
0.前言
文本匹配任务在自然语言处理中是非常重要的基础任务之一,一般研究两段文本之间的关系。有很多应用场景;如信息检索、问答系统、智能对话、文本鉴别、智能推荐、文本数据去重、文本相似度计算、自然语言推理、问答系统、信息检索等,但文本匹配或者说自然语言处理仍然存在很多难点。这些自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配。
前置参考项目
1.特定领域知识图谱融合方案:技术知识前置【一】-文本匹配算法
https://blog.csdn.net/sinat_39620217/article/details/128718537
2.特定领域知识图谱融合方案:文本匹配算法Simnet、Simcse、Diffcse【二】
https://blog.csdn.net/sinat_39620217/article/details/128833057
3.特定领域知识图谱融合方案:文本匹配算法之预训练ERNIE-Gram单塔模型【三】
https://aistudio.baidu.com/aistudio/projectdetail/5456683?contributionType=1
NLP知识图谱项目合集(信息抽取、文本分类、图神经网络、性能优化等)
https://blog.csdn.net/sinat_39620217/article/details/128805154
2023计算机领域顶会以及ACL自然语言处理(NLP)研究子方向汇总
https://blog.csdn.net/sinat_39620217/article/details/128897539
本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5479941?contributionType=1
1.特定领域知识图谱融合方案:学以致用千言-问题匹配鲁棒性评测比赛验证
本比赛重点关注问题匹配模型在真实应用场景中的鲁棒性,多维度、细粒度检测模型的鲁棒性,以期推动语义匹配技术的发展。
https://aistudio.baidu.com/aistudio/competition/detail/130/0/leaderboard
1.1.赛题背景
问题匹配(Question Matching)任务旨在判断两个自然问句之间的语义是否等价,是自然语言处理领域一个重要研究方向。问题匹配同时也具有很高的商业价值,在信息检索、智能客服等领域发挥重要作用。
近年来,神经网络模型虽然在一些标准的问题匹配评测集合上已经取得与人类相仿甚至超越人类的准确性,但在处理真实应用场景问题时,性能大幅下降,在简单(人类很容易判断)的问题上无法做出正确判断(如下图),影响产品体验的同时也会造成相应的经济损失。
当前大多数问题匹配任务采用单一指标,在同分布的测试集上评测模型的好坏,这种评测方式可能夸大了模型能力,并且缺乏对模型鲁棒性的细粒度优劣势评估。本次评测关注问题匹配模型在真实应用场景中的鲁棒性,从词汇理解、句法结构、错别字、口语化、对话理解五个维度检测模型的能力,从而发现模型的不足之处,推动语义匹配技术的发展。本次竞赛主要基于千言数据集,采用的数据集包括哈尔滨工业大学(深圳)的LCQMC和BQ数据集、OPPO的小布对话短文本数据集以及百度的DuQM数据集,期望从多维度、多领域出发,全面评价模型的鲁棒性,进一步提升问题匹配技术的研究水平。
1.2 数据背景及说明
本次评测的问题匹配数据集旨在衡量问题匹配模型的鲁棒性,通过建立细粒度的评测体系,系统地评估模型能力的不足之处。本次的评测体系包含了词汇、句法、语用3大维度和14个细粒度的能力,具体分类体系如下图。本次评测数据来自问答搜索、问答型对话场景的真实问题,所有评测样本经过了人工筛选和语义匹配标注。
Corpus Category Subcategory Perturbation Example Label
DuQM Lexical Feature POS insert n. 高血压吃什么好 / 高血压孕妇吃什么好 N
insert v. 贵州旅游景点 / 贵州旅游景点预约 N
insert adj. 吃芒果上火吗 / 吃青芒果上火吗 N
insert adv. 为什么打嗝 / 为什么一直打嗝 N
replace n. 脂肪肝能吃猪肝吗 / 脂肪肝能吃猪肉吗 N
replace v. 下蹲膝盖疼 / 下跪膝盖疼 N
replace adj. 喉咙哑怎么办 / 喉咙疼怎么办 N
