
大规模语言LLaVA:多模态GPT-4智能助手,融合语言与视觉,满足用户复杂需求
一个面向多模式GPT-4级别能力构建的助手。它结合了自然语言处理和计算机视觉,为用户提供了强大的多模式交互和理解。LLaVA旨在更深入地理解和处理语言和视觉信息,从而实现更复杂的任务和对话。这个项目代表了下一代智能助手的发展方向,它能够更好地理解和应对用户需求。
- 效果展示
demo链接:https://llava.hliu.cc/
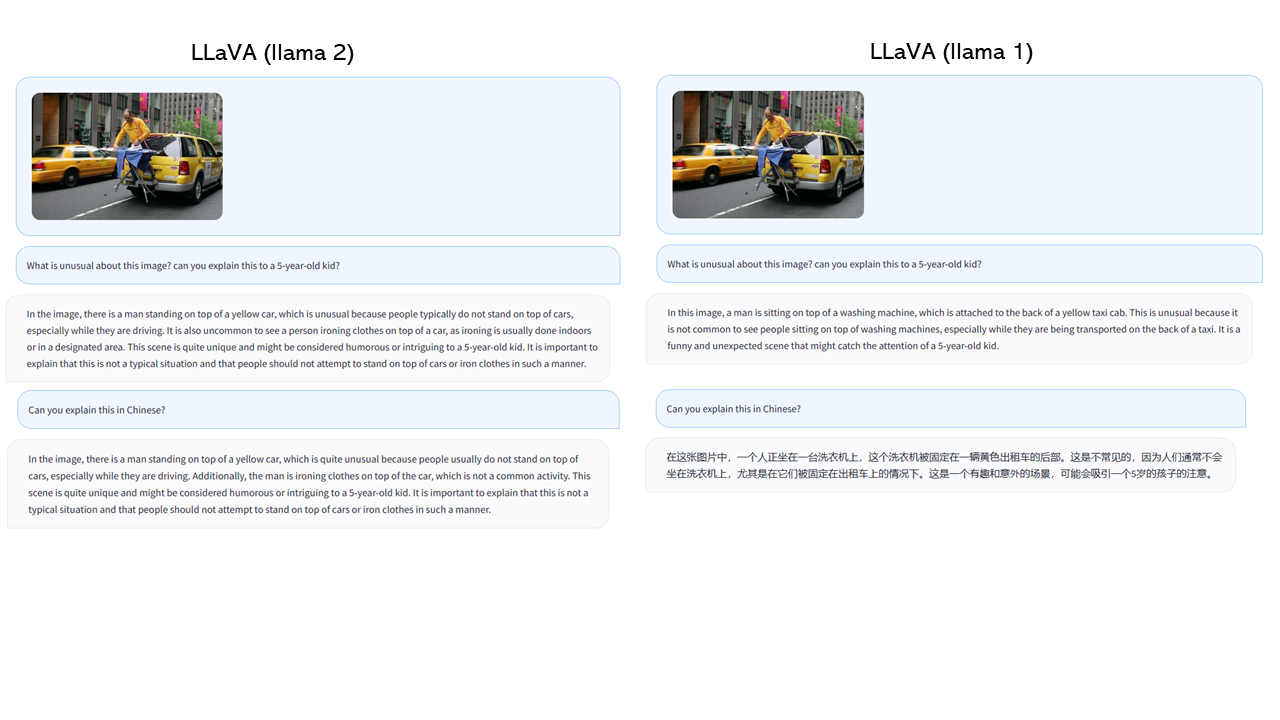
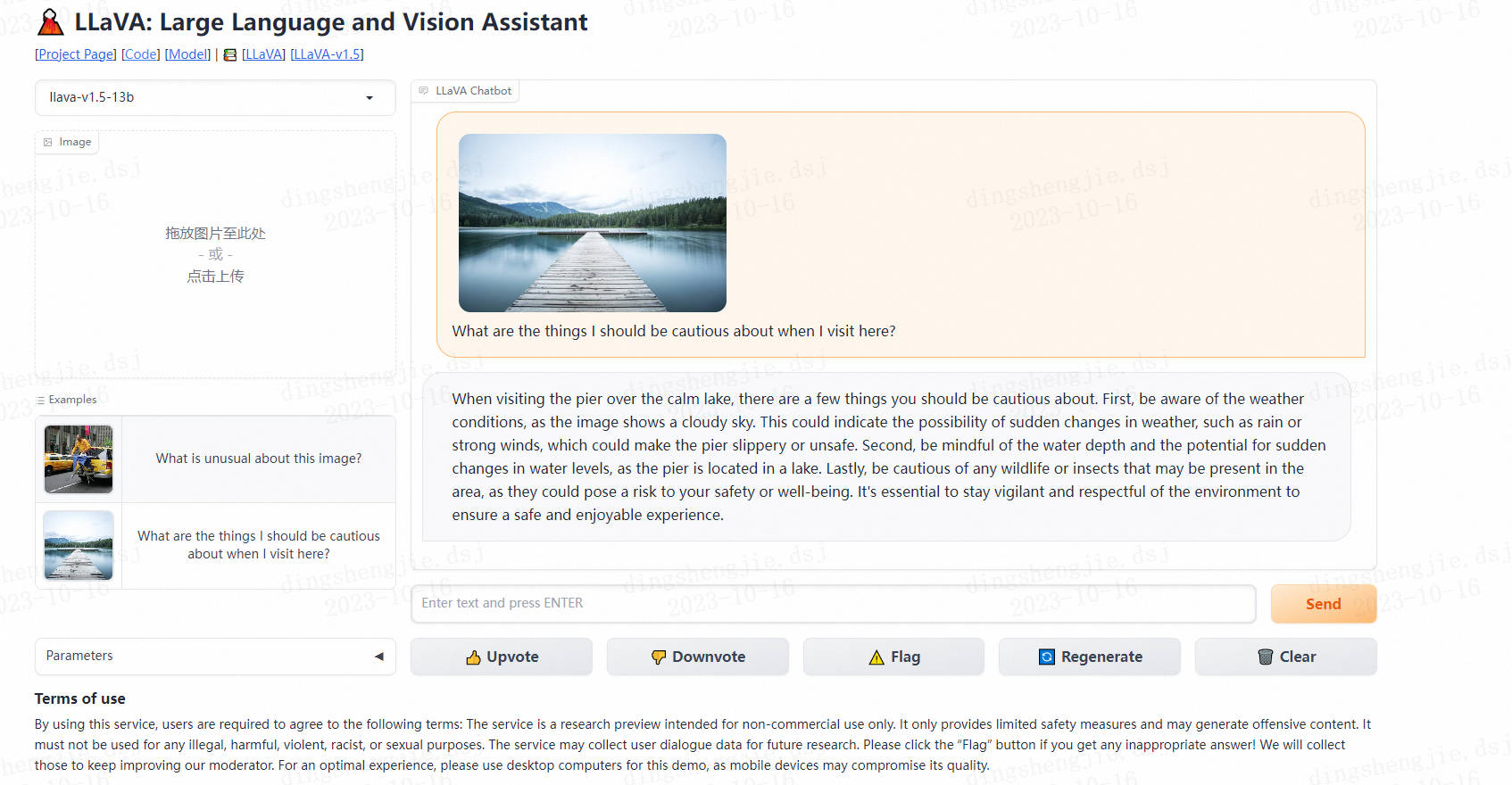
当我来这里旅游时,我应该注意哪些事情?
