
特定领域知识图谱融合方案:文本匹配算法(Simnet、Simcse、Diffcse)
本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5423713?contributionType=1
文本匹配任务在自然语言处理中是非常重要的基础任务之一,一般研究两段文本之间的关系。有很多应用场景;如信息检索、问答系统、智能对话、文本鉴别、智能推荐、文本数据去重、文本相似度计算、自然语言推理、问答系统、信息检索等,但文本匹配或者说自然语言处理仍然存在很多难点。这些自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配。
0.前言:特定领域知识图谱融合方案
本项目主要围绕着特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案:文本匹配算法、知识融合学术界方案、知识融合业界落地方案、算法测评KG生产质量保障讲解了文本匹配算法的综述,从经典的传统模型到孪生神经网络“双塔模型”再到预训练模型以及有监督无监督联合模型,期间也涉及了近几年前沿的对比学习模型,之后提出了文本匹配技巧提升方案,最终给出了DKG的落地方案。这边主要以原理讲解和技术方案阐述为主,之后会慢慢把项目开源出来,一起共建KG,从知识抽取到知识融合、知识推理、质量评估等争取走通完整的流程。
0.1 详细细节参考第一篇项目:特定领域知识图谱融合方案:技术知识前置【一】-文本匹配算法
https://aistudio.baidu.com/aistudio/projectdetail/5398069?contributionType=1
0.2 特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案(重点!)
在前面技术知识下可以看看后续的实际业务落地方案和学术方案
关于图神经网络的知识融合技术学习参考下面链接:[PGL图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]](https://aistudio.baidu.com/ai...)
从入门知识到经典图算法以及进阶图算法等,自行查阅食用!
文章篇幅有限请参考专栏按需查阅:NLP知识图谱相关技术业务落地方案和码源
1.特定领域知识图谱知识融合方案(实体对齐):优酷领域知识图谱为例
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128614951
2.特定领域知识图谱知识融合方案(实体对齐):文娱知识图谱构建之人物实体对齐
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128673963
3.特定领域知识图谱知识融合方案(实体对齐):商品知识图谱技术实战
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128674429
4. 特定领域知识图谱知识融合方案(实体对齐):基于图神经网络的商品异构实体表征探索
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128674929
5.特定领域知识图谱知识融合方案(实体对齐)论文合集
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128675199
论文资料链接:两份内容不相同,且按照序号从小到大重要性依次递减
知识图谱实体对齐资料论文参考(PDF)+实体对齐方案+特定领域知识图谱知识融合方案(实体对齐)
知识图谱实体对齐资料论文参考(CAJ)+实体对齐方案+特定领域知识图谱知识融合方案(实体对齐)
6.知识融合算法测试方案(知识生产质量保障)
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128675698
1.传统深度模型:SimNet
短文本语义匹配(SimilarityNet, SimNet)是一个计算短文本相似度的框架,可以根据用户输入的两个文本,计算出相似度得分。 SimNet框架主要包括BOW、CNN、RNN、MMDNN等核心网络结构形式,提供语义相似度计算训练和预测框架, 适用于信息检索、新闻推荐、智能客服等多个应用场景解决语义匹配问题。
模型简介:
通过调用Seq2Vec中内置的模型进行序列建模,完成句子的向量表示。包含最简单的词袋模型和一系列经典的RNN类模型。
详情可以查看SimNet文件下的encoder文件 or 参考:https://github.com/PaddlePadd...
