
向量召回:深入评估离线体系,探索优质召回方法
1.简介
近年来,基于向量进行召回的做法在搜索和推荐领域都得到了比较广泛的应用,并且在学术界发表的论文中,基于向量的 dense retrieve 的方法也在不少数据集上都战胜了 sparse retrieve,吸引了越来越多的关注。在内网的不少文章中也都介绍了各种不同的模型和算法,但是目前我们还没有看到比较系统的介绍向量召回评估体系的文章,在这里我们抛砖引玉,对搜索在将向量召回应用到搜索方向过程中积累的召回评估方面的内容,进行了梳理和归纳,希望能对大家有所帮助,也希望能引出更多关于召回评估的好的方法和思路。
搜索方向对召回效果的评估,主要可以分为人工评估和自动化指标评估,我们在本文中主要讨论在模型和索引迭代过程中的自动化指标评估,人工评估目前主要用于对最终上线前的效果进行评估。
1.1 评估体系演进
从 2017 年开始,搜索就在不同的业务上开始尝试向量召回,在整个发展过程中,模型经历了从 CNN、RNN 到最近的基于预训练的演进。在评估指标的体系上,随着经验的积累,也在不断进行演化,基于时间线,我们将评估体系的演化分为三个版本,下面对三个版本逐次展开介绍。
1.2 第一版
第一版的评估体系的建设中,我们主要考虑解决模型离线迭代过程中的指标评估问题和构建完全量索引后的指标评估问题。在离线的指标评估中我们将召回任务看作是排序问题,即在召回时如果能将好的结果排在差的结果前面,我们就可以召回比较好的结果,因此,我们的离线指标评估中主要在离线评估集合上计算 NDCG/PAIR 等排序指标进行对比;对全量索引上召回的数据是未标注过的,如果对每次召回结果进行人工标注评估,成本过高,因此,如何进行自动化的评估就成了我们在第一版的评估体系中重点思考的问题。
我们第一版向量召回主要应用在搜索的一路垂直搜索中,在搜索时主要为通用搜索提供一些额外好结果的补充,因此与通用搜索不同,我们不需要每次查询都返回结果,但是我们需要保证返回的结果的相关性要尽可能的好,以防止引入恶劣 Case。所以,在我们的服务中有一个截断模型,会对结果进行截断,能够通过截断模型的结果我们就认为结果是好的。基于此,我们考虑可以固定不同版本模型建立的索引的召回条数,在线召回时统计通过截断模型后保留下来的结果的数量,以此作为模型在全量索引上的召回评估指标。当一版模型 A 召回的结果经过截断模型后能比另一版模型 B 保留下更多的结果,我们就可以认为 A 要比 B 具有更好的召回效果。为了分析会不会因为截断模型误杀导致指标错误,我们将截断模型截断的数据进行数据分析和人工 review,最终发现虽然存在部分误杀情况,但是只要两个版本之间指标差距大于一定阈值,这个指标就会比较准确。基于此,我们在第一版中确定了如下的评估体系:
- 评估数据
3000 个 query,每个 query 对应 40 个 doc,人工按照相关性进行标注,标注的 label 为 0-4 档。
评估维度
- 离线模型迭代指标
- 全量刷库后的召回指标
评估指标
- 离线模型迭代指标,主要利用评估数据集,由模型对标注的 query-doc 对进行打分,并利用分值进行排序,计算 NDCG 和 PAIR 指标
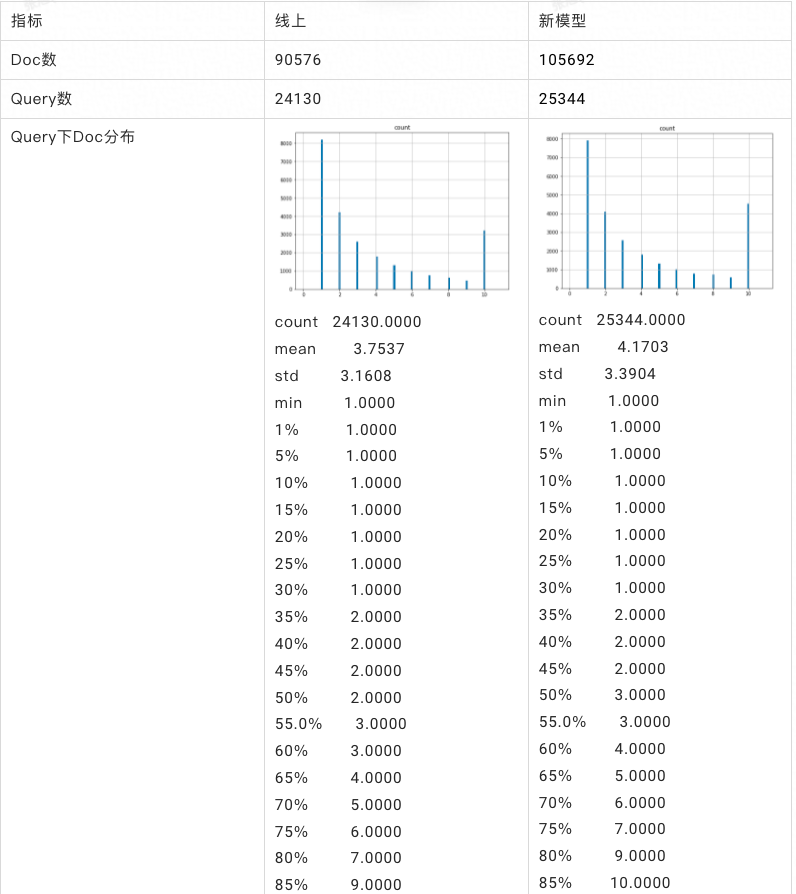
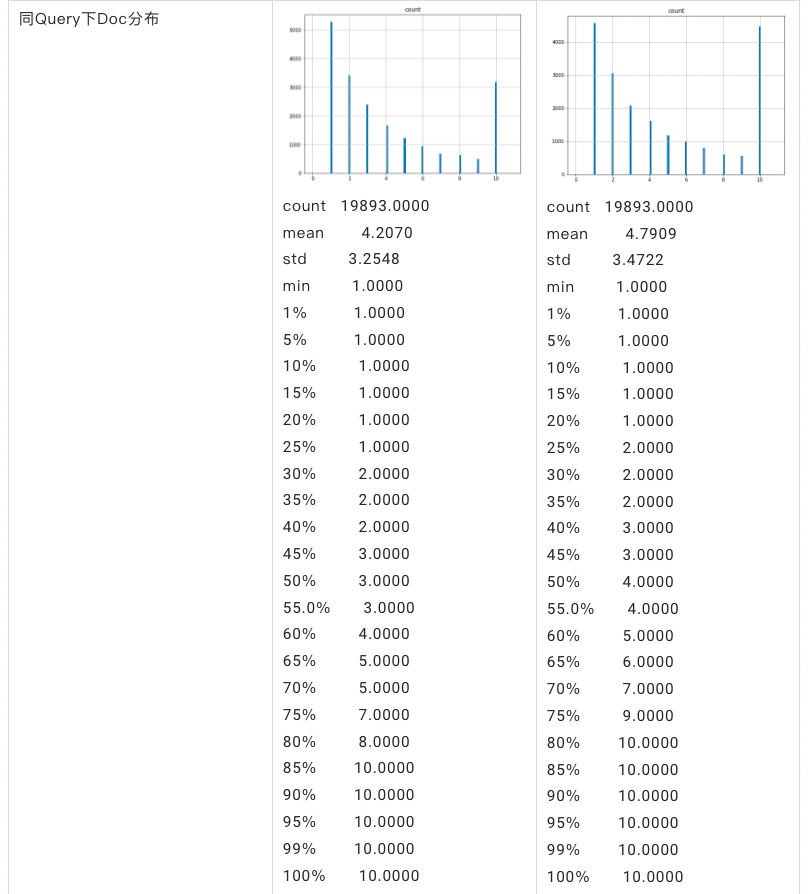
- 全量刷库建索引后的召回指标,通过用户日志每次抽取 30000 个 query,对比两版向量索引分别召回 top 10 的结果,过截断模型,统计截断后保留下来的 doc 数和分析保留下来的数据的特征分布,评估召回效果,如图一所示,我们会统计最终截断后还有数据的 query 的数量,最终保留下来的 doc 的数量,以及每个 query 下平均剩余的 doc 数量、同 query 下剩余的 doc 平均数量,从统计看新模型无论在保留下的 doc 数、query 数,还是在每个 query 下平均剩余 doc 数和同 query 下剩余的 doc 数都胜出线上的 base 模型。
1.3 第二版
从第二版的评估体系开始,我们的应用场景切换到了搜索的通用搜索场景,因此,在评估体系上也会有一些变化。
第一版的问题
我们在第一版的指标体系使用过程中,发现了一些问题:- NDCG/PAIR 指标与我们的场景不够适配,NDCG 和 PAIR 指标都比较强调数据的偏序,尤其是比较注重头部数据的偏序,但是在召回方向上,我们更注重的是好结果的召回率,至于结果的位置则相对次要
- 只在标注的数据集上进行每个 query 指标的计算,与线上真实检索场景差距较大。计算指标时只在当前 query 下标注的数据进行比较,而线上检索时则会存在大量的干扰项,因此会导致离线指标和在大数据集上指标计算存在偏差
- 通用搜索必须保证每个 query 下尽可能的出搜索结果,即使结果的相关性或者质量略差些,这就使得在第一版中通过截断模型评估的方式在第二版中不再继续适用
- 第二版的改进