在平静的湖面上游览码头时,有几件事你应该小心。首先,要注意天气状况,因为图像显示的是多云的天空。这可能表明天气突然变化的可能性,如下雨或强风,这可能使码头湿滑或不安全。其次,要注意水深和水位突然变化的可能性,因为码头位于湖中。最后,要小心任何可能出现在该地区的野生动物或昆虫,因为它们可能会对你的安全或健康构成威胁。为了确保安全愉快的体验,保持警惕和尊重环境是必不可少的。
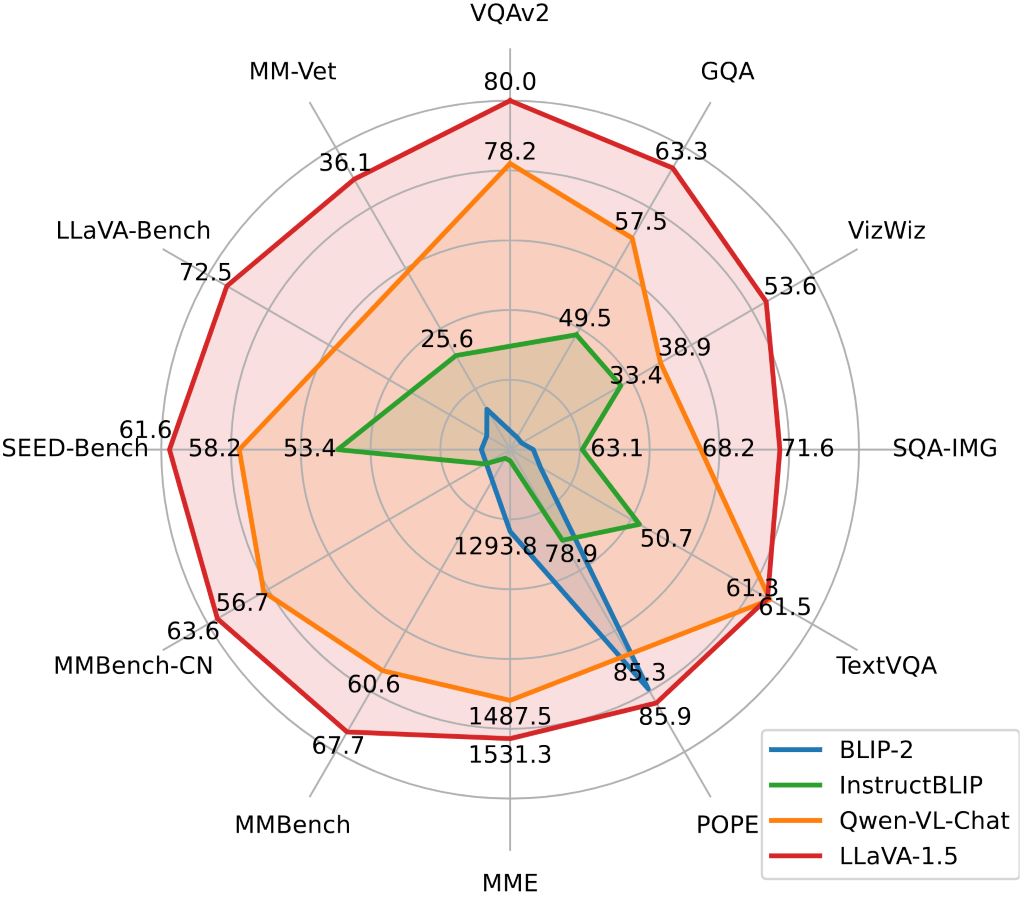
- 主流大模型之间对比
1.安装
Clone this repository and navigate to LLaVA folder
git clone https://github.com/haotian-liu/LLaVA.git cd LLaVAInstall Package
conda create -n llava python=3.10 -y conda activate llava pip install --upgrade pip # enable PEP 660 support pip install -e .Install additional packages for training cases
pip install ninja pip install flash-attn --no-build-isolation
1.1 升级到最新的代码库
git pull
pip uninstall transformers
pip install -e .2.LLaVA 权重
Please check out our Model Zoo for all public LLaVA checkpoints, and the instructions of how to use the weights.
2.1 Demo
To run our demo, you need to prepare LLaVA checkpoints locally. Please follow the instructions here to download the checkpoints.
2.2 基于Gradio Web UI
要在本地启动Gradio demo,请依次运行以下命令。如果你计划启动多个模型工作者来比较不同的检查点,你只需要启动控制器和web服务器一次。
Launch a controller
python -m llava.serve.controller --host 0.0.0.0 --port 10000Launch a gradio web server.
python -m llava.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload您刚刚启动了grado web界面。现在,您可以打开带有打印在屏幕上的URL的web界面。您可能会注意到在模型列表中没有模型。别担心,我们还没有推出劳模。当你启动一个模型工作者时,它将被自动更新。
- Launch a model worker
This is the actual worker that performs the inference on the GPU. Each worker is responsible for a single model specified in --model-path.
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13bWait until the process finishes loading the model and you see "Uvicorn running on ...". Now, refresh your Gradio web UI, and you will see the model you just launched in the model list.
You can launch as many workers as you want, and compare between different model checkpoints in the same Gradio interface. Please keep the --controller the same, and modify the --port and --worker to a different port number for each worker.