replace adv. 总是胸闷喘不上气 / 偶尔胸闷喘不上气 N
replace num. 血压130/100高吗 / 血压120/110高吗 N
replace quantifier 一枝花多少钱 / 一束花多少钱 N
replace phrase 如何提高自己的记忆力 / 如何增加自己的实力 N
Named Entity replace loc. 山西春节习俗 / 陕西春节习俗 N
replace org. 暨南大学分数线 / 济南大学分数线 N
replace person 王健林哪里人 / 王福林哪里人 N
replace product iphone 6多少钱 / iphone6x多少钱 N
Synonym replace n. 吃猕猴桃有什么功效 / 吃奇异果有什么功效 Y
replace v. 如何预防冻疮 / 如何防止冻疮 Y
replace adj. 膝盖冷什么原因 / 膝盖冰凉什么原因 Y
replace adv. 虾不能和什么一起吃 / 虾不能和什么同时吃 Y
Antonym replace adj. 只吃蔬菜会让皮肤变好吗 / 只吃蔬菜会让皮肤变差吗 N
Negation negate v. 为什么宝宝哭 / 为什么宝宝不哭 N
negate adj. 为什么苹果是红的 / 为什么苹果不是红的 N
neg.+antonym 激动怎么办 / 无法平静怎么办 Y
Temporal insert 2007年的修仙小说 / 2007年以前的修仙小说 N
replace 我在吃饭 / 我刚刚在吃饭 N
Syntactic Feature Symmetry swap 鱼和鸡蛋能一起吃吗 / 鸡蛋和鱼能一起吃吗 Y
Asymmetry swap 北京飞上海航班 / 上海飞北京航班 N
Negative Asymmetry swap + negate 男人比女人更高吗 / 女人比男人更矮吗 Y
Voice insert passive word 我撞了别人怎么办 / 我被别人撞了怎么办 N
Pragmatic Feature Misspelling replace 小孩上吐下泻 / 小孩上吐下泄 Y
Discourse Particle(Simple) insert or replace 人为什么做梦 / 那么人为什么做梦 Y
Discourse Particle(Complex) insert or replace 明孝陵景区怎么走 / 嗨 你知道明孝陵风景区怎么走吗 Y
OPPO Conversational Semantics - 是先生还是小姐猜一猜我 / 猜猜我是女生还是男生 Y训练集
包含四个文本相似度数据集,分别为哈尔滨工业大学(深圳)的 LCQMC、BQ Corpus、谷歌PAWS数据集以及OPPO小布对话短文本数据集。4个数据集的任务一致,都是判断两段文本在语义上是否匹配的二分类任务。
测试集
- 百度DuQM测试集:通过对搜索问答场景中的原始问题进行替换、插入等操作,并过滤掉真实场景中未出现过的问题,保证扰动后问题的自然性和流畅性,然后进行人工筛选和语义匹配标注,得到最终的评测集。
- OPPO小布对话短文本测试集:采样自OPPO语音助手小布的真实对话场景数据,进行人工筛选和语义匹配标注,得到最终的评测集。
数据统计信息
| 数据用途 | 数据集名称 | 内容 | 训练集大小 | 开发集大小 | 测试集大小 |
|---|---|---|---|---|---|
| 训练集(train) | LCQMC | (问题对, 标签) | 238,766 | 8,802 | 12,500 |
| 训练集(train) | BQ | (问题对, 标签) | 100,000 | 10,000 | 10,000 |
| 训练集(train) | OPPO小布助手短文本对话 | (问题对, 标签) | 167,174 | 10,000 - | |
| 训练集(train) | PAWS | (问题对, 标签) | 49,401 | 2000 | 2000 |
| 测试集(test) | DuQM、OPPO小布助手短文本对话 | (问题对) | - | - | 100,000 |
- 问题对:问题以中文为主,可能带有少量英文单词,采用UTF-8编码,未分词,两个问题之间使用\t分割;
- 标签: 标签为0或1,其中1代表问题对语义相匹配,0则代表不匹配,标签与问题对之间也用\t分割;
DuQM详细介绍,Github地址: https://github.com/baidu/DuRe...
