
1.“AI Earth”人工智能创新挑战赛:助力精准气象和海洋预测Baseline[1]、NetCDF4使用教学、Xarray 使用教学,针对气象领域.nc文件读取处理
比赛官网:https://tianchi.aliyun.com/sp...

1.1 背景描述
聚焦全球大气海洋研究前沿方向,将人工智能技术应用到天气气候预测领域中,提高极端灾害性天气的预报水平,已成为整个行业研究的热点方向。发生在热带太平洋上的厄尔尼诺-南方涛动(ENSO)现象是地球上最强、最显著的年际气候信号,经常会引发洪涝、干旱、高温、雪灾等极端事件,2020年底我国冬季极寒也与ENSO息息相关。对于ENSO的预测,气候动力模式消耗计算资源大且存在春季预测障碍。基于历史气候观测和模拟数据,利用T时刻过去12个月(包含T时刻)的时空序列(气象因子),可以构建预测ENSO的深度学习模型,预测未来1-24个月的Nino3.4指数,这对极端天气与气候事件的预测具有重要意义。
本数据集由气候与应用前沿研究院ICAR提供。数据包括CMIP5/6模式的历史模拟数据和美国SODA模式重建的近100多年历史观测同化数据。每个样本包含以下气象及时空变量:海表温度异常(SST),热含量异常(T300),纬向风异常(Ua),经向风异常(Va),数据维度为(year,month,lat,lon)。训练数据提供对应月份的Nino3.4 index标签数据。测试用的初始场数据为国际多个海洋资料同化结果提供的随机抽取的n段12个时间序列,数据格式采用NPY格式保存。
1.2 历史气候观测和模拟数据集数据说明
项目链接以及码源见文末
- 训练数据
每个数据样本第一维度(year)表征数据所对应起始年份,对于CMIP数据共4645年,其中1-2265为CMIP6中15个模式提供的151年的历史模拟数据(总共:151年 15 个模式=2265);2266-4645为CMIP5中17个模式提供的140年的历史模拟数据(总共:140年 17 个模式=2380)。对于历史观测同化数据为美国提供的SODA数据。
其中每个样本第二维度(month)表征数据对应的月份,对于训练数据均为36,对应的从当前年份开始连续三年数据(从1月开始,共36月),比如:
SODA_train.nc中[0,0:36,:,:]为第1-第3年逐月的历史观测数据;
SODA_train.nc中[1,0:36,:,:]为第2-第4年逐月的历史观测数据;
…,
SODA_train.nc中[99,0:36,:,:]为第100-102年逐月的历史观测数据。
和
CMIP_train.nc中[0,0:36,:,:]为CMIP6第一个模式提供的第1-第3年逐月的历史模拟数据;
…,
CMIP_train.nc中[150,0:36,:,:]为CMIP6第一个模式提供的第151-第153年逐月的历史模拟数据;
CMIP_train.nc中[151,0:36,:,:]为CMIP6第二个模式提供的第1-第3年逐月的历史模拟数据;
…,
CMIP_train.nc中[2265,0:36,:,:]为CMIP5第一个模式提供的第1-第3年逐月的历史模拟数据;
…,
CMIP_train.nc中[2405,0:36,:,:]为CMIP5第二个模式提供的第1-第3年逐月的历史模拟数据;
…,
CMIP_train.nc中[4644,0:36,:,:]为CMIP5第17个模式提供的第140-第142年逐月的历史模拟数据。
其中每个样本第三、第四维度分别代表经纬度(南纬55度北纬60度,东经0360度),所有数据的经纬度范围相同。
- 训练数据标签
标签数据为Nino3.4 SST异常指数,数据维度为(year,month)。
CMIP(SODA)_train.nc对应的标签数据当前时刻Nino3.4 SST异常指数的三个月滑动平均值,因此数据维度与维度介绍同训练数据一致
注:三个月滑动平均值为当前月与未来两个月的平均值。
- 测试数据
测试用的初始场(输入)数据为国际多个海洋资料同化结果提供的随机抽取的n段12个时间序列,数据格式采用NPY格式保存,维度为(12,lat,lon, 4),12为t时刻及过去11个时刻,4为预测因子,并按照SST,T300,Ua,Va的顺序存放。
测试集文件序列的命名规则:test_编号_起始月份_终止月份.npy,如test_00001_01_12_.npy。
- 数据(Netcdf文件)读取方法
(1) https://www.giss.nasa.gov/too... panoply可视化文件
(2) Python中xarray/netCDF4 库

1.3 评估指标如下:
$Score = \frac{2}{3} \times accskill - RMSE$
其中$accskill$为相关性技巧评分,计算方式如下:
$accskill = \sum_{i=1}^{24} a \times ln(i) \times cor_i \ (i \leq 4, a = 1.5; 5 \leq i \leq 11, a = 2; 12 \leq i \leq 18, a = 3; 19 \leq i, a = 4)$
可以看出,月份$i$增加时系数$a$也增大,也就是说,模型能准确预测的时间越长,评分就越高。
是对于$N$个测试集样本在时刻$i$的预测值与实际值的相关系数,计算公式如下:
$cor_i = \frac{\sum_{j=1}^N(y_{truej}-\bar{y}{true})(y{predj}-\bar{y}{pred})}{\sqrt{\sum(y{truej}-\bar{y}{true})^2\sum(y{predj}-\bar{y}{pred})^2}}$
其中$y{truej}$为时刻$i$样本$j$的实际Nino3.4指数,$\bar{y}{true}$为该时刻$N$个测试集样本的Nino3.4指数的均值,$y{predj}$为时刻$i$样本$j$的预测Nino3.4指数,$\bar{y}_{pred}$为该时刻$N$个测试集样本的预测Nino3.4指数的均值。
为24个月份的累计均方根误差,计算公式为:
$RMSE = \sum_{i=1}^{24}rmse_i \ rmse = \sqrt{\frac{1}{N}\sum_{j=1}^N(y_{truej}-y_{predj})^2}$
ENSO现象会在世界大部分地区引起极端天气,对全球的天气、气候以及粮食产量具有重要的影响,准确预测ENSO,是提高东亚和全球气候预测水平和防灾减灾的关键。Nino3.4指数是ENSO现象监测的一个重要指标,它是指Nino3.4区(170°W - 120°W,5°S - 5°N)的平均海温距平指数,用于反应海表温度异常,若Nino3.4指数连续5个月超过0.5℃就判定为一次ENSO事件。本赛题的目标,就是基于历史气候观测和模式模拟数据,利用T时刻过去12个月(包含T时刻)的时空序列,预测未来1 - 24个月的Nino3.4指数。


# !unzip -d input /home/aistudio/data/data221707/enso_final_test_data_B_labels.zip2.气象海洋预测-气象数据分析常用工具
气象科学中的数据通常包含多个维度,本赛题中给出的数据就包含年、月、经度、纬度四个维度,为了便于数据的读取和操作,气象数据通常采用netCDF文件来存储,文件后缀为.nc。
对于以netCDF文件存储的气象数据,有两个常用的数据分析库,即NetCDF4和Xarray。首先将学习这两个库的基本对象和基本操作,掌握用这两个库读取和处理气象数据的基本方法。
2.1 NetCDF4使用教学
NetCDF4是NetCDF C库的Python模块,支持Groups、Dimensions、Variables和Attributes等对象类型及其相关操作。
- 安装NetCDF4
!pip install netCDF42.1.1 创建、打开和关闭netCDF文件
NetCDF4可以通过调用Dataset创建netCDF文件或打开已存在的文件,并通过查看data_model属性确定文件的格式。需要注意创建或打开文件后要先关闭文件才能再次调用Dataset打开文件。
- 创建netCDF文件
import netCDF4 as nc
from netCDF4 import Dataset
# Dataset包含三个输入参数:文件名,模式(其中'w', 'r+', 'a'为可写入模式),文件格式
test = Dataset('test.nc', 'r+', 'NETCDF4')
# test = Dataset('test.nc', 'w', 'NETCDF4')# - 打开已存在的netCDF文件
# 打开训练样本中的SODA数据
soda= Dataset("SODA_train.nc", "w", format="NETCDF4")
# soda = Dataset('SODA_train.nc')# - 查看文件格式
print(soda.data_model)NETCDF4
# - 关闭netCDF文件
soda.close()2.1.2 Groups
NetCDF4支持按层级的组(Groups)来组织数据,类似于文件系统中的目录,Groups中可以包含Variables、Dimenions、Attributes对象以及其他Groups对象,Dataset会创建一个特殊的Groups,称为根组(Root Group),类似于根目录,使用Dataset.createGroup方法创建的组都包含在根组中。
- 创建Groups
# 接受一个字符串参数作为Group名称
group1 = test.createGroup('group1')
group2 = test.createGroup('group2')# - 查看文件中的所有Groups
# 返回一个Group字典
test.groups{'group1': <class 'netCDF4._netCDF4.Group'>
group /group1:
dimensions(sizes):
variables(dimensions):
groups: group11,
'group2': <class 'netCDF4._netCDF4.Group'>
group /group2:
dimensions(sizes):
variables(dimensions):
groups: group21}
# - Groups嵌套
# 在group1和group2下分别再创建一个Group
group1_1 = test.createGroup('group1/group11')