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port <different from 40000, say 40001> --worker http://localhost:<change accordingly, i.e. 40001> --model-path <ckpt2>If you are using an Apple device with an M1 or M2 chip, you can specify the mps device by using the --device flag: --device mps.
- Launch a model worker (Multiple GPUs, when GPU VRAM <= 24GB)
如果GPU的VRAM小于24GB(例如,RTX 3090, RTX 4090等),您可以尝试在多个GPU上运行它。如果您有多个GPU,我们最新的代码库将自动尝试使用多个GPU。你可以使用' CUDA_VISIBLE_DEVICES '来指定使用哪个gpu。下面是使用前两个gpu运行的示例。
CUDA_VISIBLE_DEVICES=0,1 python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b- Launch a model worker (4-bit, 8-bit inference, quantized)
您可以使用量化位(4位,8位)启动模型工作器,这允许您在减少GPU内存占用的情况下运行推理,可能允许您在只有12GB VRAM的GPU上运行。请注意,使用量子化位的推理可能不如全精度模型准确。只需将'——load-4bit '或'——load-8bit '附加到您正在执行的model worker命令。下面是一个使用4位量化运行的示例。
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b --load-4bit- Launch a model worker (LoRA weights, unmerged)
您可以使用LoRA权重启动模型工作器,而不将它们与基本检查点合并,以节省磁盘空间。会有额外的加载时间,而推理速度与合并的检查点相同。未合并的LoRA检查点在模型名称中没有“LoRA -merge”,并且通常比合并的检查点小得多(小于1GB) (7B为13G, 13B为25G)。
要加载未合并的LoRA权重,您只需要传递一个额外的参数'——model-base ',这是用于训练LoRA权重的基本LLM。您可以在模型动物园中查看每个LoRA权重的基本LLM。
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1-0719-336px-lora-vicuna-13b-v1.3 --model-base lmsys/vicuna-13b-v1.33.CLI 推理
使用LLaVA讨论图像,而不需要使用Gradio接口。支持多gpu、4位和8位量化推理。使用4位量化,对于我们的LLaVA-1.5-7B,它在单个GPU上使用不到8GB的VRAM。
python -m llava.serve.cli \
--model-path liuhaotian/llava-v1.5-7b \
--image-file "https://llava-vl.github.io/static/images/view.jpg" \
--load-4bit<img src="images/demo_cli.gif" width="70%">
4.模型训练
以下是LLaVA v1.5的最新培训配置。对于遗留模型,请参考此版本的README。稍后我们将把它们添加到一个单独的文档中
LLaVA训练包括两个阶段:(1)特征对齐阶段:使用LAION-CC-SBU数据集的558K子集将“冻结预训练”视觉编码器连接到“冻结LLM”;(2)视觉指令调整阶段:使用150K gpt生成的多模态指令跟随数据,加上515K左右的学术任务VQA数据,来教模型遵循多模态指令。
LLaVA is trained on 8 A100 GPUs with 80GB memory. To train on fewer GPUs, you can reduce the per_device_train_batch_size and increase the gradient_accumulation_steps accordingly. Always keep the global batch size the same: per_device_train_batch_size x gradient_accumulation_steps x num_gpus.
4.1 超参数
We use a similar set of hyperparameters as Vicuna in finetuning. Both hyperparameters used in pretraining and finetuning are provided below.
- Pretraining
| Hyperparameter | Global Batch Size | Learning rate | Epochs | Max length | Weight decay |
|---|---|---|---|---|---|
| LLaVA-v1.5-13B | 256 | 1e-3 | 1 | 2048 | 0 |
- Finetuning
| Hyperparameter | Global Batch Size | Learning rate | Epochs | Max length | Weight decay |
|---|---|---|---|---|---|
| LLaVA-v1.5-13B | 128 | 2e-5 | 1 | 2048 | 0 |
4.2 下载 Vicuna checkpoints (automatically)
我们的基本模型Vicuna v1.5,这是一个指令调整聊天机器人,将自动下载,当你运行我们提供的训练脚本。不需要任何操作。
4.3 预训练 (特征对齐)
请下载我们在论文中使用的带有BLIP标题的LAION-CC-SBU数据集的558K子集在这里。
在8x A100 (80G)上,由于分辨率增加到336px, LLaVA-v1.5-13B的预训练大约需要5.5小时。LLaVA-v1.5-7B大约需要3.5小时。
Training script with DeepSpeed ZeRO-2: pretrain.sh.
