
使用Stable Diffusion生成视频一直是人们的研究目标,但是我们遇到的最大问题是视频帧和帧之间的闪烁,但是最新的论文则着力解决这个问题。
本文总结了Chai等人的论文《StableVideo: Text-driven consistency -aware Diffusion Video Editing》,该论文提出了一种新的方法,使扩散模型能够编辑具有高时间一致性的视频。关键思想是:
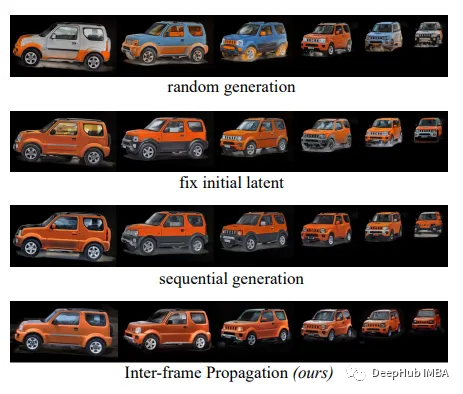
1、帧间传播,获得一致的目标外观
2、图集聚合,获得连贯的运动和几何
论文的实验表明,与最先进的方法相比,视频编辑效果更好。
论文提出的StableVideo是一个文本驱动的视频编辑框架,通过对自然视频的大量实验表明,与其他基于扩散的方法相比,StableVideo在保持几何形状和时间连续性的情况下产生优越的编辑结果。
图像编辑与扩散模型
扩散模型已经成为最先进的深度生成模型,用于根据文本提示或条件生成和编辑高保真图像。dall - e2和Stable Diffusion等模型可以合成符合所需文本描述的逼真图像。对于图像编辑也可以基于文本在语义上修改图像。
但是目前为止直接将扩散模型应用于视频编辑仍然是一个挑战。这里的一个最主要的关键的原因是缺乏时间一致性:SD模型是直接独立编辑每一帧,所以往往会导致闪烁效果和不连续的运动。
基于图集表示的视频编辑
为了在视频帧之间平滑地传播编辑,许多研究已经提出将视频分解为图集表示。视频帧被映射到统一的二维坐标空间,称为atlases,它随时间汇总像素。编辑该集合可以在映射过程中对整个视频进行连贯的更改。
以前的研究omnimates和神经分层图集(NLA),将前景和背景分离到不同的图集中。而Text2LIVE在NLA图集上增加了一个额外的图层,用于文本驱动的外观编辑。但是直接使用扩散模型的研究还没有成功

StableVideo框架
StableVideo框架通过结合两者的优点实现了高质量的基于扩散的视频编辑,并具有时间一致性。他的想法是与其直接编辑图集,不如先编辑关键帧,然后将它们聚合到编辑过的图集中,这样可以获得更好的结果。
也就是说具体来说,管道首先使用NLA将输入视频分解为前景和背景图集。然后根据文本提示分别应用扩散模型编辑背景和关键帧前景。为了确保连贯的外观,使用帧间传播编辑前景关键帧。编辑的关键帧被聚合成一个新的前景图集,它与编辑的背景一起重建最终的输出视频。

方法简介
1、基于神经分层图集的视频分解
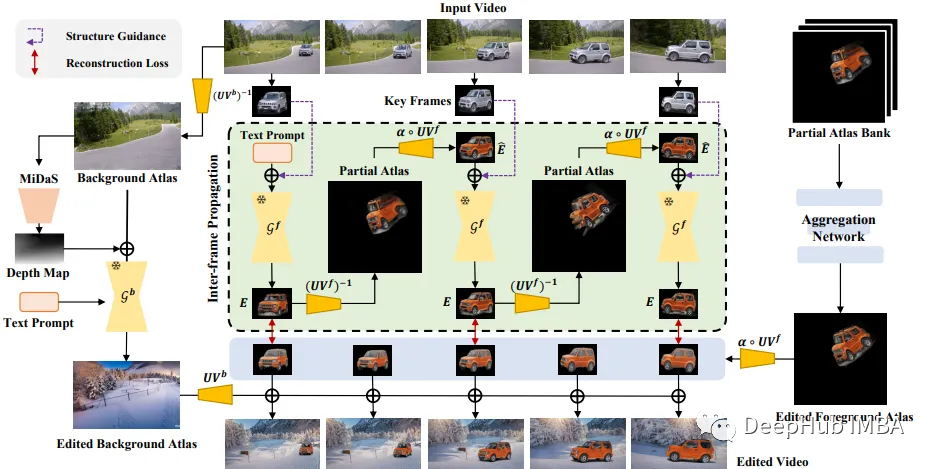
作为先决条件,使用预训练的NLA模型将输入视频分解为前景和背景图集。这为前景和背景提供了像素坐标和标准化图集坐标之间的映射:
UVb(.) = Mb(I)
UVf(.) = Mf(I)
这里I是输入帧,而UVb和UVf分别给出了背景和前景图集中相应的位置。
2、基于扩散的编辑
实际的编辑过程使用扩散模型Gb和Gf作为背景和前景。Gb直接编辑背景图集,Gf编辑前景关键帧:
Ab_edit = Gb(Ab, text_prompt) //编辑背景图集
Ei = Gf(Fi, text_prompt) //编辑关键帧
与严重扭曲的图集相比,在关键帧上工作提供了更可靠的编辑。
3、帧间传播前景编辑