1.3赛题任务
给定一组问题对,判断问题对在语义上是否匹配(等价),例如:
| 类型 | 问题1 | 问题2 | 标签(Label) |
|---|---|---|---|
| 匹配 | 胎儿什么时候入盆 | 胚胎什么时候入盆 | 1 |
| 不匹配 | 人民币怎么换港币 | 港币怎么换 人民币 | 0 |
评价指标
本次评测采用的评价指标为宏平均准确率(Macro-Accuracy),即先求得每个维度(词汇理解、句法结构、错别字、口语化、对话理解)的准确率(Accuracy),然后对所有维度的准确率求平均(Macro-Averaging),详细评分如下:
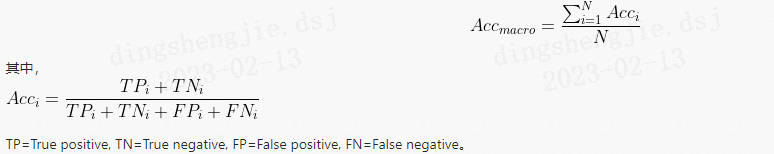
2.数据准备
本项目使用竞赛提供的 LCQMC、BQ、OPPO、paws 这 4 个数据集的训练集合集作为训练集,使用这 4 个数据集的验证集合集作为验证集。
运行如下命令生成本项目所使用的训练集和验证集,在参赛过程中可以探索采取其它的训练集和验证集组合,不需要和基线方案完全一致。
#合并所有数据集
!cat /home/aistudio/dataset/lcqmc/train.tsv /home/aistudio/dataset/BQ/train /home/aistudio/dataset/paws-x-zh/train.tsv /home/aistudio/dataset/oppo/train > train.txt
!cat /home/aistudio/dataset/lcqmc/dev.tsv /home/aistudio/dataset/BQ/dev /home/aistudio/dataset/paws-x-zh/dev.tsv /home/aistudio/dataset/oppo/dev > dev.txt
#查看合并后数据
import pandas as pd
dev = pd.read_csv('/home/aistudio/dev.txt', sep = '\t', header=None)
# dev.head()
dev.info
<bound method DataFrame.info of 0 1 2
0 开初婚未育证明怎么弄? 初婚未育情况证明怎么开? 1
1 谁知道她是网络美女吗? 爱情这杯酒谁喝都会醉是什么歌 0
2 人和畜生的区别是什么? 人与畜生的区别是什么! 1
3 男孩喝女孩的尿的故事 怎样才知道是生男孩还是女孩 0
4 这种图片是用什么软件制作的? 这种图片制作是用什么软件呢? 1
... ... ... ..
30797 可以定制充电提示音吗 定制充电提示音 0
30798 有未读信息吗点按两次即可激活 这个好消息 0
30799 丫鸭梦想家 打开丫鸭梦想家 0
30800 我要一口一口吃掉你 我要吃掉你 1
30801 你妈妈叫什么名字啊 我妈妈叫什么名字 0
[30802 rows x 3 columns]> #报错:ParserError: Error tokenizing data. C error: Expected 1 fields in line 28591, saw 2
#解决办法:加入 error_bad_lines=False
#如出现报错是BQ数据集导致的
train = pd.read_csv('/home/aistudio/train.txt',sep = '\t',header=None,error_bad_lines=False)
train.info
# train.head()
<bound method DataFrame.info of 0 1 2
0 喜欢打篮球的男生喜欢什么样的女生 爱打篮球的男生喜欢什么样的女生 1
1 我手机丢了,我想换个手机 我想买个新手机,求推荐 1
2 大家觉得她好看吗 大家觉得跑男好看吗? 0
3 求秋色之空漫画全集 求秋色之空全集漫画 1
4 晚上睡觉带着耳机听音乐有什么害处吗? 孕妇可以戴耳机听音乐吗? 0
... ... ... ..
