
这是一篇很有意思的论文,他基于心音信号的对数谱图,提出了两种心率音分类模型,我们都知道:频谱图在语音识别上是广泛应用的,这篇论文将心音信号作为语音信号处理,并且得到了很好的效果。
对心音信号进行一致长度的分帧,提取其对数谱图特征,论文提出了长短期记忆(LSTM)和卷积神经网络(CNN)两种深度学习模型,根据提取的特征对心跳声进行分类。
心音数据集
影像学诊断包括心脏核磁共振成像(MRI)、CT扫描、心肌灌注成像。这些技术的缺点也很明显对现代机械、专业人员的要求高,诊断时间长。
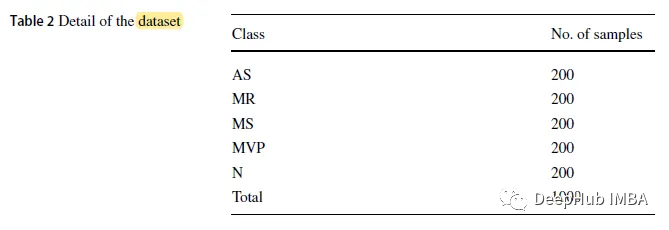
论文使用的是公共数据集,由1000个。wav格式的信号样本组成,采样频率为8 kHz。数据集分为5类,包括1个正常类(N)和4个异常类:主动脉瓣狭窄(AS)、二尖瓣反流(MR)、二尖瓣狭窄(MS)和二尖瓣脱垂(MVP)。
主动脉瓣狭窄(AS)是指主动脉瓣太小、狭窄或僵硬。主动脉瓣狭窄的典型杂音是高音调的“菱形”杂音。
二尖瓣返流(MR)是指心脏的二尖瓣没有正常关闭,导致血液回流到心脏而不是被泵出。听诊胎儿心脏时,S1可能很低(有时很响)。直到S2,杂音的音量增加。由于S3后二尖瓣急流,可听到短而隆隆声的舒张中期杂音。
二尖瓣狭窄(MS)是指二尖瓣受损不能完全打开。心音听诊显示二尖瓣狭窄早期S1加重,严重二尖瓣狭窄时S1软。随着肺动脉高压的发展,S2音将被强调。纯多发性硬化症患者几乎没有左室S3。
二尖瓣脱垂(MVP)是指在心脏收缩期二尖瓣小叶脱垂至左心房。MVP通常是良性的,但并发症包括二尖瓣反流、心内膜炎和脊索断裂。体征包括收缩期中期的咔嗒声和收缩期晚期的杂音(如果存在反流)。
预处理与特征提取
声音信号有不同的长度。所以需要固定每个记录文件的采样率。长度被裁剪后使声音信号包含至少一个完整的心脏周期。成年人每分钟心跳65-75次,心跳周期约为0.8秒,所以信号样本被裁剪为2.0-s, 1.5-s和1.0-s段。
基于离散傅里叶变换(DFT),将心音信号的原始波形转换为对数谱图。声音信号的DFT y(k)为Eq.(1),对数谱图s定义为Eq.(2)。
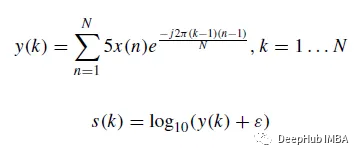
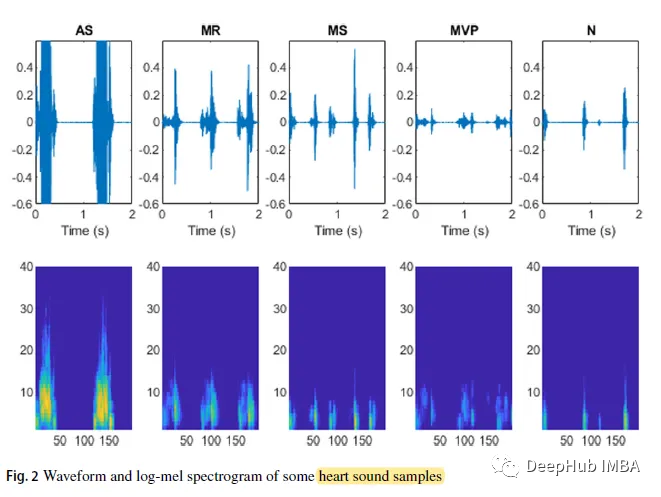
式中,N为向量x的长度,ε = 10^(- 6)是一个小偏移量。部分心音样本的波形和对数谱图如下:
深度学习模型
1、LSTM
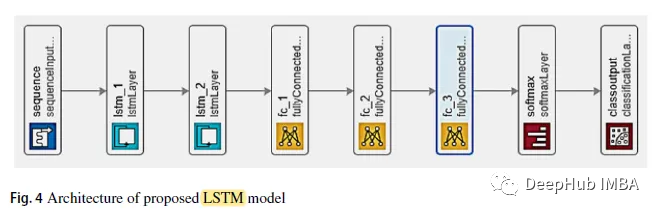
LSTM模型设计为2层直接连接,然后是3层完全连接。第三个完全连接的层输入softmax分类器。
2、CNN模型
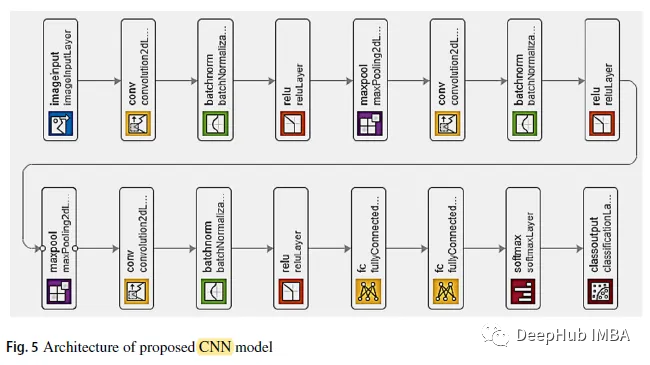
如上图所示,前两个卷积层之后是重叠的最大池化层。第三个卷积层直接连接到第一个全连接层。第二个完全连接的层提供给具有五个类标签的softmax分类器。在每个卷积层之后使用BN和ReLU。
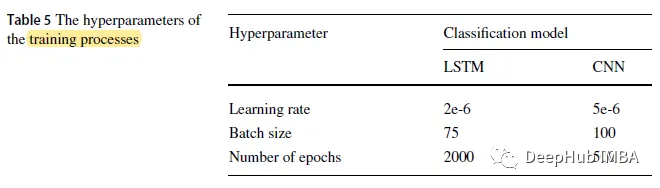
3、训练细节
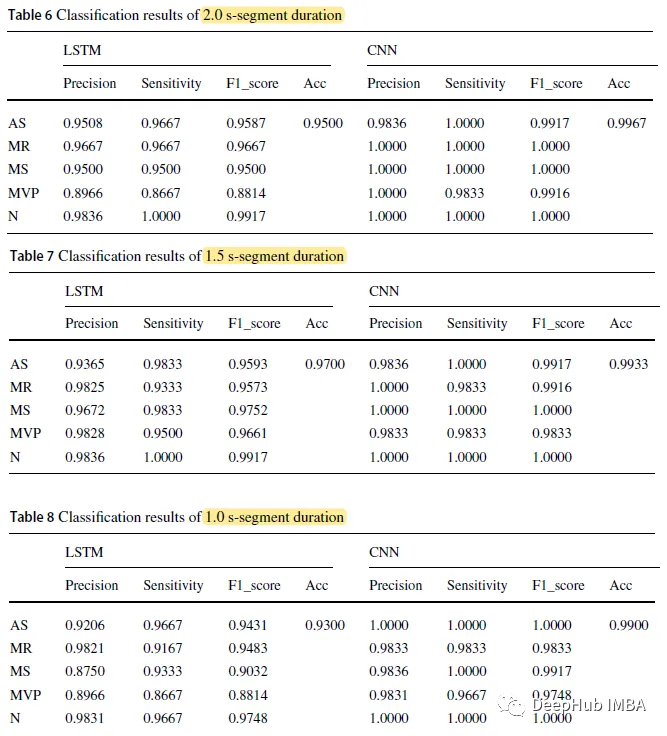
结果
训练集包含整个数据集的70%,测试集包含其余部分。
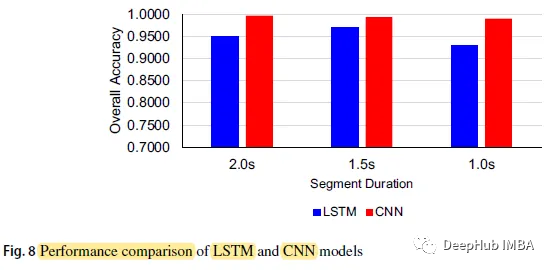
当CNN模型片段持续时间为2.0 s时,准确率最高为0.9967;分割时间为1.0 s的LSTM准确率最低为0.9300。
CNN模型的整体准确率分别为0.9967、0.9933和0.9900,片段持续时间分别为2.0 s、1.5 s和1.0 s,而LSTM模型的这三个数字分别为0.9500、0.9700和0.9300。
CNN模型比LSTM模型在各时段的预测精度更高。
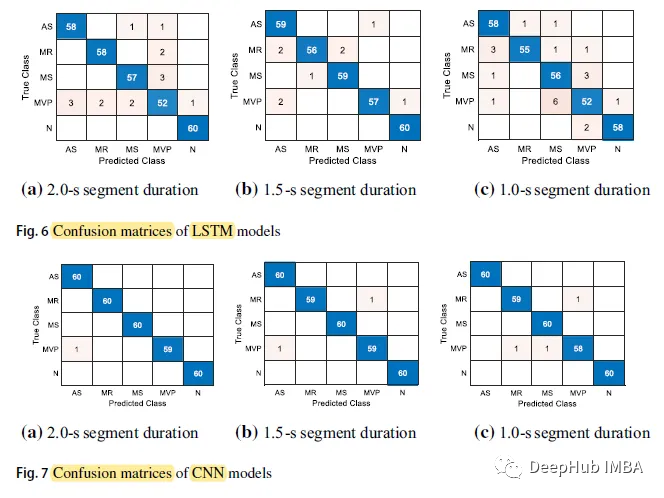
混淆矩阵如下:
N类(Normal)的预测正确率最高,在5个案例中达到60个,而MVP类在所有案例中预测正确率最低。
LSTM模型输入时间长度为2.0 s,最长预测时间为9.8631 ms。分类时间为1.0 s的CNN模型预测时间最短,为4.2686 ms。
与其他SOTA比较,一些研究的准确率非常高,但这些研究只进行了两类(正常和异常),而本研究分为五类。
与使用相同数据集的其他研究相比(0.9700),论文研究有了显著提高,最高准确率为0.9967。

论文地址:
Heart Sound Classification Using Deep Learning Techniques Based on Log-mel Spectrogram
https://avoid.overfit.cn/post/c8f5ca920d5c4d7c819b2678eaaf946a

