
深度学习应用篇-计算机视觉-OCR光学字符识别[7]:OCR综述、常用CRNN识别方法、DBNet、CTPN检测方法等、评估指标、应用场景
1.OCR综述
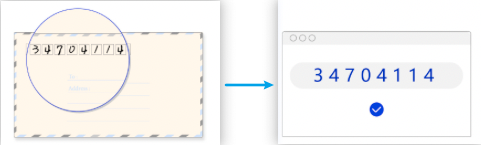
OCR(Optical Character Recognition,光学字符识别)是指对图像进行分析识别处理,获取文字和版面信息的过程,是典型的计算机视觉任务,通常由文本检测和文本识别两个子任务构成。
- 文字检测:将图片中的文字区域位置检测出来(如图1(b)所示);
- 文字识别:对文字区域中的文字进行识别(如图1(c)所示)。

- OCR发展历程
早在60、70年代,人们就开始对OCR进行研究。在研究的初期,主要以文字识别方法研究为主,而且识别的文字仅为0-9的数字。数字识别主要应用在识别邮件上的邮政编码。
在深度学习出现之前,传统算法(如积分投影、腐蚀膨胀、旋转等)在OCR领域占据主导地位。其标准的处理流程包括:图像预处理、文本行检测、单字符分割、单字符识别、后处理。

其中:
- 图像预处理主要是对图像的成像问题进行修正,包括几何变换(透视、扭曲、旋转等),去模糊、光线矫正等;
- 文本检测通常使用连通域、滑动窗口两个方向;
- 字符识别算法主要包括图像分类、模版匹配等。
受传统算法的局限性,传统OCR仅在比较规整的印刷文档上表现比较好,但在复杂场景(图像模糊、低分辨率、干扰信息)之下,文字检测、识别性能都不够理想。
自2012年AlexNet在ImageNet竞赛夺冠以来,深度学习方法开始在图像视频领域大幅超越传统算法,OCR领域也引入了深度学习,包括基于卷积神经网络(Convolutional Neural Network, CNN)来取代传统算法提取特征。深度学习OCR主要分为2步,首先是检测出图像中的文本行、接着进行文本识别。
1.1 OCR 常用检测方法
OCR文字检测就是将图片中的文字区域检测出来。
常用的基于深度学习的文字检测方法一般可以分为基于回归的、基于分割的两大类,当然还有一些将两者进行结合的方法。
1.1.1基于回归的方法
基于回归的方法又分为box回归和像素值回归:
1) box回归
采用box回归的方法主要有CTPN、Textbox系列和EAST
- 优点:对规则形状文本检测效果较好
- 缺点:无法准确检测不规则形状文本。
2) 像素值回归
采用像素值回归的方法主要有CRAFT和SA-Text,这类算法能够检测弯曲文本且对小文本效果优秀但是实时性能不够。
1.1.2 基于分割的算法
如PSENet,这类算法不受文本形状的限制,对各种形状的文本都能取得较好的效果,但是往往后处理比较复杂,导致耗时严重。目前也有一些算法专门针对这个问题进行改进,如DB,将二值化进行近似,使其可导,融入训练,从而获取更准确的边界,大大降低了后处理的耗时。
1.3 OCR常用识别方法
1.4 OCR常用评估指标
(1)检测阶段:先按照检测框和标注框的IOU评估,IOU大于某个阈值判断为检测准确。这里检测框和标注框不同于一般的通用目标检测框,是采用多边形进行表示。检测准确率:正确的检测框个数在全部检测框的占比,主要是判断检测指标。检测召回率:正确的检测框个数在全部标注框的占比,主要是判断漏检的指标。
(2)识别阶段: 字符识别准确率,即正确识别的文本行占标注的文本行数量的比例,只有整行文本识别对才算正确识别。
(3)端到端统计: 端对端召回率:准确检测并正确识别文本行在全部标注文本行的占比; 端到端准确率:准确检测并正确识别文本行在 检测到的文本行数量 的占比; 准确检测的标准是检测框与标注框的IOU大于某个阈值,正确识别的的检测框中的文本与标注的文本相同。
1.5 应用场景
在日常生活中,文字内容无处不在,根据拍摄的内容,自动分析图像中的文字信息已经成为人们的广泛诉求。而通过深度学习技术,可以自动的定位文字区域,并且学习包含丰富语义信息的特征,识别出图像中的文字内容。当前这一技术已经广泛应用于金融、交通等各行各业中。
- 通用场景:办公文档、广告图、表格、手写数字、自然场景图等;
- 卡证:身份证、银行卡、营业执照、名片等;
- 汽车:车牌、驾驶证、合格证等;
- 财务票据:火车票、飞机票、银行支票等;
- 医疗票据:医疗发票、病例首页等;
- ...