group2_1 = test.createGroup('group2/group21')
test.groups
test.groups.values()dict_values([<class 'netCDF4._netCDF4.Group'>
group /group1:
dimensions(sizes):
variables(dimensions):
groups: group11, <class 'netCDF4._netCDF4.Group'>
group /group2:
dimensions(sizes):
variables(dimensions):
groups: group21])
# - 遍历查看所有Groups
# 定义一个生成器函数用来遍历所有目录树
def walktree(top):
values = top.groups.values()
yield values
for value in top.groups.values():
for children in walktree(value):
yield children
for groups in walktree(test):
for group in groups:
print(group)<class 'netCDF4._netCDF4.Group'>
group /group1:
dimensions(sizes):
variables(dimensions):
groups: group11
<class 'netCDF4._netCDF4.Group'>
group /group2:
dimensions(sizes):
variables(dimensions):
groups: group21
<class 'netCDF4._netCDF4.Group'>
group /group1/group11:
dimensions(sizes):
variables(dimensions): float64 ftemp(time, level, lat, lon)
groups:
<class 'netCDF4._netCDF4.Group'>
group /group2/group21:
dimensions(sizes):
variables(dimensions):
groups:
2.1.3 Dimensions
NetCDF4用维度来定义各个变量的大小,例如本赛题中训练样本的第二维度month就是一个维度对象,每个样本包含36个月的数据,因此month维度内的变量的大小就是36。变量是包含在维度中的,因此在创建每个变量时要先创建其所在的维度。
- 创建Dimensions
Dataset.createDimension方法接受两个参数:维度名称,维度大小。维度大小设置为None或0时表示无穷维度。
# 创建无穷维度
level = test.createDimension('level', None)
time = test.createDimension('time', None)
# 创建有限维度
lat = test.createDimension('lat', 180)
lon = test.createDimension('lon', 360)---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_2348/1064279341.py in <module>
1 # 创建无穷维度
----> 2 level = test.createDimension('level', None)
3 time = test.createDimension('time', None)
4 # 创建有限维度
5 lat = test.createDimension('lat', 180)
src/netCDF4/_netCDF4.pyx in netCDF4._netCDF4.Dataset.createDimension()
src/netCDF4/_netCDF4.pyx in netCDF4._netCDF4.Dimension.__init__()
src/netCDF4/_netCDF4.pyx in netCDF4._netCDF4._ensure_nc_success()
RuntimeError: NetCDF: String match to name in use
# - 查看Dimensions
test.dimensions# 查看维度大小
print(len(lon))
# Dimension对象存储在字典中
print(level)
# 判断维度是否是无穷
print(time.isunlimited())
print(lat.isunlimited())2.1.4 Variables
NetCDF4的Variables对象类似于Numpy中的多维数组,不同的是,NetCDF4的Variables变量可以存储在无穷维度中。
- 创建Variables
Dataset.createVariable方法接受的参数为:变量名,变量的数据类型,变量所在的维度。