针对提到的第一版的问题,在第二版中我们做了如下改进:1.利用召回指标替换 NDCG 和 PAIR 指标,我们重点关注标注 label 大于等于 1 的数据的召回率指标,降低位置的权重2.从仅计算 query 标注的数据切换为每个 query 与标注集合中的所有 doc 计算分值,进行排序,相当于模拟在线检索时的穷举检索3.增加了在大数据量上的召回指标,将标注数据集加入到抽取的大数据量文档中,计算在大数据集上的召回率,并利用搜索最先进的满意度打分模型进行打分,根据召回率以及模型打分指标评估模型在大数据集上的效果
- 评估数据
新标注一版 3000 个 query 左右,每个 query 下平均 doc 数为 40 的数据集,标注标注为综合满意度,综合满意度会考虑相关性、质量等多方面因素,标注 Label 为 0-4 档
评估维度
- 离线模型迭代指标
- 单片刷库召回指标
- 评估指标
- R1/R2 召回指标,在模型离线迭代时,模型对每个 Query 与集合中所有的 Doc 进行打分,利用打分进行排序,选取 Top20,统计其中好结果在标注结果中的召回率,R1 是指 Label 大于等于 1 的 Doc 的召回率,R2 是指 Label 大于等于 2 的 Doc 召回率,计算公式如图二所示

- 满意度模型打分平均分,我们从索引数据随机抽取了 5000 万的数据,并将标注数据混入到这 5000 万的数据中,构建大数据索引,并分别利用标注集的 query 和从用户日志随机抽取 10000 个 query 分别请求索引,对标注集合的 query 数据集我们计算召回数据中 Top20 的 R1/R2 指标,对于随机抽取的 10000 个 query 则计算满意度打分平均值,我们通过两个方面的分值比较模型效果
1.4 第三版
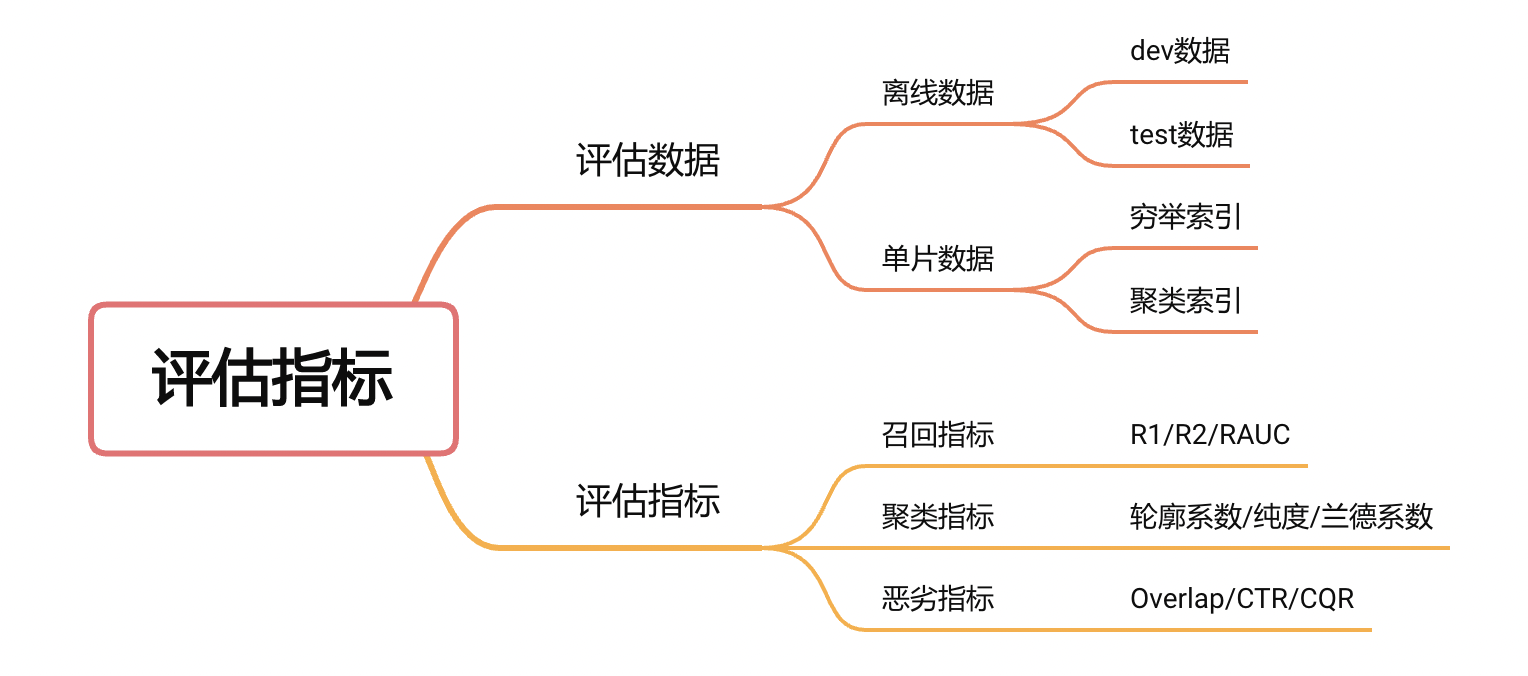
第三版的指标评估体系是我们目前在用并且仍在开发中版本,如图 3 所示,相比起前两版,第三版的评估体系更加完善,指标的计算也修正了之前版本的很多问题。
第二版的问题
- 在第二版中我们在计算 RX 指标时,取了固定的 TopK 结果,这就导致指标容易出现突变点。比如,我们以只有一个 query 举例,该 query 只有 3 个大于 1 的标注数据,如果取 k=20 时,召回了 1 条大于等于 1 的结果,则 R1=1/3,而如果 21 位也是一条大于等于 1 的结果,则只要 k 变为 21,R1 的指标就会变为 2/3。这就导致指标会随着 k 的变化而剧烈变动,很容易导致指标的不稳定
- 标注集合中的 query 并不是完全正交的,因此,在计算离线或者单片指标时,虽然有些结果在当前 query 下未标注,但是仍然可能是相关的结果,因此,容易导致计算的指标不准确
