯片自身的电气特性和物理现象了解得较为深刻。通常研究会从连接器件/电气特性/信号收发等“物理层”研究出发,配合一部分电路和架构设计。西安电子科技大学杨银堂教授团队就是这种研究思路的典型代表。由于我本人对这个方向研究的了解有限,所以就不继续展开讨论了。
当芯片规模大了以后,所遭遇的另一大问题就是多个模块相互通信时会产生较为严重的冲突。解决冲突的最普通办法就是把多个模块之间的通信从简单的总线互连向复杂的互连方式演进。
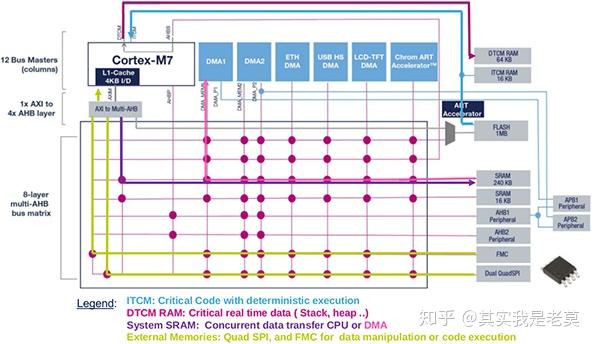
图2 ST公司的某款基于Cortex M7的SoC芯片
图2给出了ST公司所设计的某个基于Cortex M7的SoC芯片。这款新品中包含了多个主模块(Master)和多个从模块(Slave)。为了满足不同模块之间的互连需求,在主-从模块之间设计了交换矩阵这种连接方式。由于实现全互连开销过大且很多模块之间并无通信的需求,因此在这个交换矩阵中之采取了部分互连的方式,在图中打红圈的地方表示二者可以互连。可以看出,和各个从模块互连最多的不是处理器核而是DMA2。
虽然部分互连可以在一定程度上减少硬件复杂度,降低硬件电路面积。但是这种多对多的模式仍然会导致交换电路的面积过大、仲裁电路过于复杂等问题。当主模块超过8个以后,这种依靠交换矩阵的互连方式就将存在较大的困难。而在片上多核系统中,各种各样的主模块非常的多(包括但不限于各种处理器、各种DMA、各种接口控制器等)。这样直接使用交换矩阵会造成电路面积过大且仲裁电路过于复杂,最终会给物理设计造成困难并导致芯片整体的频率难以提升。
从逻辑结构看,片上网络就是把一个大的交换矩阵拆分成若干个具备独立仲裁的能力的路由器。这样可以极大的降低交换电路的复杂性。以一个常见的Mesh结构的片上网络为例,
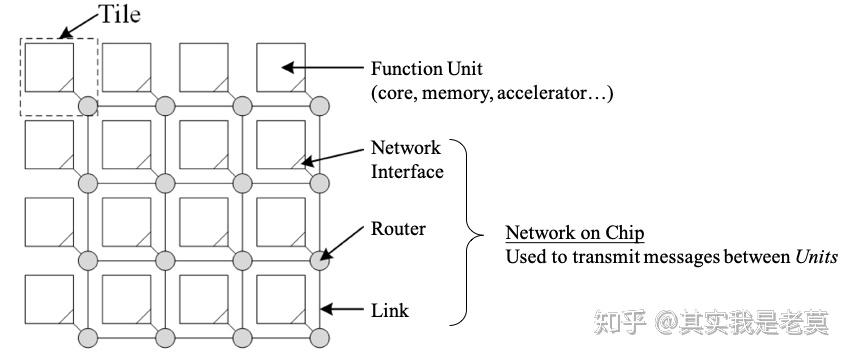
图3 一个典型Mesh结构的片上网络
从图3可以看出,一个典型的Mesh结构的片上网络,其中部的路由器为5个端口(与四周路由器接口并与本地的功能单元接口),而其边缘的路由器为4个(边路由器)或3个(角路由器)。相比于采用交换矩阵直连其端口数量大大降低,相应的交换电路和仲裁电路也更加简单。
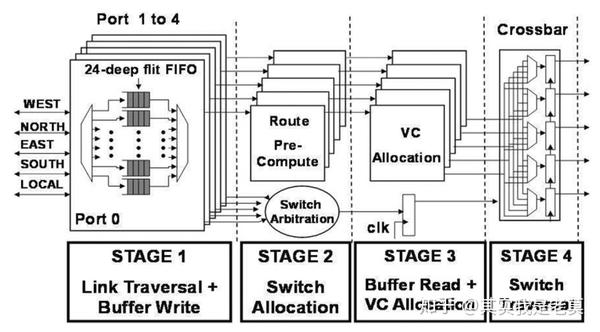
图4 Intel公司早期发布的5端口路由器微架构[1]
图4为Intel公司2011年在JSSC上报道的一种5端口片上路由器结构。在第4级的Crossbar中可以看出,5端口的路由器的每个输出端口通过一个4选1多路复用器和其它方向的输入端口互连。根据仲裁电路的仲裁结果,选择一个请求输出的输入端口的数据输出到输出端口。这样我们就把互连的复杂程度从图3的16选1降低到了4选1(实际上功能单元内部一般不止一个主模块,而这里仅做简单类比)。