555335 手机画质不清楚了怎么办 手机画质模糊怎么办 1
555336 我条件不行 我问一下都不行吗 0
555337 看我帅不帅 请问我长得帅吗 1
555338 什么本事最大成语 一个人本事很大打一成语的答案 0
555339 手机铃声设置 设置手机电话铃声 0
[555340 rows x 3 columns]>3.模型训练预测
代码结构说明:
├── model.py # 匹配模型组网
├── data.py # 训练样本的数据读取、转换逻辑
├── predict.py # 模型预测脚本,输出测试集的预测结果: 0,1
└── train.py # 模型训练评估!unset CUDA_VISIBLE_DEVICES
!python -u -m paddle.distributed.launch --gpus "0" train.py \
--train_set train.txt \
--dev_set dev.txt \
--device gpu \
--eval_step 500 \
--save_step 1000 \
--save_dir ./checkpoints \
--train_batch_size 128 \
--learning_rate 2E-5 \
--rdrop_coef 0.0 \
--epochs 3 \
--warmup_proportion 0.1
# 可支持配置的参数:
# train_set: 训练集的文件。
# dev_set:验证集数据文件。
# rdrop_coef:可选,控制 R-Drop 策略正则化 KL-Loss 的系数;默认为 0.0, 即不使用 R-Drop 策略。
# train_batch_size:可选,批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。
# learning_rate:可选,Fine-tune的最大学习率;默认为5e-5。
# weight_decay:可选,控制正则项力度的参数,用于防止过拟合,默认为0.0。
# epochs: 训练轮次,默认为3。
# warmup_proption:可选,学习率 warmup 策略的比例,如果 0.1,则学习率会在前 10% 训练 step 的过程中从 0 慢慢增长到 learning_rate, 而后再缓慢衰减,默认为 0.0。
# init_from_ckpt:可选,模型参数路径,热启动模型训练;默认为None。
# seed:可选,随机种子,默认为1000。
# device: 选用什么设备进行训练,可选cpu或gpu。如使用gpu训练则参数gpus指定GPU卡号。
# 程序运行时将会自动进行训练,评估。同时训练过程中会自动保存模型在指定的save_dir中。部分结果展示:
global step 12880, epoch: 3, batch: 4202, loss: 0.1993, ce_loss: 0.1993., kl_loss: 0.0000, accu: 0.9204, speed: 12.02 step/s
global step 12890, epoch: 3, batch: 4212, loss: 0.2516, ce_loss: 0.2516., kl_loss: 0.0000, accu: 0.9202, speed: 12.56 step/s
