
这是微软发布在2022 ICML的论文,MoE可以降低训练成本,但是快速的MoE模型推理仍然是一个未解决的问题。所以论文提出了一个端到端的MoE训练和推理解决方案DeepSpeed-MoE:它包括新颖的MoE架构设计和模型压缩技术,可将MoE模型大小减少3.7倍;通过高度优化的推理系统,减少了7.3倍的延迟和成本;与同等质量的密集模型相比,推理速度提高4.5倍,成本降低9倍。
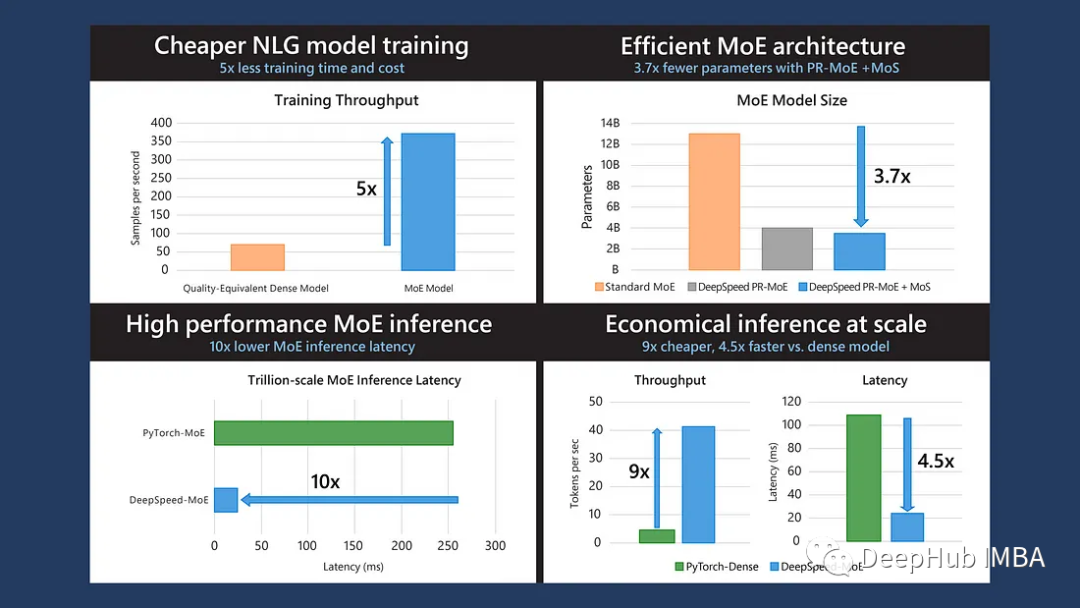
MoE
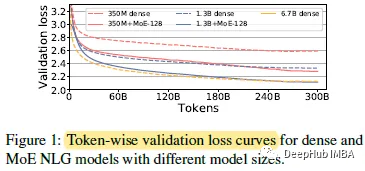
MoE架构使用了类似GPT-3的NLG模型。包括350M/1.3B/6.7B(24/24/32层,1024/2048/4096隐藏尺寸,16/16/32注意头)。例如:“350M+MoE-128”是指以350M密集模型为基础模型,128位专家组成的MoE模型。
训练使用了128个A100 gpu。令牌数量为300B。
下图显示了MoE模型的验证损失明显优于其密集对应部分(例如,1.3B+MoE-128 vs 1.3B dense)。
并且MoE模型与基数大4 - 5倍的dense模型的验证损失相当(例如,1.3B+MoE-128 vs . 6.7B dense)。
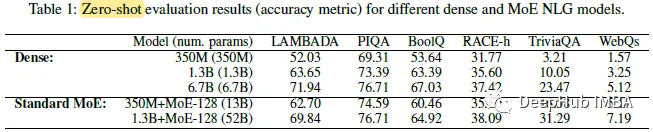
在零样本评估方面,模型质量也不相上下:1.3 b +MoE-128模型所需的训练计算量与13 b密集模型大致相同,但模型质量要好得多。1.3 b +MoE-128模型可以用13B密集模型的训练成本达到6.7B密集模型的模型质量,而训练计算量减少5倍。
Proposed Pyramid-Residual-MoE (PR-MoE)
1、所有的层都学习相同的表示吗?
这个问题在计算机视觉(CV)中已经有了很好的研究:浅层(接近输入)学习一般表示,深层(接近输出)学习更客观的特定表示。
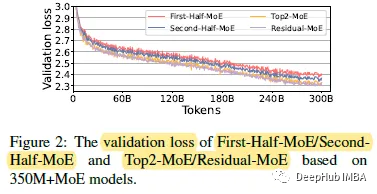
论文研究了两种不同的Half-MoE结构。
First-Half-MoE:MoE层在模型的前半层
Second-Half-MoE:MoE层在模型的后半层
结果可以看到,“Second-Half”的表现好。这也可以证明并非所有的MoE层都学习相同级别的表示。更深层的人从大量的专家中获益更多:或者说浅层的一般表示都是通用的。
2、是否有一种方法可以在获得泛化性能增益的同时保持训练/推理效率?