--mm_projector_type mlp2x_gelu: the two-layer MLP vision-language connector.--vision_tower openai/clip-vit-large-patch14-336: CLIP ViT-L/14 336px.
4.4 可视化训练调试
- Prepare data
Please download the annotation of the final mixture our instruction tuning data llava_v1_5_mix665k.json, and download the images from constituting datasets:
- COCO: train2017
- GQA: images
- OCR-VQA: download script
- TextVQA: train_val_images
- VisualGenome: part1, part2
After downloading all of them, organize the data as follows in ./playground/data,
├── coco
│ └── train2017
├── gqa
│ └── images
├── ocr_vqa
│ └── images
├── textvqa
│ └── train_images
└── vg
├── VG_100K
└── VG_100K_2- Start training!
You may download our pretrained projectors in Model Zoo. It is not recommended to use legacy projectors, as they may be trained with a different version of the codebase, and if any option is off, the model will not function/train as we expected.
Visual instruction tuning takes around 20 hours for LLaVA-v1.5-13B on 8x A100 (80G), due to the increased resolution to 336px. It takes around 10 hours for LLaVA-v1.5-7B on 8x A100 (40G).
Training script with DeepSpeed ZeRO-3: finetune.sh.
New options to note:
--mm_projector_type mlp2x_gelu: the two-layer MLP vision-language connector.--vision_tower openai/clip-vit-large-patch14-336: CLIP ViT-L/14 336px.--image_aspect_ratio pad: this pads the non-square images to square, instead of cropping them; it slightly reduces hallucination.--group_by_modality_length True: this should only be used when your instruction tuning dataset contains both language (e.g. ShareGPT) and multimodal (e.g. LLaVA-Instruct). It makes the training sampler only sample a single modality (either image or language) during training, which we observe to speed up training by ~25%, and does not affect the final outcome.
5.模型评估
In LLaVA-1.5, we evaluate models on a diverse set of 12 benchmarks. To ensure the reproducibility, we evaluate the models with greedy decoding. We do not evaluate using beam search to make the inference process consistent with the chat demo of real-time outputs.
See Evaluation.md.
5.1 基于GPT协助的评估
我们的gpt辅助的多模态建模评估管道提供了对视觉语言模型能力的全面理解。详情请参阅我们的文章。
- Generate LLaVA responses
python model_vqa.py \
--model-path ./checkpoints/LLaVA-13B-v0 \
--question-file \
playground/data/coco2014_val_qa_eval/qa90_questions.jsonl \
--image-folder \
/path/to/coco2014_val \
--answers-file \
/path/to/answer-file-our.jsonl- Evaluate the generated responses. In our case,
answer-file-ref.jsonlis the response generated by text-only GPT-4 (0314), with the context captions/boxes provided.
OPENAI_API_KEY="sk-***********************************" python llava/eval/eval_gpt_review_visual.py \
--question playground/data/coco2014_val_qa_eval/qa90_questions.jsonl \
--context llava/eval/table/caps_boxes_coco2014_val_80.jsonl \
--answer-list \
/path/to/answer-file-ref.jsonl \
/path/to/answer-file-our.jsonl \
--rule llava/eval/table/rule.json \
--output /path/to/review.json- Summarize the evaluation results
python summarize_gpt_review.py
6.模型合集
要使用llava -1.5检查点,您的llava软件包版本必须高于1.1.0。说明如何升级。
如果您有兴趣在模型动物园中加入任何其他细节,请打开一个问题:)
下面的模型权重是合并的权重。你不需要应用。LLaVA检查点的使用应该符合基本LLM的模型许可:Llama 2。
LLaVA-v1.5
| Version | Size | Schedule | Checkpoint | VQAv2 | GQA | VizWiz | SQA | T-VQA | POPE | MME | MM-Bench | MM-Bench-CN | SEED | LLaVA-Bench-Wild | MM-Vet |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaVA-1.5 | 7B | full_ft-1e | liuhaotian/llava-v1.5-7b | 78.5 | 62.0 | 50.0 | 66.8 | 58.2 | 85.9 | 1510.7 | 64.3 | 58.3 | 58.6 | 65.4 | 31.1 |
| LLaVA-1.5 | 13B | full_ft-1e | liuhaotian/llava-v1.5-13b | 80.0 | 63.3 | 53.6 | 71.6 | 61.3 | 85.9 | 1531.3 | 67.7 | 63.6 | 61.6 | 72.5 | 36.1 |
| LLaVA-1.5 | 7B | lora-1e | coming soon | ||||||||||||
| LLaVA-1.5 | 13B | lora-1e | coming soon |

LLaVA-v1
Note: We recommend using the most capable LLaVA-v1.5 series above for the best performance.