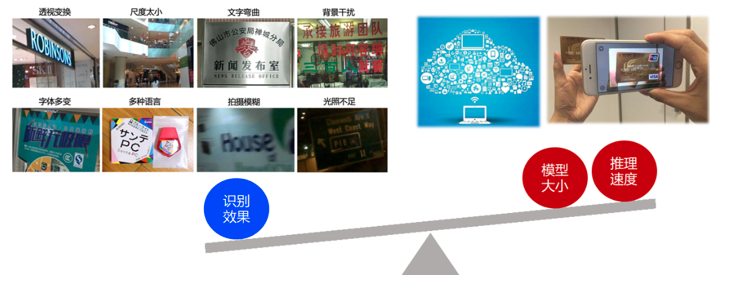
1.6 OCR面临的挑战
对应到OCR技术实现问题上,则一般面临仿射变换、尺度问题、光照不足、拍摄模糊等技术难点; 另外OCR应用常对接海量数据,因此要求数据能够得到实时处理;并且OCR应用常部署在移动端或嵌入式硬件,而端侧的存储空间和计算能力有限,因此对OCR模型的大小和预测速度有很高的要求。
2.OCR检测方法
2.1 CTPN
CTPN(Connectionist Text Proposal Network)[1]是目标检测算法Faster R-CNN 的改进算法,用于文字检测。CTPN根据文本区域的特点做了专门的优化:
- 使用更加符合自然场景文字检测特点的anchor(相比于物体,文字尺寸小);
- 引入RNN用于处理场景文字检测中存在的序列特征;
- 引入Side-refinement(边界优化)提升文本框边界预测精度。
2.1.1CTPN模型结构
CTPN采用的方法是将文本行分割成一个个小块(长度是固定的),然后去检测这些小块,最后使用一种文本行构造法将所有块连起来,如 图1 所示。

<center>
图1 CTPN 序列特征</center>
CTPN网络结构如 图2 所示:
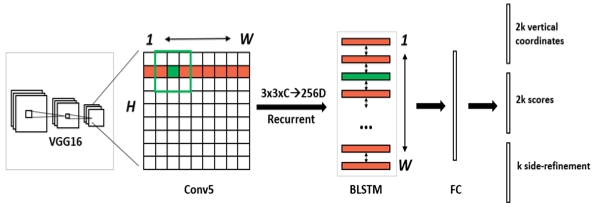
<center>
图2 CTPN网络结构示意图</center>
整个检测分为5步:
1)准备数据集、并获取锚点anchor;
2)输入图片,经过backbone(用VGG16的前5个Conv stage,即Conv5),提取图片feature map。经过VGG16之后得到的特征图长宽是原图的1/16,通道是512。
3)在Conv5得到的feature map上再做卷积核大小为3,步长为1的卷积,进一步提取特征,用于预测当前卷积核所在位置k个anchor对应的类别信息、位置信息。其中,C表示通道数。
4)把每一行的所有窗口对应的3*3*C的特征输入到BiLSTM(双向LSTM)网络中,提取文字的序列特征,这时候得到的特征是图像特征和序列特征的融合。
5)将第三步得到的特征输入到FC全连接层,并将FC层特征输入两个分类或者回归层中。
CTPN任务1的输出是 $$ 2k $$ ,用于预测候选区域box的起始$$y$$坐标和高度$$h$$ ;任务2是用来对前景和背景两个任务的分类评分;任务3是 $$k$$个输出的side-refinement的偏移(offset)预测。
2.1.2 模型loss
CTPN 的 loss 分为三部分:
- Ls:预测每个 anchor 是否包含文本区域的classification loss,采用交叉熵损失;
- Lv:文本区域中每个 anchor 的中心y坐标cy与高度h的regression loss,采用Smooth L1;
Lo:文本区域两侧 anchor 的中心x坐标cx 的regression loss,采用Smooth L1。