当然,这样拆分也不是无代价的,不可避免的会引入一些问题。首要的问题就是如果使用交换矩阵互连,当两个通信的主从模块一定,可以通过直连的方式通信。而在片上网络中将交换矩阵拆分成多个路由器互连,本身存在一个“多跳”传输的问题,即有时候需要经过多个路由器才能到达目的地。而这就会引入一个如何知道应该通过拿几个路由器才能把信息传递到目的地的问题。解决这个问题的过程其实是和传统的通信网络解决的方法一致:依靠路由算法。因此,研究路由算法就成为了片上网络很主要的一个研究内容。但其实大家研究(灌水)多年,真正有用的也主要是就是XY路由算法及其简单的变形。这是因为XY路由算法实现简单高效,并且对于预防死锁比较有效(关于死锁的问题以后再讨论)。
图4虽然给出了一种经典的路由器结构,但实际上这个经典的路由器还可以继续拆分。图5给出了一种按X方向和Y方向拆分路由器的方法。
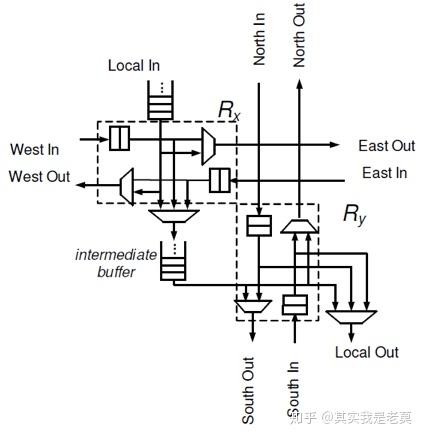
图5 按X方向和Y方向拆分路由器[2]
这是一篇发表在2009年Micro的论文,我个人认为其实这篇论文一出片上网络微架构的讨论应该进入一个新的时代了。对于按照Tile方式组织的片上多核系统,采用这种微架构将获得极好的性能。这种微架构采取了X方向入,Y方向出的策略。数据进入到X方向的子路由器,先沿着X方向传播。当传播到X方向的尽头以后再转入Y方向传播直到到达目的地。这种微架构和XY路由方式高度契合,因而路由算法实现极为简单。而且由于被拆分成为了两个方向的子路由器,使用2选1或3选1的多路复用器就可以实现数据包交换。从电路结构上被大大的简化了,在最后实现时可以跑出很高的时钟频率。而很多所谓的采用了很复杂的微架构的片上路由器真正到了电路实现环节根本跑不快,最终的实际性能是很难看的(造成这种情况的原因主要是因为搞Architecture的人发文章单位通常都是Cycle而不是s或者ms,而且一般电路综合的时候都不写状态机和控制逻辑)。在近年来Intel等公司在ISSCC等固态电路顶级会议和期刊上发表的片上互连结构,在很大程度上是借鉴和参考了这篇论文。
另一种“拆分”方法是从整个片上网络的构造上面来划分,面向专门的多核片上系统设计更为合理的拓扑结构并在此基础上定义更为合理和精细的片上网络微架构。这种专用的片上网络一般针对MPSoC,也可能是针对其它用途的芯片。考虑到后端设计的合理性,这种片上网络往往需要设计方法学上的创新,需要利用类似“综合”和“布局布线”的方法来生成一个符合实际互连需求的片上网络。这一部分我们后面讲到片上网络分层的时候再详细讨论。