为了保证关键帧编辑的时间一致性,提出了一种帧间传播机制。对于第一帧F0,扩散模型Gf正常编辑:
E0 = Gf(F0, text_prompt, structure_guidance)
对于随后的帧Fi,编辑的条件是文本提示和前一帧Ei-1的外观:
- Ei-1到ai - 1f的部分图谱映射
- 将Ai-1_f反向映射为当前帧E^i
- 在文本提示和结构指导下对E^i进行降噪,得到Ei
这种传播允许在关键帧之间依次生成具有一致外观的新前景对象。
4、Atlas聚合
编辑后的关键帧使用简单的3D CNN聚合成统一的前景图集。该网络被训练到最小化关键帧和它们从聚合图谱的反向映射之间的重建误差。这种紧密耦合确保编辑被合并到一个暂时一致的图集中。
最后,将编辑后的前景和背景图集进行映射和合成,得到最终编辑后的视频帧。使用原始的前景分割蒙版来混合图层。
优势
论文对包含复杂动作的自然视频进行了合成、风格转移、背景替换等多种视频编辑场景的演示。定性和定量实验均表明StableVideo优于现有的基于扩散的方法:
- 与Tune-A-Video相比,文本提示的可信度更高
- 与Tune-A-Video相比,闪烁和偏差明显减少
- 通过避免图集扭曲,比Text2LIVE更全面的编辑
- 比Text2LIVE/Tune-A-Video中的完整视频/编辑再培训更快的推理
消融试验也验证了所提出的传播和聚合模块的贡献——与独立编辑相比,关键帧传播大大提高了外观一致性。对于一个GPU上的70帧768x432视频来说,只需要30秒的运行时间。
安装和使用
git clone https://github.com/rese1f/StableVideo.git
conda create -n stablevideo python=3.11
pip install -r requirements.txt所有的模型和检测器都可以从ControlNet的页面下载。
然后工作目录是这样的
StableVideo
├── ...
├── ckpt
│ ├── cldm_v15.yaml
| ├── dpt_hybrid-midas-501f0c75.pt
│ ├── control_sd15_canny.pth
│ └── control_sd15_depth.pth
├── data
│ └── car-turn
│ ├── checkpoint # NLA models are stored here
│ ├── car-turn # contains video frames
│ ├── ...
│ ├── blackswan
│ ├── ...
└── ...运行
python app.py点击渲染按钮后,生成的mp4视频和关键帧将存储在/log目录中。
总结
StableVideo是一种具有扩散模型的高质量和时间一致的文本驱动视频编辑的新方法。其核心思想是编辑关键帧并在它们之间传播外观,并将编辑聚合到统一的图集空间中。大量的实验表明,该方法在编辑广泛的自然视频方面具有优越的连贯性。该技术提供了一种高效的解决方案,以适应强大的扩散模型,实现平滑的视频编辑。
看看我们的演示视频:
https://weixin.qq.com/sph/AkqDCb
最后就是论文地址:
https://avoid.overfit.cn/post/bc9b051949ea48078de19b3d5622e326