__all__ = ["BoWEncoder", "CNNEncoder", "GRUEncoder", "LSTMEncoder", "RNNEncoder", "TCNEncoder"]
| 模型 | 模型介绍 |
|---|---|
| BOW(Bag Of Words) | 非序列模型,将句子表示为其所包含词的向量的加和 |
| CNN | 序列模型,使用卷积操作,提取局部区域地特征 |
| GRU(Gated Recurrent Unit) | 序列模型,能够较好地解决序列文本中长距离依赖的问题 |
| LSTM(Long Short Term Memory) | 序列模型,能够较好地解决序列文本中长距离依赖的问题 |
| Temporal Convolutional Networks (TCN) | 序列模型,能够更好地解决序列文本中长距离依赖的问题 |
1.1 TCN:时间卷积网络
Temporal Convolutional Networks (TCN)时间卷积网络,18年提出的时序卷积神经网络模型用来解决时间序列预测的算法。其中,时序问题建模通常采用RNN循环神经网络及其相关变种,比如LSTM、GRU等,这里将卷积神经网络通过膨胀卷积达到抓取长时依赖信息的效果,TCN在一些任务上甚至能超过RNN相关模型。
作为一个新的序列分析 model 它的特点主要有两个:
- 其卷积网络层层之间是有因果关系的,意味着不会有“漏接”的历史信息或是未来数据的情况发生,即便 LSTM 它有记忆门,也无法完完全全的记得所有的历史信息,更何况要是该信息无用了就会逐渐被遗忘。
- 这个 model 的架构可以伸缩自如的调整成任何长度,并可以根据输出端需要几个接口就 mapping 成对应的样子,这点和 RNN 的框架意思相同,非常的灵活。
论文链接:https://arxiv.org/pdf/1803.01271.pdf
github链接:https://github.com/LOCUSLAB/tcn
时序问题的建模大家一般习惯性的采用循环神经网络(RNN)来建模,这是因为RNN天生的循环自回归的结构是对时间序列的很好的表示。传统的卷积神经网络一般认为不太适合时序问题的建模,这主要由于其卷积核大小的限制,不能很好的抓取长时的依赖信息。 但是最近也有很多的工作显示,特定的卷积神经网络结构也可以达到很好的效果,比如Goolgle提出的用来做语音合成的wavenet,Facebook提出的用来做翻译的卷积神经网络。这就带来一个问题,用卷积来做神经网络到底是只适用于特定的领域还是一种普适的模型? 本文就带着这个问题,将一种特殊的卷积神经网络——时序卷积网络(Temporal convolutional network, TCN)与多种RNN结构相对比,发现在多种任务上TCN都能达到甚至超过RNN模型。
1.1.1 因果卷积(Causal Convolution)