变量的有效数据类型包括:'f4'(32位浮点数)、'f8'(64位浮点数)、'i1'(8位有符号整型)、'i2'(16位有符号整型)、'i4'(32位有符号整型)、'i8'(64位有符号整型)、'u1'(8位无符号整型)、'u2'(16位无符号整型)、'u4'(32位无符号整型)、'u8'(64位无符号整型)、's1'(单个字符)。
# 创建单个维度上的变量
times = test.createVariable('time', 'f8', ('time',))
levels = test.createVariable('level', 'i4', ('level',))
lats = test.createVariable('lat', 'f4', ('lat',))
lons = test.createVariable('lon', 'f4', ('lon',))
# 创建多个维度上的变量
temp = test.createVariable('temp', 'f4', ('time', 'level', 'lat', 'lon'))# - 查看Variables
print(temp)# 通过路径的方式在Group中创建变量
ftemp = test.createVariable('/group1/group11/ftemp', 'f8', ('time', 'level', 'lat', 'lon'))
# 可以通过路径查看变量
print(test['/group1/group11/ftemp'])
print(test['/group1/group11'])
# 查看文件中的所有变量
print(test.variables)2.1.5 Attributes
Attributes对象用于存储对文件或维变量的描述信息,netcdf文件中包含两种属性:全局属性和变量属性。全局属性提供Groups或整个文件对象的信息,变量属性提供Variables对象的信息,属性的名称可以自己设置,下面例子中的description和history等都是自定义的属性名称。
import time
# 设置对文件的描述
test.description = 'bogus example script'
# 设置文件的历史信息
test.history = 'Created' + time.ctime(time.time())
# 设置文件的来源信息
test.source = 'netCDF4 python module tutorial'
# 设置变量属性
lats.units = 'degrees north'
lons.units = 'degrees east'
levels.units = 'hPa'
temp.units = 'K'
times.units = 'hours since 0001-01-01 00:00:00.0'
times.calendar = 'gregorian'# 查看文件属性名称
print(test.ncattrs())
# 查看变量属性名称
print(test['lat'].ncattrs())
print(test['time'].ncattrs())
# 查看文件属性
for name in test.ncattrs():
print('Global attr {} = {}'.format(name, getattr(test, name)))2.1.6 写入或读取变量数据
类似于数组,可以通过切片的方式向变量中写入或读取数据。
- 向变量中写入数据
from numpy.random import uniform
nlats = len(test.dimensions['lat'])
nlons = len(test.dimensions['lon'])
print('temp shape before adding data = {}'.format(temp.shape))# 无穷维度的大小会随着写入的数据的大小自动扩展
temp[0:5, 0:10, :, :] = uniform(size=(5, 10, nlats, nlons))
print('temp shape after adding data = {}'.format(temp.shape))
print('levels shape after adding pressure data = {}'.format(levels.shape))- 读取变量中的数据
print(temp[1, 5, 100, 300])
print(temp[1, 5, 10:20, 100:110].shape)
# 可以用start:stop:step的形式进行切片
print(temp[1, 5, 10, 100:110:2])2.1.7 应用
我们尝试用NetCDF4来操作一下训练样本中的SODA数据。
# 打开SODA文件
soda = Dataset('SODA_train.nc')
# 查看文件格式
print('SODA文件格式:', soda.data_model)
# 查看文件中包含的对象
print(soda)# 查看维度和变量
print(soda.dimensions)
print(soda.variables)可以看到,SODA文件中包含year、month、lat、lon四个维度,维度大小分别是100、36、24和72,包含sst、t300、ua、va四个变量,每个变量都定义在(year, month, lat, lon)维度上。