global step 12900, epoch: 3, batch: 4222, loss: 0.1872, ce_loss: 0.1872., kl_loss: 0.0000, accu: 0.9203, speed: 12.03 step/s
global step 12910, epoch: 3, batch: 4232, loss: 0.1950, ce_loss: 0.1950., kl_loss: 0.0000, accu: 0.9206, speed: 12.16 step/s
global step 12920, epoch: 3, batch: 4242, loss: 0.2245, ce_loss: 0.2245., kl_loss: 0.0000, accu: 0.9205, speed: 12.35 step/s
global step 12930, epoch: 3, batch: 4252, loss: 0.2398, ce_loss: 0.2398., kl_loss: 0.0000, accu: 0.9205, speed: 12.20 step/s
global step 12940, epoch: 3, batch: 4262, loss: 0.2234, ce_loss: 0.2234., kl_loss: 0.0000, accu: 0.9202, speed: 11.87 step/s
global step 12950, epoch: 3, batch: 4272, loss: 0.3007, ce_loss: 0.3007., kl_loss: 0.0000, accu: 0.9202, speed: 11.91 step/s
global step 12960, epoch: 3, batch: 4282, loss: 0.3511, ce_loss: 0.3511., kl_loss: 0.0000, accu: 0.9202, speed: 11.91 step/s
global step 12970, epoch: 3, batch: 4292, loss: 0.1860, ce_loss: 0.1860., kl_loss: 0.0000, accu: 0.9205, speed: 11.51 step/s
global step 12980, epoch: 3, batch: 4302, loss: 0.1380, ce_loss: 0.1380., kl_loss: 0.0000, accu: 0.9204, speed: 11.80 step/s
global step 12990, epoch: 3, batch: 4312, loss: 0.1749, ce_loss: 0.1749., kl_loss: 0.0000, accu: 0.9203, speed: 11.86 step/s
global step 13000, epoch: 3, batch: 4322, loss: 0.1800, ce_loss: 0.1800., kl_loss: 0.0000, accu: 0.9204, speed: 11.89 step/s
dev_loss: 0.33451, accuracy: 0.87163, total_num:30802训练过程中每一次在验证集上进行评估之后,程序会根据验证集的评估指标是否优于之前最优的模型指标来决定是否存储当前模型,如果优于之前最优的验证集指标则会存储当前模型,否则则不存储,因此训练过程结束之后,模型存储路径下 step 数最大的模型则对应验证集指标最高的模型, 一般我们选择验证集指标最高的模型进行预测。