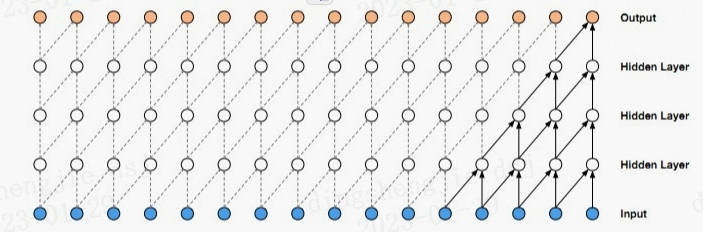
因果卷积可以用上图直观表示。 即对于上一层t时刻的值,只依赖于下一层t时刻及其之前的值。和传统的卷积神经网络的不同之处在于,因果卷积不能看到未来的数据,它是单向的结构,不是双向的。也就是说只有有了前面的因才有后面的果,是一种严格的时间约束模型,因此被成为因果卷积。
1.1.2 膨胀卷积(Dilated Convolution)
单纯的因果卷积还是存在传统卷积神经网络的问题,即对时间的建模长度受限于卷积核大小的,如果要想抓去更长的依赖关系,就需要线性的堆叠很多的层。为了解决这个问题,研究人员提出了膨胀卷积。如下图a所示。
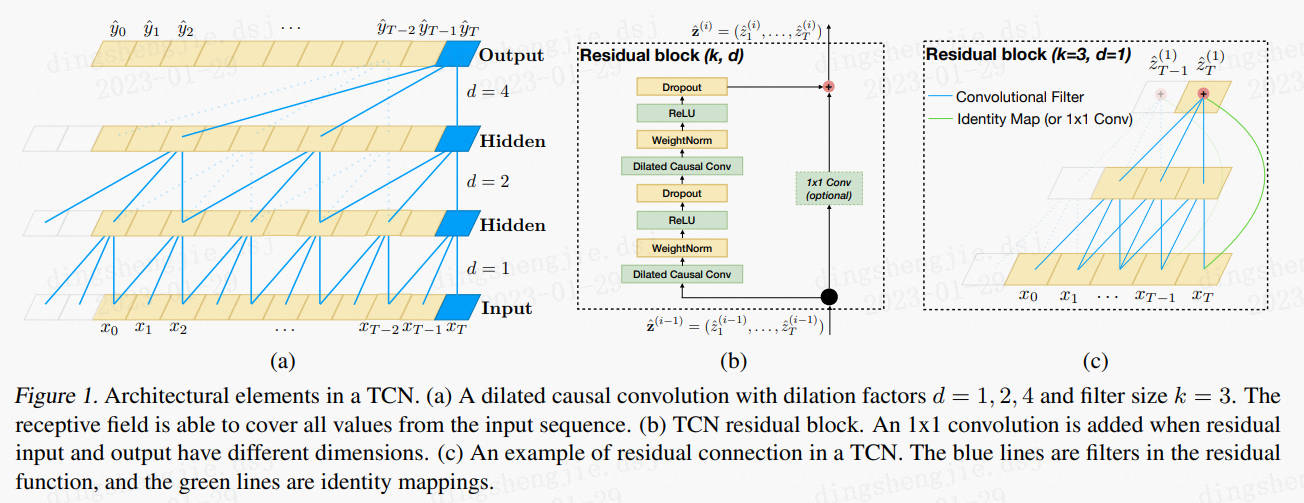
1.1.3 残差链接(Residual Connections)
上图b、c所示
残差链接被证明是训练深层网络的有效方法,它使得网络可以以跨层的方式传递信息。本文构建了一个残差块来代替一层的卷积。如上图所示,一个残差块包含两层的卷积和非线性映射,在每层中还加入了WeightNorm和Dropout来正则化网络。
1.1.4 小结分析
总体来讲,TCN模型上的创新并不是很大,因果卷积和扩展卷积也并不是本论文提出来,本文主要是将TCN的结构梳理了一下,相比于wavenet中的结构,去掉了门机制,加入了残差结构,并在很多的序列问题上进行了实验。实验效果如下:
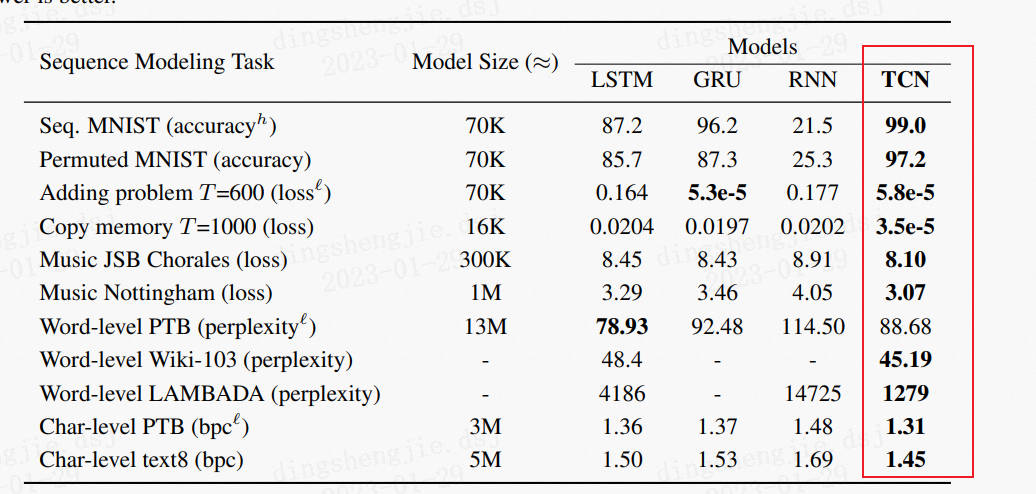
在多个任务上,都比标准的LSTM、GRU等效果好。
其余仿真结果:
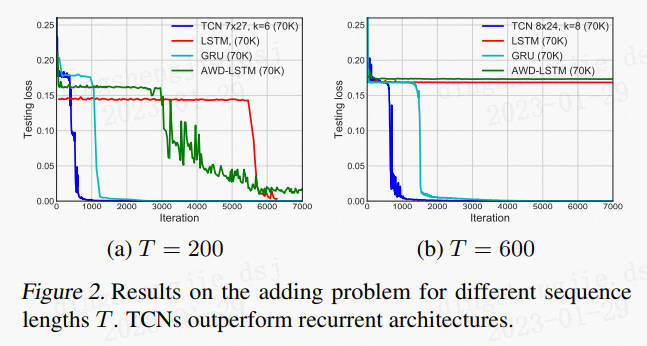
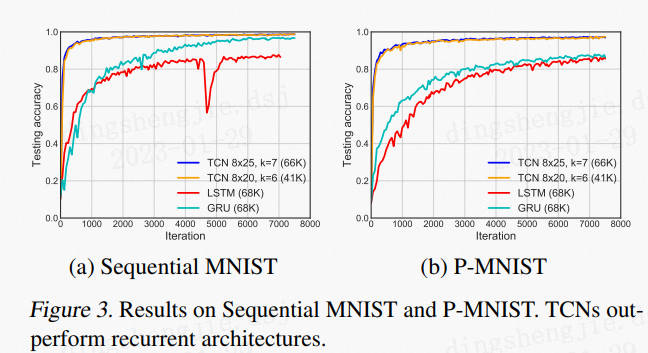

优点 :
(1)并行性。当给定一个句子时,TCN可以将句子并行的处理,而不需要像RNN那样顺序的处理。
(2)灵活的感受野。TCN的感受野的大小受层数、卷积核大小、扩张系数等决定。可以根据不同的任务不同的特性灵活定制。
(3)稳定的梯度。RNN经常存在梯度消失和梯度爆炸的问题,这主要是由不同时间段上共用参数导致的,和传统卷积神经网络一样,TCN不太存在梯度消失和爆炸问题。
(4)内存更低。RNN在使用时需要将每步的信息都保存下来,这会占据大量的内存,TCN在一层里面卷积核是共享的,内存使用更低。
缺点:
(1)TCN 在迁移学习方面可能没有那么强的适应能力。这是因为在不同的领域,模型预测所需要的历史信息量可能是不同的。因此,在将一个模型从一个对记忆信息需求量少的问题迁移到一个需要更长记忆的问题上时,TCN 可能会表现得很差,因为其感受野不够大。
(2)论文中描述的TCN还是一种单向的结构,在语音识别和语音合成等任务上,纯单向的结构还是相当有用的。但是在文本中大多使用双向的结构,当然将TCN也很容易扩展成双向的结构,不使用因果卷积,使用传统的卷积结构即可。