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Finetuning Data | Finetuning schedule | LLaVA-Bench-Conv | LLaVA-Bench-Detail | LLaVA-Bench-Complex | LLaVA-Bench-Overall | Download |
|---|---|---|---|---|---|---|---|---|---|---|
| Vicuna-13B-v1.3 | CLIP-L-336px | LCS-558K | 1e | LLaVA-Instruct-80K | proj-1e, lora-1e | 64.3 | 55.9 | 81.7 | 70.1 | LoRA LoRA-Merged |
| LLaMA-2-13B-Chat | CLIP-L | LCS-558K | 1e | LLaVA-Instruct-80K | full_ft-1e | 56.7 | 58.6 | 80.0 | 67.9 | ckpt |
| LLaMA-2-7B-Chat | CLIP-L | LCS-558K | 1e | LLaVA-Instruct-80K | lora-1e | 51.2 | 58.9 | 71.6 | 62.8 | LoRA |
Projector weights
These are projector weights we have pretrained. You can use these projector weights for visual instruction tuning. They are just pretrained on image-text pairs, and are NOT instruction tuned, which means they do NOT follow instructions as good as our official models, and can output repetitive, lengthy, and garbled outputs. If you want to have nice conversations with LLaVA, use the checkpoints above (LLaVA v1.5).
NOTE: These projector weights are only compatible with the llava>=1.0.0, please check out the latest code base if your local code version is below v1.0.0.
NOTE: When you use our pretrained projector for visual instruction tuning, it is very important to use the same base LLM and vision encoder as the one we used for pretraining the projector. Otherwise, the performance will be very bad.
When using these projector weights to instruction tune your LMM, please make sure that these options are correctly set as follows,
--mm_use_im_start_end False
--mm_use_im_patch_token False| Base LLM | Vision Encoder | Projection | Pretrain Data | Pretraining schedule | Download |
|---|---|---|---|---|---|
| Vicuna-13B-v1.5 | CLIP-L-336px | MLP-2x | LCS-558K | 1e | projector |
| Vicuna-7B-v1.5 | CLIP-L-336px | MLP-2x | LCS-558K | 1e | projector |
| LLaMA-2-13B-Chat | CLIP-L-336px | Linear | LCS-558K | 1e | projector |
| LLaMA-2-7B-Chat | CLIP-L-336px | Linear | LCS-558K | 1e | projector |
| LLaMA-2-13B-Chat | CLIP-L | Linear | LCS-558K | 1e | projector |
| LLaMA-2-7B-Chat | CLIP-L | Linear | LCS-558K | 1e | projector |
| Vicuna-13B-v1.3 | CLIP-L-336px | Linear | LCS-558K | 1e | projector |
| Vicuna-7B-v1.3 | CLIP-L-336px | Linear | LCS-558K | 1e | projector |
| Vicuna-13B-v1.3 | CLIP-L | Linear | LCS-558K | 1e | projector |
| Vicuna-7B-v1.3 | CLIP-L | Linear | LCS-558K | 1e | projector |
Science QA Checkpoints
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Finetuning Data | Finetuning schedule | Download |
|---|---|---|---|---|---|---|
| Vicuna-13B-v1.3 | CLIP-L | LCS-558K | 1e | ScienceQA | full_ft-12e | ckpt |
Legacy Models (merged weights)
The model weights below are merged weights. You do not need to apply delta. The usage of LLaVA checkpoints should comply with the base LLM's model license.
| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Finetuning Data | Finetuning schedule | Download |
|---|---|---|---|---|---|---|
| MPT-7B-Chat | CLIP-L | LCS-558K | 1e | LLaVA-Instruct-80K | full_ft-1e | preview |
Legacy Models (delta weights)
The model weights below are delta weights. The usage of LLaVA checkpoints should comply with the base LLM's model license: LLaMA.