checkpoints/
├── model_10000
│ ├── model_state.pdparams
│ ├── tokenizer_config.json
│ └── vocab.txt
└── ...# 训练完成后,在指定的 checkpoints 路径下会自动存储在验证集评估指标最高的模型,运行如下命令开始生成预测结果:
!unset CUDA_VISIBLE_DEVICES
!python -u \
predict.py \
--device gpu \
--params_path "./checkpoints_new2/model_14600/model_state.pdparams" \
--batch_size 128 \
--input_file "/home/aistudio/dataset/test.tsv" \
--result_file "predict_result1"
部分结果展示:
0
1
1
0
0
0
0
0
0
1
4.总结
4.1基线评测效果
本项目分别基于ERNIE-1.0、Bert-base-chinese、ERNIE-Gram 3 个中文预训练模型训练了单塔 Point-wise 的匹配模型, 基于 ERNIE-Gram 的模型效果显著优于其它 2 个预训练模型。
此外,在 ERNIE-Gram 模型基础上我们也对最新的正则化策略 R-Drop 进行了相关评测, R-Drop 策略的核心思想是针对同 1 个训练样本过多次前向网络得到的输出加上正则化的 Loss 约束。
官方开源了效果最好的 2 个策略对应模型的 checkpoint 作为本次比赛的基线方案: 基于 ERNIE-Gram 预训练模型 R-Drop 系数分别为 0.0 和 0.1 的 2 个模型, 用户可以下载相应的模型来复现我们的评测结果。
| 模型 | rdrop_coef | dev acc | test-A acc | test-B acc | learning_rate | epochs | warmup_proportion |
|---|---|---|---|---|---|---|---|
| ernie-1.0-base | 0.0 | 86.96 | 76.20 | 77.50 | 5E-5 | 5 | 0 |
| bert-base-chinese | 0.0 | 86.93 | 76.90 | 77.60 | 5E-5 | 5 | 0 |
| ernie-gram-zh | 0.0 | 87.66 | 80.80 | 81.20 | 5E-5 | 5 | 0 |
| ernie-gram-zh | 0.1 | 87.91 | 80.20 | 80.80 | 5E-5 | 5 | 0 |
| ernie-gram-zh | 0.2 | 87.47 | 80.10 | 81.00 | 5E-5 | 5 | 0 |
4.2 最终结果
| 模型 | rdrop_coef | dev acc | testacc | learning_rate | epochs | warmup_proportion |
|---|---|---|---|---|---|---|
| ernie-gram-zh | 0 | 87.16 | 73.56 | 2E-5 | 3 | 0.1 |