(3)TCN毕竟是卷积神经网络的变种,虽然使用扩展卷积可以扩大感受野,但是仍然受到限制,相比于Transformer那种可以任意长度的相关信息都可以抓取到的特性还是差了点。TCN在文本中的应用还有待检验。
参考链接:
https://blog.csdn.net/qq_27586341/article/details/90751794
1.2 模型训练与预测
1.2.1 数据准备
代码说明:
simnet/
├── model.py # 模型组网
├── predict.py # 模型预测
├── utils.py # 数据处理工具
├── train.py # 训练模型主程序入口,包括训练、评估程序运行时将会自动进行训练,评估,测试。同时训练过程中会自动保存模型在指定的save_dir中。 如:
checkpoints_simnet_lstm/
├── 0.pdopt
├── 0.pdparams
├── 1.pdopt
├── 1.pdparams
├── ...
└── final.pdparamsNOTE: 如需恢复模型训练,则init_from_ckpt只需指定到文件名即可,不需要添加文件尾缀。如--init_from_ckpt=checkpoints/0即可,程序会自动加载模型参数checkpoints/0.pdparams,也会自动加载优化器状态checkpoints/0.pdopt。
部分结果展示:
step 1790/1866 - loss: 0.2604 - acc: 0.9097 - 28ms/step
step 1800/1866 - loss: 0.2853 - acc: 0.9096 - 28ms/step
step 1810/1866 - loss: 0.3007 - acc: 0.9094 - 28ms/step
step 1820/1866 - loss: 0.2607 - acc: 0.9094 - 28ms/step
step 1830/1866 - loss: 0.3522 - acc: 0.9093 - 28ms/step
step 1840/1866 - loss: 0.2478 - acc: 0.9092 - 28ms/step
step 1850/1866 - loss: 0.2186 - acc: 0.9092 - 28ms/step
step 1860/1866 - loss: 0.1786 - acc: 0.9091 - 28ms/step
step 1866/1866 - loss: 0.2358 - acc: 0.9091 - 28ms/step
save checkpoint at /home/aistudio/SimNet/checkpoints_simnet_lstm/4
Eval begin...