为了提高MoE模型的泛化性能,通常有两种方法:(1)增加专家数量,增加内存;(2)采用Top-2专家选择,这样计算量会多33%。
论文对比了两种moe
1、Top2-MoE使用Top2专家将参数提高一倍,2、Residual-MoE固定一个专家,然后并在不同的专家之间改变第二个专家,也就是说将来自MoE模块的专家视为误差校正项(或者叫一个主要专家,一个辅助专家)。
这两种模型的泛化性能相当。但是因为计算方式不同,Residual-MoE比Top2-MoE快10%以上。
3、PR-MoE
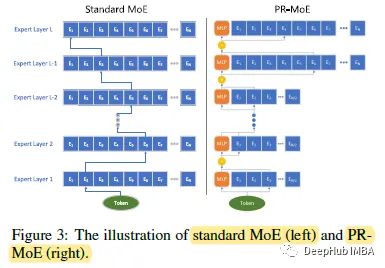
根据上面的研究结果,论文的新体系结构在最后几层使用了更多的专家。并且使用Residual-MoE架构,每个令牌分别传递一个固定的MLP模块和一个选定的专家。
PR-MoE使用更少的参数,但达到与标准moe模型相当的精度。
Proposed Mixture-of-Student (MoS)
对于损失函数,使用KD损失的一般公式来迫使学生模型模仿教师的输出:
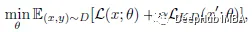
损失函数测量预测与给定硬标签之间的交叉熵损失的加权和,以及预测与教师软标签之间的KL散度损失。
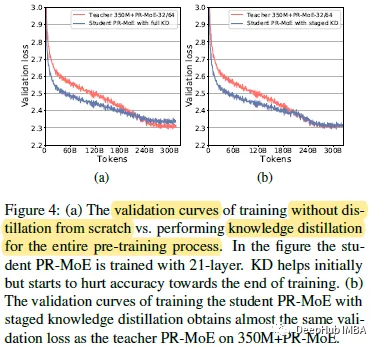
左图显示虽然KD损失最初提高了验证的准确性,但它在训练结束时开始损害准确性。由于PR-MoE与标准MoE相比已经降低了容量,这回导致学生模型进入欠拟合状态。
所以作者建议在训练过程中逐渐减弱KD的影响或尽早停止KD。
右图在400K步停止KD后,学生模型现在具有与教师相似的验证曲线。也就是说,在训练的后期可以不需要再让学生模型模仿教师模型,而是直接让学生模型自学。
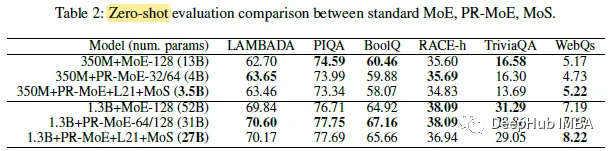
如上上图(表格)所示,通过分段KD的MoS平均准确率为42.87和47.96,尽管层数减少了12.5%,但仍保持了350M(43.08)和13b教师模型(48.37)的99.5%和99.1%的性能。
DeepSpeed-MoE
DeepSpeed主要只在MT-NLG 530B等Transformer上进行研究,之前没有在MoE上进行研究。而MoE推理性能取决于两个主要因素:总体模型大小和总体可实现的内存带宽。
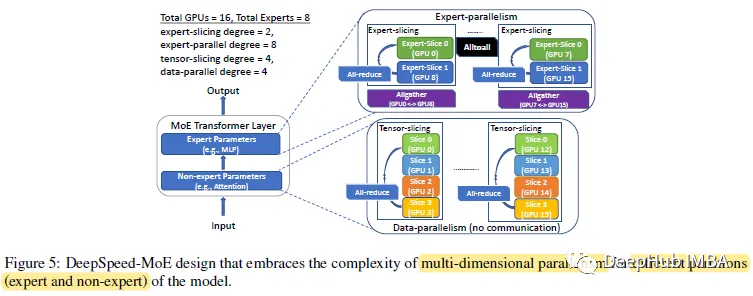
1、数据并行
张量切片(用于非专家参数),专家切片(用于专家参数)是将单个参数拆分到多个gpu上,可以充分利用gpu上的内存带宽。
为了将非专家计算扩展到相同数量的gpu,可以在没有通信开销的情况下使用数据并行。
2、将能分层的都进行分层
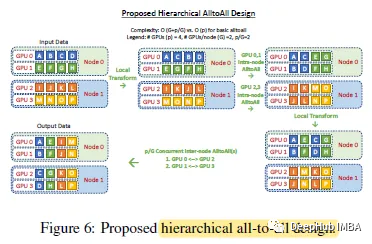
与all-reduce、broadcast等通信集合一起使用,可以将通信跳数从O(p)减少到O(G + p/G),其中G为节点中GPU的数量,p为GPU设备的总数,也就是说,GPU越多,减少的效果越明显