公式如下:
$L(s_{i},V_{j},O_{k})=\frac{1}{N_{s}}\sum\limits_{i}L^{cl}_{S}(S_{i},S^{*}_{i})+\frac{λ_{1}}{N_{v}}\sum\limits_{j}L^{re}_{V}(V_{j},V^{*}_{j})+\frac{λ_{2}}{N_{o}}\sum\limits_{k}L^{re}_{O}(O_{k},O^{*}_{k})$
其中,i 表示预测的所有pn_anchor中的第 i 个 ,Ns表示 pn_anchor 的数量。
j 表示 IoU>0.5 的所有 pn_anchor 中的第 j 个,$v_{j}$为判断有文本的pn_anchor,Nv 表示和 groudtruth 的 vertical IOU>0.5 的 pn_anchor 的数量。λ1 为多任务的平衡参数,一般取值1.0。
Lo 只针对位于在文本区域的左边界和右边界的pn_anchor,来精修边缘。
2.1.3 模型缺点
- 对于非水平的文本的检测效果不好
- 参考文献
[1] Detecting Text in Natural Image with Connectionist Text Proposal Network
2.2 EAST
CTPN在水平文本的检测方面效果比较好,但是对于竖直方向的文本,或者多方向的文本,CTPN检测就很差。然而,在实际场景中,我们会遇到多种存在竖直方向文本的情况,例如很多书本封面的文本,如 图1 所示。

<center>图1 多方案文本示意图</center>>
因此,很多学者也提出了各种改进方法,其中,比较经典一篇的就是旷世科技在2017年提出来的EAST[1]模型。
2.2.1 EAST 模型结构
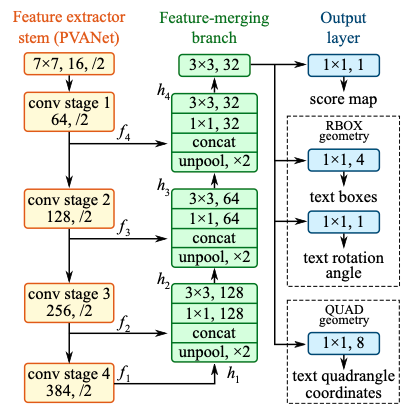
EAST的网络结构总共包含三个部分:Feature extractor stem(特征提取分支), Feature-merging branch(特征合并分支) 以及 Output layer(输出层),网络结构如 图2 所示:
<center>图2 EAST网络结构示意图</center>
每一部分网络结构:
1)特征提取分支
- 使用backbone网络提取特征,论文默认backbone为PVANet;
也可以使用其他的卷积网络,比如VGG16等
2)特征合并分支
由于在一张图片中,各个文字尺寸大小不一致,所以需要融合不同层次的特征图,小文字的预测需要用到底层的语义信息,大文字的预测要用到高层的语义信息。
- 上一步提取的feature map f1被最先送入unpool层(将原特征图放大2倍);
- 然后与前一层的feature map f2进行拼接;
- 接着依次送入卷积核大小为1×1和3×3的卷积层,核数通道数随着层递减,依次为128,64,32;
- 重复上面三个步骤2次;
- 最后将经过一个卷积核大小为3×3,核数通道数为32个的卷积层;