step 10/69 - loss: 0.5209 - acc: 0.7336 - 31ms/step
step 20/69 - loss: 0.9080 - acc: 0.7352 - 34ms/step
step 30/69 - loss: 0.9188 - acc: 0.7352 - 34ms/step
step 40/69 - loss: 0.9328 - acc: 0.7393 - 34ms/step
step 50/69 - loss: 0.5988 - acc: 0.7398 - 32ms/step
step 60/69 - loss: 0.5592 - acc: 0.7367 - 32ms/step
step 69/69 - loss: 0.6573 - acc: 0.7384 - 30ms/step1.2.3 模型预测
启动预测
测试案例可以在output文件下test_1中有125000待预测结果,
{"query": "谁有狂三这张高清的", "title": "这张高清图,谁有", "label": ""}
{"query": "英雄联盟什么英雄最好", "title": "英雄联盟最好英雄是什么", "label": ""}
{"query": "这是什么意思,被蹭网吗", "title": "我也是醉了,这是什么意思", "label": ""}
{"query": "现在有什么动画片好看呢?", "title": "现在有什么好看的动画片吗?", "label": ""}
{"query": "请问晶达电子厂现在的工资待遇怎么样要求有哪些", "title": "三星电子厂工资待遇怎么样啊", "label": ""}
{"query": "文章真的爱姚笛吗", "title": "姚笛真的被文章干了吗", "label": ""}
{"query": "送自己做的闺蜜什么生日礼物好", "title": "送闺蜜什么生日礼物好", "label": ""}
{"query": "近期上映的电影", "title": "近期上映的电影有哪些", "label": ""}
{"query": "求英雄联盟大神带?", "title": "英雄联盟,求大神带~", "label": ""}
{"query": "如加上什么部首", "title": "给东加上部首是什么字?", "label": ""}
{"query": "杭州哪里好玩", "title": "杭州哪里好玩点", "label": ""}
{"query": "这是什么乌龟值钱吗", "title": "这是什么乌龟!值钱嘛?", "label": ""}
{"query": "心各有所属是什么意思?", "title": "心有所属是什么意思?", "label": ""}
{"query": "什么东西越热爬得越高", "title": "什么东西越热爬得很高", "label": ""}
{"query": "世界杯哪位球员进球最多", "title": "世界杯单界进球最多是哪位球员", "label": ""}
{"query": "韭菜多吃什么好处", "title": "多吃韭菜有什么好处", "label": ""}
{"query": "云赚钱怎么样", "title": "怎么才能赚钱", "label": ""}
{"query": "何炅结婚了嘛", "title": "何炅结婚了么", "label": ""}
{"query": "长的清新是什么意思", "title": "小清新的意思是什么", "label": ""}如果需要批量预测自行修改代码,data部分。
1.3 模型结果对比
| 模型 | train acc|dev acc |
| -------- | -------- | -------- |
| BoW | 0.8836 | 0.7297 |
|CNN | 0.9517 |0.7352 |
| GRU | 0.9124 | 0.7489 |
| LSTM | 0.9091 | 0.7384 |
| TCN | ---- | ---- |
| RNN | ---- | ---- |
关于RNN、TCN自行修改model文件即可,参考/home/aistudio/SimNet/encoder.py 修改/home/aistudio/SimNet/model.py
CNN:
- Data: ['淘宝上怎么用信用卡分期付款', '淘宝怎么分期付款,没有信用卡?'] Label: similar
- Data: ['石榴是什么时候成熟的?', '成熟的石榴像什么?'] Label: similar
- Data: ['为什么坐车玩手机会晕车', '为什么我坐车玩手机不晕车'] Label: similar
BOW:
- Data: ['淘宝上怎么用信用卡分期付款', '淘宝怎么分期付款,没有信用卡?'] Label: similar
- Data: ['石榴是什么时候成熟的?', '成熟的石榴像什么?'] Label: dissimilar