# # 读取每个变量中的数据
# soda_sst = soda['sst'][:]
# print(soda_sst[1, 1, 1, 1])
# soda_t300 = soda['t300'][:]
# print(soda_t300[1, 2, 12:24, 36])
# soda_ua = soda['ua'][:]
# print(soda_ua[1, 2, 12:24:2, 36:38])
# soda_va = soda['va'][:]
# print(soda_va[5:10, 0:12, 12, 36])
# # 关闭文件
# soda.close()2.2 Xarray 使用教学
Xarray是一个开源的Python库,支持在类似Numpy的多维数组上引入维度、坐标和属性标记并可以直接使用标记的名称进行相关操作,能够读写netcdf文件并进行进一步的数据分析和可视化。
Xarray有两个基本的数据结构:DataArray和Dataset,这两个数据结构都是在多维数组上建立的,其中DataArray用于标记的实现,Dataset则是一个类似于字典的DataArray容器。
安装Xarray要求满足以下依赖包:
- Python(3.7+)
- setuptools(40.4+)
- Numpy(1.17+)
- Pandas(1.0+)
!pip install xarray2.2.1 创建DataArray
xr.DataArray接受三个输入参数:数组,维度,坐标。其中维度为数组的维度名称,坐标以字典的形式给维度赋予坐标标签。
import numpy as np
import pandas as pd
import xarray as xr
# 创建一个2x3的数组,将维度命名为'x'和'y',并赋予'x'维度10和20两个坐标标签
data = xr.DataArray(np.random.randn(2, 3), dims=('x', 'y'), coords={'x': [10, 20]})
data
# 也可以用Pandas的Series或DataFrame数据创建DataArray。# index名称会自动转换成坐标标签
xr.DataArray(pd.Series(range(3), index=list('abc'), name='foo'))# 查看数据
print(data.values)
# 查看维度
print(data.dims)
# 查看坐标
print(data.coords)
# 可以用data.attrs字典来存储任意元数据
print(data.attrs)- 索引
Xarray支持四种索引方式。
# 通过位置索引,类似于numpy
print(data[0, :], '\n')
# 通过坐标标签索引
print(data.loc[10], '\n')
# 通过维度名称和位置索引,isel表示"integer select"
print(data.isel(x=0), '\n')
# 通过维度名称和坐标标签索引,sel表示"select"
print(data.sel(x=10), '\n')- 属性
和NetCDF4一样,Xarray也支持自定义DataArray或标记的属性描述。
# 设置DataArray的属性
data.attrs['long_name'] = 'random velocity'
data.attrs['units'] = 'metres/sec'
data.attrs['description'] ='A random variable created as an example'
data.attrs['ramdom_attribute'] = 123
# 查看属性
print(data.attrs)# 设置维度标记的属性描述
data.x.attrs['units'] ='x units'
print('Attributes of x dimension:', data.x.attrs, '\n')- 计算
DataArray的计算方式类似于numpy ndarray。
data + 10np.sin(data)data.Tdata.sum()可以直接使用维度名称进行聚合操作。
data.mean(dim='x')DataArray之间的计算操作可以根据维度名称进行广播。
a = xr.DataArray(np.random.randn(3), [data.coords['y']])
b = xr.DataArray(np.random.randn(4), dims='z')
print(a, '\n')
print(b, '\n')
print(a+b, '\n')data - data.Tdata[:-1] - data[:1]- GroupBy
Xarray支持使用类似于Pandas的API进行分组操作。
labels = xr.DataArray(['E', 'F', 'E'], [data.coords['y']], name='labels')
labels# 将data的y坐标对齐labels后按labels的值分组求均值
data.groupby(labels).mean('y')# 将data的y坐标按labels分组后减去组内的最小值