3)输出层
网络层的输出包含文本得分和文本形状,根据不同的文本形状又分为RBOX和QUAD两种情况:
- RBOX:主要用来预测旋转矩形的文本,包含文本得分和文本形状(AABB boundingbox 和rotate angle),一共有6个输出,这里AABB分别表示相对于top,right,bottom,left的偏移;
- QUAD:用来预测不规则四边形的文本,包含文本得分和文本形状(8个相对于corner vertices的偏移),一共有9个输出,其中QUAD有8个,分别为 $$(x_{i},y_{i}),i\in[1,2,3,4]$$。
2.2.2 模型loss
EAST损失函数由两部分组成,具体公式如下:
$$L=L_{s}+λ_{g}L_{g}$$
其中,$$L_{s}$$为分数图损失,$$L_{g}$$为几何损失,$$λ_{g}$$表示两个损失之间的重要性。
分数图损失
使用类平衡交叉熵:
$$L_{s} = -\beta Y^{*}log(\hat{Y})-(1-\beta)(1-Y^*)log(1-\hat{Y})$$
几何损失
- RBOX:IOU损失
$$L_{AABB} = -log\frac{\hat{R}\cap R^*}{\hat{R}\cup R^*}$$
选转角度损失计算:$L_{\theta}(\hat{\theta},\theta^*) = 1-cos(\hat{\theta}-\theta^*)$
$$L_g=L_{AABB} + \lambda L_\theta$$
其中$\hat{R}$代表预测的AABB几何形状,$R^*$为其对应的地面真实情况。
- QUAD:smooth L1损失
$$ L_g = \min\limits_{\tilde{Q}\in P_{Q^*}} \sum\limits_{c_i \in C_Q, \tilde c_i \in C_\tilde Q}\frac{smoothed_{L_1}(c_i, \tilde{c}_i)}{8*N_{Q^*}} $$
其中$N_{Q^*}$是四边形的短边长度,公式如下:
$$N_{Q^*} = \min\limits_{i=1}^{4} D(p_i, p_{(i mode 4)+1})$$
2.2.3 模型优缺点
优点
- 可以检测多方向的文本
缺点
- 不能检测弯曲文本
- 参考文献
[1] EAST: An Efficient and Accurate Scene Text Detector
2.3 DBNet
一般分割算法流程是先通过网络输出文本分割的概率图,然后使用预先设定好的阈值将概率图转换为二值图,最后使用后处理操作将像素级的结果转换为检测结果。然而,这样就会使得算法性能很大程度上取决于二值化时阈值的选择。
DBNet[1]对这个流程进行了优化,对每个像素点进行自适应二值化,二值化的阈值由网络学习得到,彻底将二值化这一步骤加入到网络里一起训练,这样最终的输出图对于阈值就会非常鲁棒。