- Data: ['为什么坐车玩手机会晕车', '为什么我坐车玩手机不晕车'] Label: similar
GRU:
- Data: ['淘宝上怎么用信用卡分期付款', '淘宝怎么分期付款,没有信用卡?'] Label: similar
- Data: ['石榴是什么时候成熟的?', '成熟的石榴像什么?'] Label: dissimilar
- Data: ['为什么坐车玩手机会晕车', '为什么我坐车玩手机不晕车'] Label: similar
LSTM:
- Data: ['淘宝上怎么用信用卡分期付款', '淘宝怎么分期付款,没有信用卡?'] Label: dissimilar
- Data: ['石榴是什么时候成熟的?', '成熟的石榴像什么?'] Label: dissimilar
- Data: ['为什么坐车玩手机会晕车', '为什么我坐车玩手机不晕车'] Label: similar
抽样结果还是显而易见的,越新的算法一般越优越。
1.4篇幅有限更多程序代码请参考:
本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5423713?contributionType=1
2.无监督语义匹配模型 SimCSE
SimCSE 模型适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。
相关原理参考项目:https://aistudio.baidu.com/aistudio/projectdetail/5398069?contributionType=1 第4.2.4节 SimSCE 2021.04
下面将分别使用 LCQMC、BQ_Corpus、STS-B、ATEC 这 4 个中文语义匹配数据集的训练集作为无监督训练集(仅使用文本信息,不使用 Label),并且在各自数据集上的验证集上进行效果评估,评估指标采用 SimCSE 论文中采用的 Spearman 相关系数,Spearman 相关系数越高,表示模型效果越好. 压缩包名称:senteval_cn
- 代码结构说明
simcse/
├── model.py # SimCSE 模型组网代码
├── data.py # 无监督语义匹配训练数据、测试数据的读取逻辑
├── predict.py # 基于训练好的无监督语义匹配模型计算文本 Pair 相似度
├── train.sh # 模型训练的脚本
└── train.py # SimCSE 模型训练、评估逻辑2.1 模型训练与预测(LCQMC)
我们以中文文本匹配公开数据集 LCQMC 为示例数据集, 仅使用 LCQMC 的文本数据构造生成了无监督的训练数据。可以运行如下命令,开始模型训练并且在 LCQMC 的验证集上进行 Spearman 相关系数评估。
%cd SimCSE
!unset CUDA_VISIBLE_DEVICES
!python -u -m paddle.distributed.launch --gpus '0' \
train.py \
--device gpu \
--save_dir ./checkpoints_simcse/ \
--batch_size 64 \
--learning_rate 5E-5 \
--epochs 1 \
--save_steps 100 \
--eval_steps 100 \
--max_seq_length 64 \
--dropout 0.3 \
--train_set_file "/home/aistudio/LCQMC/train.txt" \
--test_set_file "/home/aistudio/LCQMC/dev.tsv"
部分结果展示:
[2023-02-01 10:22:15,087] [ INFO] - tokenizer config file saved in ./checkpoints_simcse/model_1900/tokenizer_config.json
[2023-02-01 10:22:15,088] [ INFO] - Special tokens file saved in ./checkpoints_simcse/model_1900/special_tokens_map.json
global step 1910, epoch: 1, batch: 1910, loss: 0.03640, speed: 0.95 step/s
global step 1920, epoch: 1, batch: 1920, loss: 0.03480, speed: 6.70 step/s
global step 1930, epoch: 1, batch: 1930, loss: 0.00650, speed: 7.08 step/s
global step 1940, epoch: 1, batch: 1940, loss: 0.00571, speed: 6.75 step/s
global step 1950, epoch: 1, batch: 1950, loss: 0.00966, speed: 6.28 step/s