那么现在再来简单总结一下,从另外一个视角来看片上网络实际上是再寻找一种片上多模块互连的结构,通过这种新的互连结构以较低的复杂度实现较高扩展性的互连方案。在寻找互连方案的时候需要考虑尽可能的降低数据包传输冲突并提升互连的性能。因此这是一种“自顶而下”的研究视角,更多的是从芯片整体架构和应用需求出发来讨论片上网络。其涉及到的研究内容主要包括了拓扑、路由算法以及路由器微架构设计。而在一个成功的片上网络设计中,这三者往往是缺一不可的。从这一视角开展研究的研究者往往是计算机体系结构出身,对于片上系统的整体架构和互连需求有较为清楚的认识。但比较讽刺的是,最终决定他们研究高度的限制条件往往是对于电路特性本身的理解。如果对于电路电气特性的理解不够深入,最后往往会做出一些“纸上谈兵”的结果。
从上面的分析我们可以看出,从“自顶向下”和“自底向上”两个方向都可以来研究片上网络。而有趣的是研究者自身不同的背景往往会决定研究的起点,但决定他们研究深度的往往却是他们是否具备补足自己知识背景盲点的能力。要想做出一个有深度的片上网络研究或者说设计出一个比较成功的片上网络电路,往往需要从物理设计到系统架构的综合能力。此外,片上网络是否具有实用性,还需要考虑到片上多核系统整体性的配合。要做好片上网络的研究和设计其实并不容易。当然,由于片上网络相对于数字集成电路的其他研究方向而已门槛较低(比信号处理电路要求的数学功底低,比处理器要求的系统规模小),所以在这个领域摸鱼的研究也不少。尤其在2010年以前,有大量无意义的垃圾论文存在。这一方面炒热了这个研究方向,另一方面也造就了过多的泡沫。反而是在浮躁中坚持下来的那几个做片上网络IP的创业公司最终看到了曙光。
当然,以上的研究方向分析主要还是从功能和性能设计的角度出发讨论片上网络的。片上网络本身作为一种特定的数字电路,也可以针对其自身的特点研究低功耗、可靠性以及可测试性等一般数字电路的研究内容(也是我这几年赖以“起家”的研究方向)。这些后面有机会我再慢慢介绍。
这次先介绍到这里,下次介绍片上网络的分层结构与实际的电路对应关系。让大家理解片上网络的“片上属性”和“网络属性”是如何影响其设计的。
参考文献
[1] SalihundamP , Jain S , Jacob T , et al. A 2 tb/s 64 mesh network for a single-chip cloud computer with dvfsin 45 nm cmos[J]. IEEE Journal of Solid-State Circuits, 2011, 46(4):757-766.
[2]Kim J . Low-cost router microarchitecture for on-chip networks[C]// 42st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO-42 2009), December 12-16, 2009, New York, New York, USA. ACM, 2009.
END
知乎:https://zhuanlan.zhihu.com/p/68393867
推荐阅读
更多内容请关注其实我是老莫的网络书场专栏