| ernie-gram-zh | 0.05 | 87.84 | 75.98 | 5E-5 | 5 | 0.1 |
| ernie-gram-zh | 0.05 | 87.21 | 75.92 | 5E-5 | 5 | 0 |
第一次结果:


发现问题:1.数据集切割 2.模型欠拟合 3.超参数调优(epochs、rdrop_coef、warmup_proption、weight_decay)等进行改进
第二次结果:
根据上表仅简单对参数和数据集进行重新组合得到的效果。可以明显看出模型提升空间有很大,最主要原因是训练轮数以及数据集分配导致模型泛化能欠佳,需要大家进行细致调优
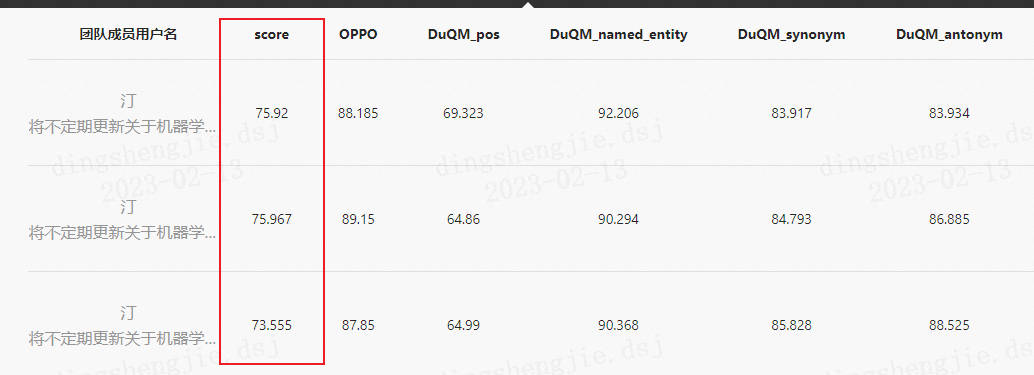
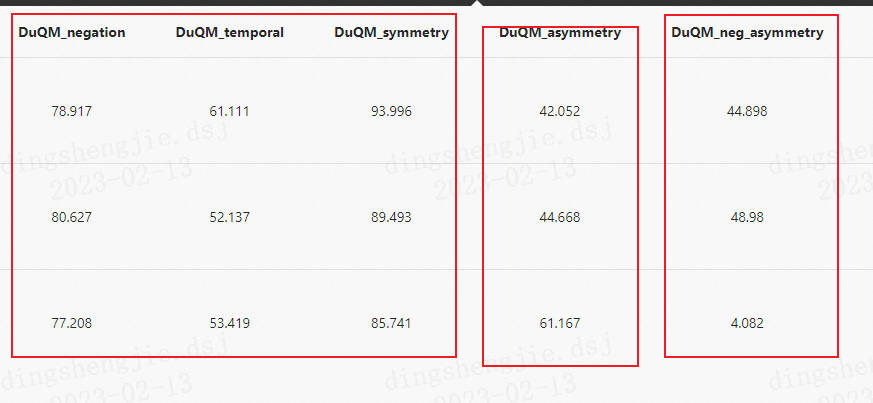
4.3 相关建议
推荐:
可以了解一些可解释学习相关知识,找出badcase,对模型进一步优化。如下图:

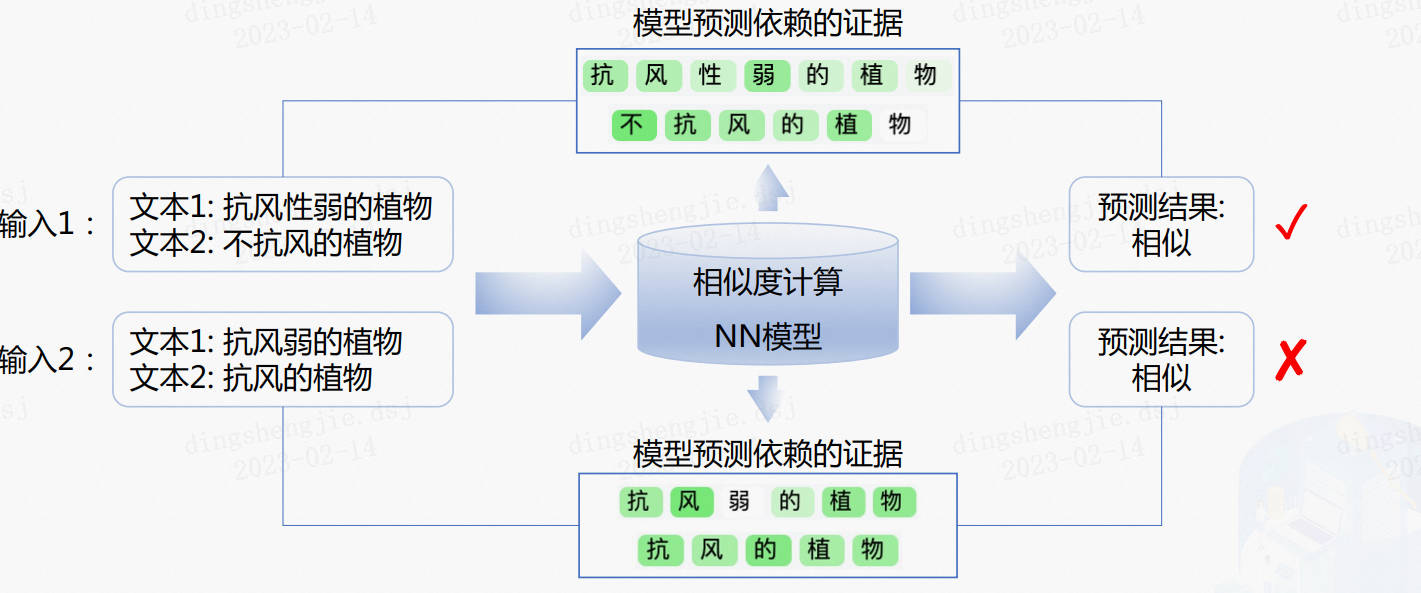
可以看到榜单上结果都是90+,这里我怀疑是测试数据标注后泄露导致,在同分布的测试集上评测模型的好坏,这种评测方式可能夸大了模型能力,并且缺乏对模型鲁棒性的细粒度优劣势评估。
如有错误还请指正。
5.特定领域知识图谱(DKG)融合方案推荐(重点!)
在前面技术知识下可以看看后续的实际业务落地方案和学术方案
关于图神经网络的知识融合技术学习参考下面链接:[PGL图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]](https://aistudio.baidu.com/ai...)
从入门知识到经典图算法以及进阶图算法等,自行查阅食用!
文章篇幅有限请参考专栏按需查阅:NLP知识图谱相关技术业务落地方案和码源
5.1特定领域知识图谱知识融合方案(实体对齐):优酷领域知识图谱为例
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128614951
5.2特定领域知识图谱知识融合方案(实体对齐):文娱知识图谱构建之人物实体对齐
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128673963
5.3特定领域知识图谱知识融合方案(实体对齐):商品知识图谱技术实战
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128674429
5.4特定领域知识图谱知识融合方案(实体对齐):基于图神经网络的商品异构实体表征探索
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128674929
5.5特定领域知识图谱知识融合方案(实体对齐)论文合集
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128675199
论文资料链接:两份内容不相同,且按照序号从小到大重要性依次递减
知识图谱实体对齐资料论文参考(PDF)+实体对齐方案+特定领域知识图谱知识融合方案(实体对齐)
知识图谱实体对齐资料论文参考(CAJ)+实体对齐方案+特定领域知识图谱知识融合方案(实体对齐)
5.6知识融合算法测试方案(知识生产质量保障)
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128675698