global step 1960, epoch: 1, batch: 1960, loss: 0.01481, speed: 6.54 step/s
global step 1970, epoch: 1, batch: 1970, loss: 0.00974, speed: 6.42 step/s
global step 1980, epoch: 1, batch: 1980, loss: 0.03734, speed: 6.67 step/s
global step 1990, epoch: 1, batch: 1990, loss: 0.00716, speed: 6.68 step/s
global step 2000, epoch: 1, batch: 2000, loss: 0.01359, speed: 7.04 step/s
global step: 2000, spearman_corr: 0.4231, total_num: 8802配置的参数:
- infer_with_fc_pooler:可选,在预测阶段计算文本 embedding 表示的时候网络前向是否会过训练阶段最后一层的 fc; 建议关闭模型效果最好。
- dup_rate: 可选,word reptition 的比例,默认是0.32,根据论文 Word Repetition 比例采用 0.32 效果最佳。
- scale:可选,在计算 cross_entropy loss 之前对 cosine 相似度进行缩放的因子;默认为 20。
- dropout:可选,SimCSE 网络前向使用的 dropout 取值;默认 0.1。
- save_dir:可选,保存训练模型的目录;默认保存在当前目录checkpoints文件夹下。
- max_seq_length:可选,ERNIE-Gram 模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数;默认为128。
- batch_size:可选,批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。
- learning_rate:可选,Fine-tune的最大学习率;默认为5e-5。
- weight_decay:可选,控制正则项力度的参数,用于防止过拟合,默认为0.0。
- epochs: 训练轮次,默认为1。
- warmup_proption:可选,学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0.0。
- init_from_ckpt:可选,模型参数路径,热启动模型训练;默认为None。
- seed:可选,随机种子,默认为1000.
- device: 选用什么设备进行训练,可选cpu或gpu。如使用gpu训练则参数gpus指定GPU卡号。
程序运行时将会自动进行训练,评估。同时训练过程中会自动保存模型在指定的save_dir中。 如:
checkpoints/
├── model_100
│ ├── model_state.pdparams
│ ├── tokenizer_config.json
│ └── vocab.txt
└── ...NOTE:如需恢复模型训练,则可以设置init_from_ckpt, 如init_from_ckpt=checkpoints/model_100/model_state.pdparams。
我们用 LCQMC 的测试集作为预测数据, 测试数据示例如下:
谁有狂三这张高清的 这张高清图,谁有
英雄联盟什么英雄最好 英雄联盟最好英雄是什么
这是什么意思,被蹭网吗 我也是醉了,这是什么意思
现在有什么动画片好看呢? 现在有什么好看的动画片吗?
请问晶达电子厂现在的工资待遇怎么样要求有哪些 三星电子厂工资待遇怎么样啊2.2 评估效果
所有数据集可自行调整运行,超参数也可自行调优,下面展示部分结果:
- 中文语义匹配数据集效果
| 模型 | LCQMC | BQ_Corpus | STS-B | ATEC |
|---|---|---|---|---|
| SimCSE | 57.01 | 51.72 | 74.76 | 33.56 |
| SimCSE + WR | 58.97 | 51.58 | 78.32 | 33.73 |
- SimCSE + WR 策略在中文数据集训练的超参数设置如下:
| 数据集 | epoch | learning rate | dropout | dup rate |
|---|---|---|---|---|
| LCQMC | 1 | 5E-5 | 0.3 | 0.32 |
| BQ_Corpus | 1 | 1E-5 | 0.3 | 0.32 |
| STS-B | 8 | 5E-5 | 0.1 | 0.32 |
| ATEC | 1 | 5E-5 | 0.3 | 0.32 |
3.无监督语义匹配模型 DiffCSE