2.3.1 模型输入标签
DB网络中,网络的输出为3个部分:概率图、阈值图和近似二值图:
- 概率图:图中每个像素点的值为该位置属于文本区域的概率。
- 阈值图:图中每个像素点的值为该位置的二值化阈值。
- 二值图:由概率图和阈值图通过DB算法计算得到,图中像素的值为0或1。
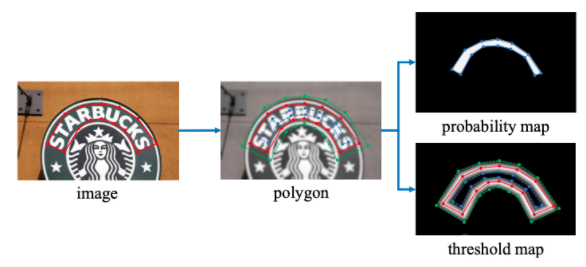
在构造损失函数时,我们需要获取对应的真实标签。阈值图的标签$$G_{d}$$,概率图标签$$G_{s}$$。DB网络中,标签的获取方式参考了PSENet(Progressive Scale Expansion Network,渐进式尺度扩展网络)中的方法,使用扩张和收缩的方式分别获取上述两个真实标签。标签的构造过程如 图1 所示:
<center>
图1 DB标签构造示意图</center>
在该方法中,对于一幅文字图像,文本区域的每个多边形使用一组线段$G=\{S_k\}^n_{k=1}$来进行描述,n为线段个数。如 图1 所示,$n=14$。
概率图标签$G_s$的获取方法使用了Vatti clipping算法,该算法常用于收缩多边形,其中,收缩的偏移量D可以使用周长L和面积A计算得到,公式如下:
$$ D = \frac{A(1-r^2)}{L} $$
其中,r为收缩因子,实验中根据经验设置为0.4。
在阈值图标签$G_d$的计算中,首先使用概率图标签$G_s$的计算过程中得到的偏移量D进行多边形的扩充,然后计算$G_d$与$G_s$之间的像素到原始框最近边的归一化距离,最后将其中的值进行缩放,得到的就是最终的阈值图标签$G_d$。
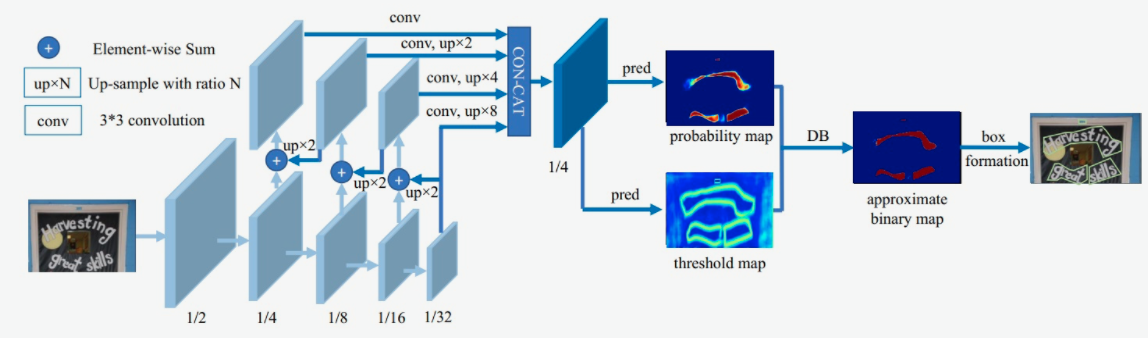
DB文本检测模型使用了标准的FPN结构,网络结构如 图2 所示。
<center>
图2 DB模型网络结构示意图</center>
- 第一模块:使用CNN网络,对输入图像提取特征,得到特征图,本实验使用的骨干网络是轻量化网络MobileNetv3,同时使用了FPN结构,获取多尺度的特征,在本实验中,我们提取4个不同尺度下的特征图做拼接。
- 第二模块:使用一个卷积层和两个转置卷积层的结构获取预测的概率图和阈值图;
- 第三模块:使用DB方法获取近似二值图。
注:这里的DB方法和本文的DB模型是有差别的,本文提出的DB方法为可微二值化(Differentiable Binarization),接下来将会详细解释。
在传统的图像分割算法中,我们获取概率图后,会使用标准二值化(Standard Binarize)方法进行处理,将低于阈值的像素点置0,高于阈值的像素点置1,公式如下:
$$ B_{i,j}=\left{
\begin{aligned}
1 , if P_{i,j} >= t ,\
0 , otherwise
\end{aligned}
\right.$$