- 当前离线评估指标只评估在穷举上的召回指标,只能反映出模型在给定的测试集上的上限。但是,没有办法反映模型的聚类损失、召回结果的恶劣问题占比等信息。因此,导致对模型的评估不够全面,进而可能导致选取出的模型存在问题。
- 评估数据
1.在版本 2 的基础上,扩充了部分标注数据,并且将离线评测数据切分成 Dev 集和 Test 集。
评估维度
- 离线模型迭代指标A.召回指标: R1/R2/RAUC 等召回指标,衡量模型的召回率情况B.聚类指标: 衡量聚类的损失情况。比如轮廓系数、纯度、兰德系数等C.恶劣指标: 衡量模型召回数据中恶劣 case 的占比等信息,透视模型召回的下限
- 单片刷库召回指标
- 评估指标
- 针对问题 1,我们提出了 RAUC 指标,通过计算从 1-N 各个位置的 R1 指标,最终取平均的方式作为召回指标,从而缓解因取单个 k 值导致指标波动大的问题,指标计算的公式如图四所示:

- 针对问题 2,我们目前正在通过构建长 List 的方式进行解决。基本方案为: 一个 query 除当前已标注的数据外,我们会通过各种负采样的方式采样数据加入到 query 下作为候选结果,比如: BM25 负采样、随机负采样、聚类负采样等。以此来模拟线上检索时面对的各种不用相关度的结果,并替代掉版本 2 中的穷举计算。3.
- 针对问题 3,我们对召回的结果计算 query 与召回结果之间的字重合度和 CQR(Title 分词对 Query 分词的覆盖情况),以此来衡量召回结果的下限,防止出现既召回部分非常好的结果,但同时也召回大量非常差的结果,如果是这种情况就很容易导致误混入的问题;加入了轮廓系数的计算,衡量聚类的效果。4.同时为了评估在单片上真实的聚类效果,我们在单片评估时加入了在穷举索引上的召回指标计算,并以此计算在聚类索引召回指标和在穷举索引召回指标的打折情况,分析模型的聚类损失情况,这个信息除了可以反馈模型的指标,还可以反过来指标我们去优化模型的聚类效果,以适配线上索引的聚类要求。
2. 总结
我们在本文中,系统的梳理了搜索在向量召回方向上评估指标和评估体系的探索。将我们的思考和各个版本存在的问题以及为解决问题进行的演化展现出来,希望能对大家有所启发,也希望能激发大家更多好的想法。目前第三个版本的指标体系我们还在持续的优化中,我们也希望随着优化和迭代,我们的第三版评估体系帮我们更全面、更高效的评估模型效果。
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。


