
随着人工智能领域的不断进步,其子领域,包括自然语言处理,自然语言生成,计算机视觉等,由于其广泛的用例而迅速获得了大量的普及。光学字符识别(OCR)是计算机视觉中一个成熟且被广泛研究的领域。它有许多用途,如文档数字化、手写识别和场景文本识别。数学表达式的识别是OCR在学术研究中受到广泛关注的一个领域。
PDF是最广泛使用的格式之一,它通常保存在书籍中或发表在学术期刊上。pdf是互联网上第二大使用的数据格式,占信息的2.4%,经常用于文档传递。尽管它们被广泛使用,但从PDF文件中提取信息可能很困难,特别是在处理像科学研究文章这样高度专业化的材料时。因为包含了很多的数学公式,而现阶段的OCR可能会导致数学表达式的语义信息丢失。
Meta AI的一组研究人员推出了一种名为Nougat的解决方案,它代表“Neural Optical Understanding for Academic Documents”。为了对科学文本进行光学字符识别(OCR),Nougat是一种VIT模型。它的目标是将这些文件转换为标记语言,以便更容易访问和机器可读。
为了显示该方法的有效性,该团队还制作了一个新的学术论文数据集。这种方法为提高数字时代科学知识的可及性提供了可行的答案。它填补了人们易于阅读的书面材料与计算机可以处理和分析的文本之间的空白。Nougat基本上是一个基于Transformer的模型,用于将文档页面的图像(特别是来自pdf的图像)转换为格式化的标记文本。
该团队总结了他们的主要贡献如下-
发布预训练模型:创建可以将pdf转换为简单的标记语言的预训练模型。这个预训练的模型在GitHub上公开,任何人都可以访问它以及相关代码。
数据集创建管道:描述了一种构建数据集的方法,将PDF文档与其相关的源代码配对。这种数据集开发方法对于测试和改进Nougat模型至关重要,也可能对未来的文档分析研究和应用有用。
仅依赖于页面的图像:也就是说这个模型只要pdf的截图就可以了,这使得它成为一种灵活的工具,可以从各种来源提取内容,即使原始文档没有数字文本格式,也可以使用扫描的纸张和书籍进行处理。
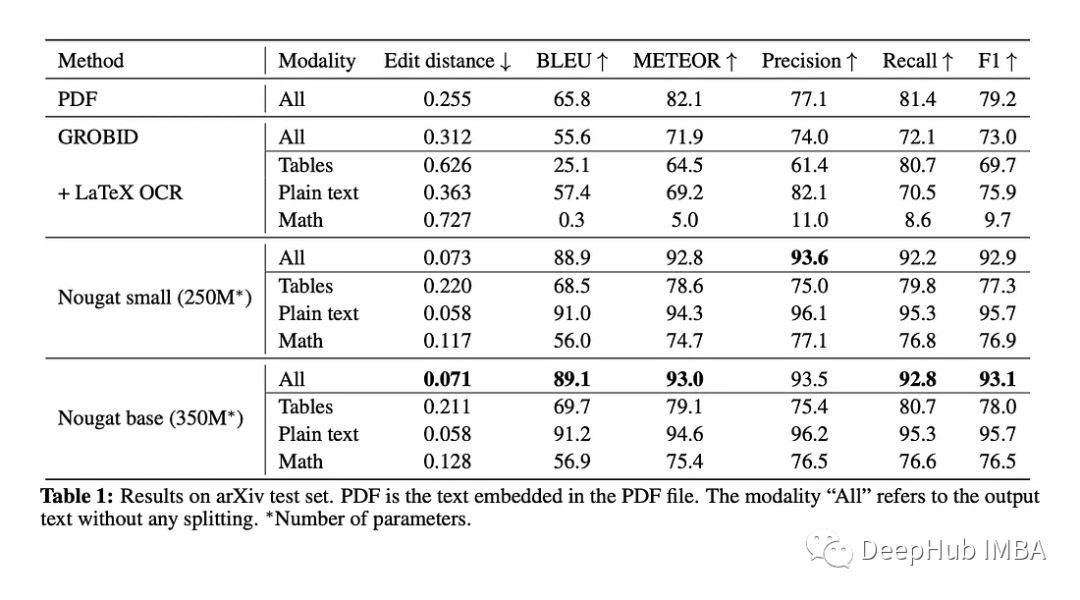
可以说Nougat通过利用VIT模型的功能,开创了OCR的新时代。它具有理解复杂科学文档并将其转换为结构化标记语言的能力,为无缝的信息可访问性铺平了道路,弥合了人类理解和机器分析之间的差距。这一创新为学术研究及其他领域带来了巨大的希望,体现了数字时代人工智能驱动的解决方案的变革力量。

以上截图来自官网,左图为图片文件,右图为Latex语法生成的公式
论文和官方网页在这里:
https://avoid.overfit.cn/post/061348444174421ebbe69423117c6e98
小吐槽:FB的项目管理一如既往的混乱
- Nougat 只配一个github的页面
- segment-anything 有一个单独的域名,更新动态的博客是ai.meta下面的
- llama只有一个ai.meta的二级目录,但是在ai.meta首页置顶,也算重视
- dinov2又跑去了metademolab的另外一个域名
可见前几天的内斗和算力竞争新闻是肯定了。