但是标准的二值化方法是不可微的,所以也就无法放入到网络中进行优化。因此,本文中提出了可微二值化(Differentiable Binarization),简称DB方法。可微二值化也就是将标准二值化中的阶跃函数进行了近似,使用如下公式进行代替:
$$\hat{B} = \frac{1}{1 + e^{-k(P_{i,j}-T_{i,j})}}$$
其中,P是上文中获取的概率图,T是上文中获取的阈值图,k是增益因子,在实验中,根据经验选取为50。
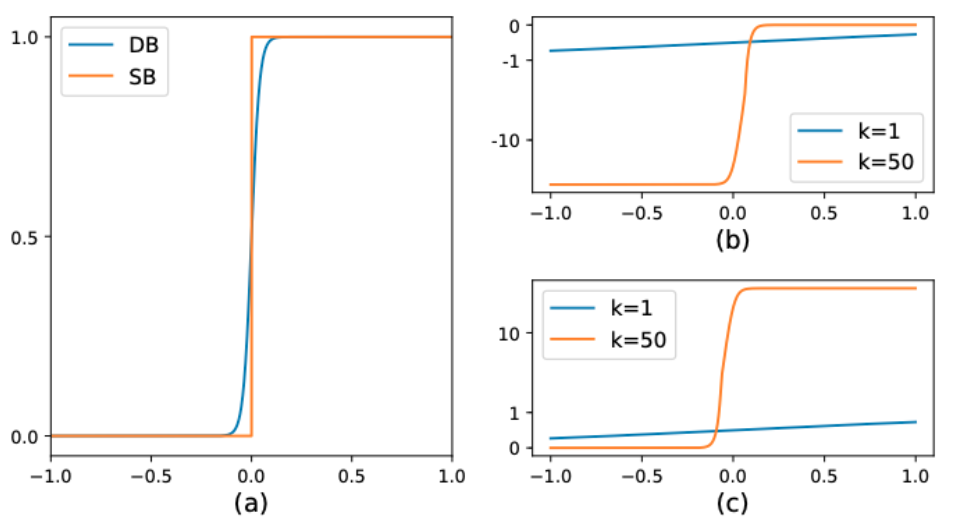
标准二值化和可微二值化的对比图如 图3(a) 所示。
之所以DB方法会改善算法性能,我们可以在反向传播时梯度的计算上进行观察。当使用交叉熵损失时,正负样本的loss分别为 $l_+$ 和 $l_-$
$$ l_+ = -log(\frac{1}{1 + e^{-k(P_{i,j}-T_{i,j})}})$$
$$l_- = -log(1-\frac{1}{1 + e^{-k(P_{i,j}-T_{i,j})}})$$
我们对输入x求偏导,则会得到:
$$\frac{\delta{l_+}}{\delta{x}} = -kf(x)e^{-kx}$$
$$\frac{\delta{l_-}}{\delta{x}} = -kf(x)$$
此时,由于有了增强因子k,错误预测对梯度的影响也就被放大了,从而可以促进模型的优化过程并产生更为清晰的预测结果。图3(b) 中,$x<0$ 的部分为正样本预测为负样本的情况,可以看到,增益因子k将梯度进行了放大;而 图3(c) 中$x>0$ 的部分为负样本预测为正样本的情况,梯度同样也被放大了。
<center>
图3 DB算法示意图</center>
在训练阶段,使用3个预测图与真实标签共同完成损失函数的计算以及模型训练;在预测阶段,只需要使用概率图,通过一系列的后处理方式即可获得最终的预测结果。
由于网络预测的概率图是经过收缩后的结果,所以在后处理步骤中,使用相同的偏移值将预测的多边形区域进行扩张,即可得到最终的文本框。
2.3.2 模型loss
由于训练阶段获取了3个预测图,所以在损失函数中,也需要结合这3个预测图与它们对应的真实标签分别构建3部分损失函数。总的损失函数的公式定义如下:
$$L = L_b + \alpha \times L_s + \beta \times L_t$$
其中,$L$为总的损失,$L_b$为近似二值图的损失,使用 Dice 损失;$L_s$为概率图损失,使用带 OHEM 的 Dice 损失;$L_t$为阈值图损失,使用预测值和标签间的$L_1$距离。其中,$\alpha$和$\beta$为权重系数。
接下来分析这3个loss:
1)首先是Dice Loss,Dice Loss是比较预测结果跟标签之间的相似度,常用于二值图像分割。
$dice\_loss = 1 - \frac{2 \times intersection\_area}{total\_area}$
2)其次是MaskL1 Loss,是计算预测值和标签间的$L_1$距离