data.groupby(labels).map(lambda x: x - x.min())2.2.2 绘图
Xarray支持简单方便的可视化操作,这里只做简单的介绍,更多的绘图方法感兴趣的同学们可以自行去探索。
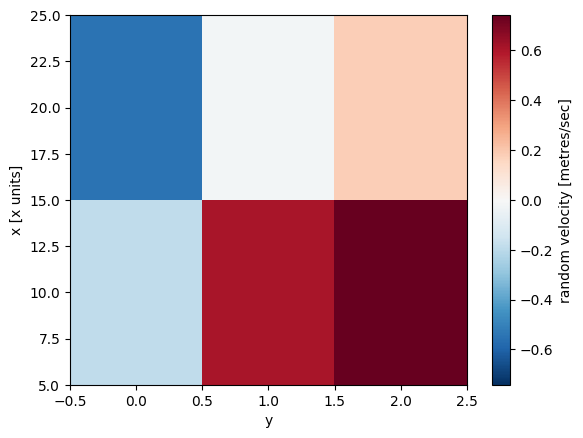
%matplotlib inline
data.plot()<matplotlib.collections.QuadMesh at 0x7f5bf77c4490>
2.2.3 与Pandas对象互相转换
Xarray可以方便地转换成Pandas的Series或DataFrame,也可以由Pandas对象转换回Xarray。
# 转换成Pandas的Series
series = data.to_series()
seriesx y
10 0 -0.188398
1 0.612211
2 0.741517
20 0 -0.547693
1 -0.021661
2 0.183370
dtype: float64
# Series转换成Xarray
series.to_xarray()# 转换成Pandas的DataFrame
df = data.to_dataframe(name='colname')
df2.2.4 Dataset
Dataset是一个类似于字典的DataArray的容器,可以看作是一个具有多为结构的DataFrame。对比NetCDF4库中的Dataset,我们可以发现两者的作用是相似的,都是作为容器用来存储其他的对象。
# 创建一个Dataset,其中包含三个DataArray
ds = xr.Dataset({'foo': data, 'bar': ('x', [1, 2]), 'baz': np.pi})
ds可以通过字典的方式或者点索引的方式来查看DataArray,但是只有采用字典方式时才可以进行赋值。
# 通过字典方式查看DataArray
print(ds['foo'], '\n')
# 通过点索引的方式查看DataArray
print(ds.foo)<xarray.DataArray 'foo' (x: 2, y: 3)>
array([[-0.18839763, 0.6122107 , 0.74151684],
[-0.547693 , -0.02166147, 0.18336995]])
Coordinates:
* x (x) int64 10 20
Dimensions without coordinates: y
Attributes:
long_name: random velocity
units: metres/sec
description: A random variable created as an example
ramdom_attribute: 123
<xarray.DataArray 'foo' (x: 2, y: 3)>
array([[-0.18839763, 0.6122107 , 0.74151684],
[-0.547693 , -0.02166147, 0.18336995]])
Coordinates:
* x (x) int64 10 20
Dimensions without coordinates: y
Attributes:
long_name: random velocity
units: metres/sec
description: A random variable created as an example
ramdom_attribute: 123
同样可以通过坐标标记来索引。
ds.bar.sel(x=10)2.2.5 读/写netCDF文件
# 写入到netcdf文件
ds.to_netcdf('xarray_test.nc')
# 读取已存在的netcdf文件
xr.open_dataset('xarray_test.nc')2.2.6 应用
尝试用Xarray来操作一下训练样本中的SODA数据。
# 打开SODA文件
soda = xr.open_dataset('SODA_train.nc')
# 查看文件属性
print(soda.attrs)
# 查看文件中包含的对象
print(soda){}
<xarray.Dataset>
Dimensions: ()
Data variables:
*empty*
# 查看维度和坐标
print(soda.dims)
print(soda.coords)Frozen(SortedKeysDict({}))
Coordinates:
*empty*
# # 读取数据
# soda_sst = soda['sst']
# print(soda_sst[1, 1, 1, 1], '\n')
# soda_t300 = soda['t300']
# print(soda_t300[1, 2, 12:24, 36], '\n')
# soda_ua = soda['ua']
# print(soda_ua[1, 2, 12:24:2, 36:38], '\n')
# soda_va = soda['va']
# print(soda_va[5:10, 0:12, 12, 36])项目链接以及码源见文末
更多文章请关注公重号:汀丶人工智能


