
AudioLM 是 Google 的新模型,能够生成与提示风格相同的音乐。该模型还能够生成复杂的声音,例如钢琴音乐或人的对话。结果是它似乎与原版没有区别,这是十分让人惊讶的。

为什么生成音乐如此困难?
创作音乐并不是一件容易的事。生成音频信号(音乐、环境声音、人的讲话)需要多尺度的抽象。例如,音乐的结构必须经过长时间的分析,并且音乐是由许多相互作用的信号组成的。而人类的语言就个人言语来说本身就由很多不同的层次无论是简单的声音信号还是语音,也可以是韵律、句法、语法或语义等等。
生成音频的第一次尝试的重点是生成 MIDI 文件(在 2018 年使用transformer创建了一个有趣的项目,他们为钢琴生成 MIDI 音乐)。而另外一些研究则侧重于诸如文本到语音的任务,这类任务的研究表明了在人类交流中,停顿和变化以及其他信号是极其重要的。
比如现在的Alexa 或其他的语音机器人声音听起来依然不自然。尤其是早期,无论发音多么正确,听起来都不自然,给人一种诡异的感觉。
AudioLM
几天前,谷歌宣布发布一个新模型:“AudioLM: a Language Modeling Approach to Audio Generation”(2209.03143)。新模型能够通过听到音频生成后续音频(逼真的音乐和语音)。
近年来自然语言处理 (NLP) 领域有了很大的进步,语言模型已被证明在许多任务中非常有效。这些系统中有许多是基于transformer的,使用过它们的人都知道,最初的预处理步骤之一是标记化(将文本分解成更小的单元,并分配一个数值)。
AudioLM背后的关键理论是利用语言建模中的这些进步来生成音频,而无需使用注解数据进行训练。
AudioLM不需要转录或标记。作者收集了一个声音数据库将其直接输入到模型中。该模型将声音文件压缩为一系列片段(类似于标记)。然后将这些标记用作NLP模型(该模型使用相同的方法来学习各种音频片段之间的模式和关系)。与文本生成模型相同,AudioLM从提示生成声音。
这个结果是非常有趣的,因为声音更加自然。AudioLM似乎能够发现并重现人类音乐中存在的某些模式(比如敲击钢琴键时每个音符中包含的细微振动)。在下面的链接中,谷歌提供了一些例子,如果你想听的话:
https://google-research.githu...
AudioLM 已经接受过大量声音数据的训练,其中不仅包括音乐,还包括人声。因此,该模型可以生成人类产生的句子。该模型能够识别说话者的口音并添加停顿和感叹词。尽管模型生成的许多句子没有意义,但结果令人印象深刻。
将声音序列视为单词序列似乎是一种聪明的方法,但是仍然存在一些困难:
首先,音频数据速率更高,从而导致序列更长——虽然一个书面句子可以用几十个字符表示,但其音频波形通常包含数十万个值。其次,文本和音频之间存在一对多的关系。这意味着同一个句子可以由具有不同说话风格、情感内容和录音条件的不同说话者呈现。
OpenAI Jukebox 已经尝试过音频标记化方法,只是该模型产生了更多的伪影,而且声音听起来并不自然,而AudioLM中使用的标记器如下
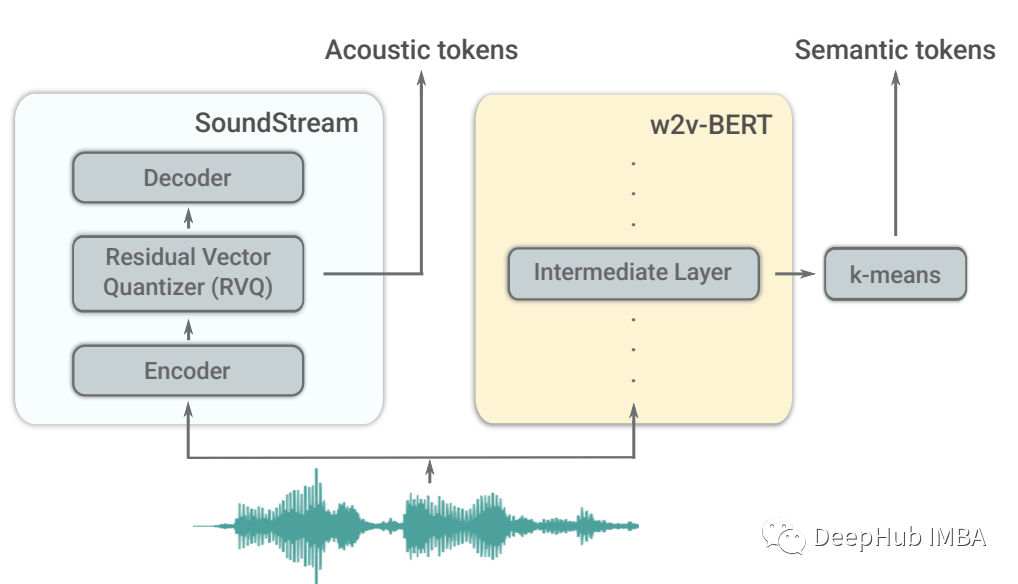
该模型由三个部分组成:
- 一个标记器模型,它将一系列声音映射到一个离散的标记序列中。这一步也减少了序列的大小(采样率减少了大约 300 倍)。
- 一个仅包含解码器的transformer ,可以最大化预测序列中下一个标记的可能性。该模型包含 12 层,16 个注意力头,嵌入维度为 1024,前馈层维度为 4096
- 一个将预测标记转换为音频标记的去标记器模型。
该模型接受了 60,000 小时英语演讲和 40,000 小时音乐的钢琴实验训练。
根据作者描述,听 AudioLM 生成的结果基本不会区分原始录音和生成结果的差异。由于该模型可用于对抗 AI 原则(deep fakes等),因此作者还构建了一个分类器,可以识别使用 AudioLM 制作的音频,并正在研究音频“水印”技术
一些想法
最近几个月,我们看到了几种模型如何能够生成图像(DALL-E,扩散模型),并且有诸如 GPT3 之类的模型能够生成文本序列。生成音频序列因为一些额外的困难所以发展的并不快,但我们似乎很快就会在这方面看到一些更大的进步。
谷歌刚刚推出了 AudioLM,一种能够使用音频提示(语音或钢琴)并生成延续的模型。然后提出扩散模型的同一小组又提出了 Harmonai(实际上,它使用了类似的稳定扩散模型的算法)。
这些技术在未来可用作视频和演示文稿的背景音乐、和其他创造性的工作。另一方面,这些技术可用于deep fakes、错误信息传播、诈骗等。
https://avoid.overfit.cn/post/62705af556bd4b3489e0753693bd1fe2
作者:Salvatore Raieli