2)最后是Balance Loss,是带OHEM的Dice Loss,目的是为了改善正负样本不均衡的问题。OHEM为一种特殊的自动采样方式,可以自动的选择难样本进行loss的计算,从而提升模型的训练效果。
2.3.3 模型优缺点
优点
- 可以同时检测水平、多方向和弯曲文字;
- 在性能和速度上都获取不错的效果。
- 参考文献
[1] Real-time Scene Text Detection with Differentiable Binarization
3.OCR识别方法:CRNN
传统的文本识别方法需要先对单个文字进行切割,然后再对单个文字进行识别。本实验使用的是图像文本识别的经典算法CRNN[1]。CRNN是2015年被提出的,到目前为止还是被广泛应用。该算法的主要思想是认为文本识别其实需要对序列进行预测,所以采用了预测序列常用的RNN网络。算法通过CNN提取图片特征,然后采用RNN对序列进行预测,最终使用CTC方法得到最终结果。
3.1 CRNN模型结构
CRNN的主要结构包括基于CNN的图像特征提取模块以及基于多层双向LSTM的文字序列特征提取模块。CRNN的网络结构如 图1 所示:
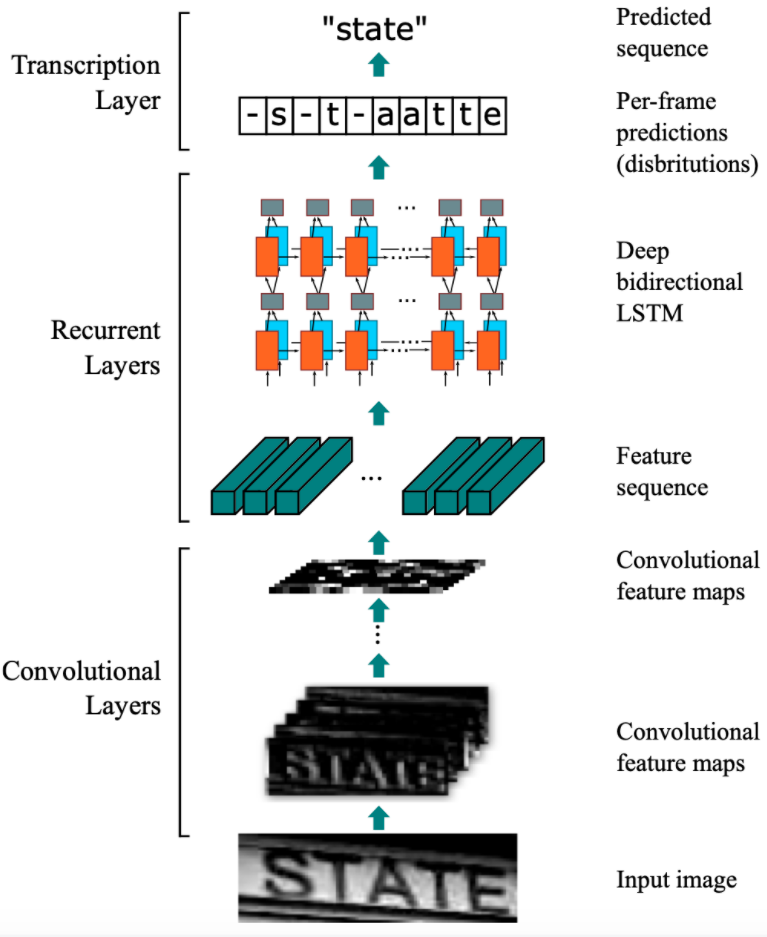
<center>图1 CRNN模型网络结构示意图</center>
1)第一模块:使用CNN网络,对输入图像进行特征提取,从而得到特征图。本实验使用的CNN网络同样是轻量化网络MobileNetv3,其中输入图像的高度统一设置为32,宽度可以为任意长度,经过CNN网络后,特征图的高度缩放为1;
2)第二模块:Im2Seq,将CNN获取的特征图变换为RNN需要的特征向量序列的形状;
3)第三模块:使用双向LSTM(BiLSTM)对特征序列进行预测,学习序列中的每个特征向量并输出预测标签分布。这里其实相当于把特征向量的宽度视为LSTM中的时间维度;
4)第四模块:使用全连接层获取模型的预测结果;
5)第五模块:CTC转录层,解码模型输出的预测结果,得到最终输出。
3.2 模型loss
为了解决预测标签与真实标签无法对齐的问题,这里使用了CTC loss进行模型,具体参考:CTC算法
3.3模型优缺点
优点
- 可以进行端到端的训练;
- 可以进行不定长文本的识别;
- 模型简单,效果好。
缺点
- 受CTC算法对速度的要求,输出长度受到限制,识别文本不能太长。
更多优质内容请关注公号&知乎:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。


* 参考文献
[1] [An End-to-End Trainable Neural Network for Image-based SequenceRecognition and Its Application to Scene Text Recognition](https://arxiv.org/pdf/1507.05717v1.pdf)