相关原理参考项目:https://aistudio.baidu.com/aistudio/projectdetail/5398069?contributionType=1 第4.2.9节 DiffSCE 2022.04
相比于 SimCSE 模型,DiffCSE模型会更关注语句之间的差异性,具有精确的向量表示能力。DiffCSE 模型同样适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。
代码结构:
DiffCSE/
├── model.py # DiffCSE 模型组网代码
├── custom_ernie.py # 为适配 DiffCSE 模型,对ERNIE模型进行了部分修改
├── data.py # 无监督语义匹配训练数据、测试数据的读取逻辑
├── run_diffcse.py # 模型训练、评估、预测的主脚本
├── utils.py # 包括一些常用的工具式函数
├── run_train.sh # 模型训练的脚本
├── run_eval.sh # 模型评估的脚本
└── run_infer.sh # 模型预测的脚本3.1 模型训练与预测 (LCQMC)
默认使用无监督模式进行训练 DiffCSE,模型训练数据的数据样例如下所示,每行表示一条训练样本:
全年地方财政总收入3686.81亿元,比上年增长12.3%。
“我对案情并不十分清楚,所以没办法提出批评,建议,只能希望通过质询,要求检察院对此做出说明。”他说。
据调查结果显示:2015年微商行业总体市场规模达到1819.5亿元,预计2016年将达到3607.3亿元,增长率为98.3%。
前往冈仁波齐需要办理目的地包含日喀则和阿里地区的边防证,外转沿途有一些补给点,可购买到干粮和饮料。3.2 模型训练与预测 (STS-B数据集)
数据集以及相关指标参考:Chinese-STS-B数据集,共包含0到5的6个标签,数字越大表示文本对越相似。在数据处理过程中,将标签为5的文本对当作匹配文本对(标记为1),将标签为0-2的文本对当作不匹配文本对(标记为0)。
https://zhuanlan.zhihu.com/p/388680608
https://zhuanlan.zhihu.com/p/454173790
部分展示
一个戴着安全帽的男人在跳舞。 一个戴着安全帽的男人在跳舞。 5
一个小孩在骑马。 孩子在骑马。 4
一个女人在弹吉他。 一个人在弹吉他。 2
一个女人在切洋葱。 一个人在切洋葱。 2
一个女人在吹长笛。 一个人在吹长笛。 2
一个男人在擦粉笔。 那人在擦粉笔。 5
一个女人抱着一个男孩。 一个女人怀了她的孩子。 2
女人剥土豆。 一个女人在剥土豆。 5
人们在玩板球。 男人们在打板球。 3
一个男人在弹吉他。 一个人在吹长笛。 1
美洲狮在追熊。 一只美洲狮正在追赶一只熊。 5
那人在弹吉他。 一个男人在弹吉他。 4
一个男人在找东西。 一个女人在切东西。 0
女孩对着麦克风唱歌。 这位女士对着麦克风唱歌。 2
一个男人在爬绳子。 一个男人爬上一根绳子。 5
小猫在吃东西。 小猫从盘子里吃东西。 4评测指标:斯皮尔曼等级相关系数Spearman's rank correlation coefficient把句子对分别输入模型编码得到embedding对后,计算embedding对的余弦距离。由于STS-B数据集是把句子对进行0~5的打分,所以评测指标采用斯皮尔曼等级相关系数。
3.3评估效果
| 模型 | LCQMC | STS-B |
|---|---|---|
| Simcse | 58.97% | 74.58 |
| Diffcse | 63.23% | 71.79(未调优) |
调优过程可以参考文章:
https://zhuanlan.zhihu.com/p/388680608
整体看出Diffcse优于Simcse
4. 总结
文本匹配任务在自然语言处理中是非常重要的基础任务之一,一般研究两段文本之间的关系。有很多应用场景;如信息检索、问答系统、智能对话、文本鉴别、智能推荐、文本数据去重、文本相似度计算、自然语言推理、问答系统、信息检索等,但文本匹配或者说自然语言处理仍然存在很多难点。这些自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配。
本项目主要围绕着特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案:文本匹配算法、知识融合学术界方案、知识融合业界落地方案、算法测评KG生产质量保障讲解了文本匹配算法的综述,从经典的传统模型到孪生神经网络“双塔模型”再到预训练模型以及有监督无监督联合模型,期间也涉及了近几年前沿的对比学习模型,之后提出了文本匹配技巧提升方案,最终给出了DKG的落地方案。这边主要以原理讲解和技术方案阐述为主,之后会慢慢把项目开源出来,一起共建KG,从知识抽取到知识融合、知识推理、质量评估等争取走通完整的流程。
5.篇幅有限更多程序代码请参考:
本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5423713?contributionType=1