上图显示了该实现的设计概述。尽管通信量增加了2倍,但这种分层可以实现对小批量进行更好的扩展。
3、 并行通信和内核优化
这两部分比较深奥,并且更加专业,所以我这里只简单说明
由于张量并行度中的每个GPU都包含相同的数据,因此可以将所有对所有的通信限制在具有相同张量并行度等级的GPU之间。
将门控函数融合到单个内核中,并使用密集的令牌到专家映射表来表示令牌到专家的分配,大大降低了内核的启动开销。
这两部分如果是对这方面进行深入研究的建议阅读原文。
结果
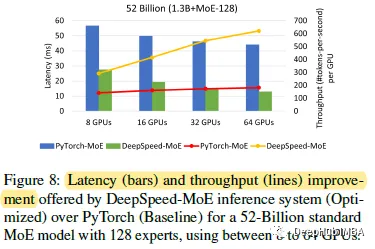
随着gpu数量的增加,DeepSpeed-MoE和PyTorch都减少了推理延迟,但PyTorch比DeepSpeed-MoE慢得多。
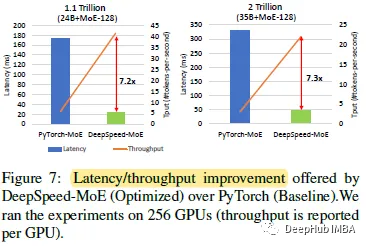
DeepSpeed-MoE实现了7.3倍的延迟减少,同时实现了高达7.3倍的高吞吐量。
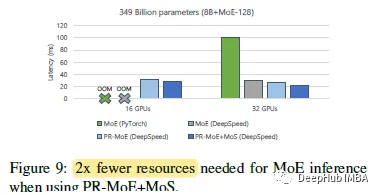
DeepSpeed-MoE可以减少执行推理所需的gpu的最小数量,并且可以进一步提高延迟和吞吐量。
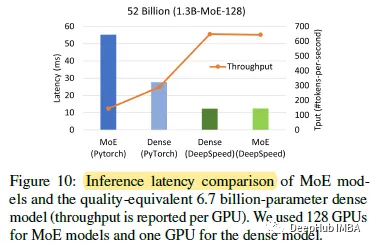
一个520亿参数的DeepSpeed-MoE模型(1.3 b - moe -128)相当于一个67亿参数的密集模型。
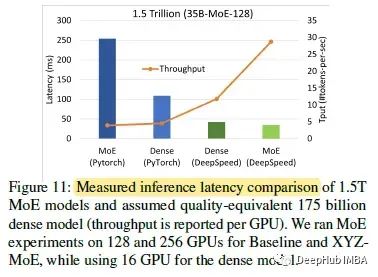
一个1.5万亿参数的MoE模型相当于一个1750亿参数的密集模型。
总结
最后我们来总结一下论文的要点:
DeepSpeed是一个用于训练大规模神经网络的系统,可以实现模型并行训练。Mixture of Experts(MoE)是一种模型架构,可以将一个大模型拆分成多个专家(expert)子模型,在训练和预测时对输入采样分发给不同的专家模型。
DeepSpeed+MoE的组合利用了两者的优势:
- DeepSpeed实现了高效的模型并行,可以训练数十亿参数的模型。将模型切分到不同的GPU上进行并行训练。
- MoE通过将模型拆分成更小的专家子模型,减少了每个子模型的复杂度,降低了训练时间。并可以动态调整不同样本到不同专家的分配,提高模型效果。
- 结合两者,可以训练超大规模的MoE模型,如Switch-Transformer, котор包含1.6万亿参数。DeepSpeed处理并行训练,MoE将模型拆分成多个专家。
主要创新:
- 深度优化MoE在并行训练中的通信,减少通信开销。并行效率很高。
- 提出了基于微调的专家排序机制,可以根据训练过程中专家的损失动态调整输入样本到专家的分配,提升效果。
- 支持各种稀疏训练技术,如3D 模型并行,减少内存需求并加速训练。
总体而言,DeepSpeed+MoE可以有效训练数万亿参数规模的模型,并展现出良好的scalability。这为训练更大及更复杂的神经网络模型提供了可能。
https://avoid.overfit.cn/post/745c466e10d3494faa54b21191fa762c