You can add our delta to the original LLaMA weights to obtain the LLaVA weights.
Instructions:
- Get the original LLaMA weights in the huggingface format by following the instructions here.
- Use the following scripts to get LLaVA weights by applying our delta. It will automatically download delta weights from our Hugging Face account. In the script below, we use the delta weights of
liuhaotian/LLaVA-7b-delta-v0as an example. It can be adapted for other delta weights by changing the--deltaargument (and base/target accordingly).
python3 -m llava.model.apply_delta \
--base /path/to/llama-7b \
--target /output/path/to/LLaVA-7B-v0 \
--delta liuhaotian/LLaVA-7b-delta-v0| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Finetuning Data | Finetuning schedule | Download |
|---|---|---|---|---|---|---|
| Vicuna-13B-v1.1 | CLIP-L | CC-595K | 1e | LLaVA-Instruct-158K | full_ft-3e | delta-weights |
| Vicuna-7B-v1.1 | CLIP-L | LCS-558K | 1e | LLaVA-Instruct-80K | full_ft-1e | delta-weights |
| Vicuna-13B-v0 | CLIP-L | CC-595K | 1e | LLaVA-Instruct-158K | full_ft-3e | delta-weights |
| Vicuna-13B-v0 | CLIP-L | CC-595K | 1e | ScienceQA | full_ft-12e | delta-weights |
| Vicuna-7B-v0 | CLIP-L | CC-595K | 1e | LLaVA-Instruct-158K | full_ft-3e | delta-weights |
Legacy Projector weights
The following projector weights are deprecated, and the support for them may be removed in the future. They do not support zero-shot inference. Please use the projector weights in the table above if possible.
NOTE: When you use our pretrained projector for visual instruction tuning, it is very important to use the same base LLM and vision encoder as the one we used for pretraining the projector. Otherwise, the performance will be very bad.
When using these projector weights to instruction tune your LMM, please make sure that these options are correctly set as follows,
--mm_use_im_start_end True
--mm_use_im_patch_token False| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Download |
|---|---|---|---|---|
| Vicuna-7B-v1.1 | CLIP-L | LCS-558K | 1e | projector |
| Vicuna-13B-v0 | CLIP-L | CC-595K | 1e | projector |
| Vicuna-7B-v0 | CLIP-L | CC-595K | 1e | projector |
When using these projector weights to instruction tune your LMM, please make sure that these options are correctly set as follows,
--mm_use_im_start_end False
--mm_use_im_patch_token False| Base LLM | Vision Encoder | Pretrain Data | Pretraining schedule | Download |
|---|---|---|---|---|
| Vicuna-13B-v0 | CLIP-L | CC-595K | 1e | projector |
7.数据集介绍
| Data file name | Size |
|---|---|
| llava_instruct_150k.json | 229 MB |
| llava_instruct_80k.json | 229 MB |
| conversation_58k.json | 126 MB |
| detail_23k.json | 20.5 MB |
| complex_reasoning_77k.json | 79.6 MB |
7.1 Pretraining Dataset
The pretraining dataset used in this release is a subset of CC-3M dataset, filtered with a more balanced concept coverage distribution. Please see here for a detailed description of the dataset structure and how to download the images.
If you already have CC-3M dataset on your disk, the image names follow this format: GCC_train_000000000.jpg. You may edit the image field correspondingly if necessary.
| Data | Chat File | Meta Data | Size |
|---|---|---|---|
| CC-3M Concept-balanced 595K | chat.json | metadata.json | 211 MB |
| LAION/CC/SBU BLIP-Caption Concept-balanced 558K | blip_laion_cc_sbu_558k.json | metadata.json | 181 MB |
Important notice: Upon the request from the community, as ~15% images of the original CC-3M dataset are no longer accessible, we upload images.zip for better reproducing our work in research community. It must not be used for any other purposes. The use of these images must comply with the CC-3M license. This may be taken down at any time when requested by the original CC-3M dataset owner or owners of the referenced images.
7.2 GPT-4 Prompts
我们为GPT-4查询提供提示和少量样本,以更好地促进该领域的研究。请查看' prompts '文件夹中的三种问题:对话、细节描述和复杂推理。
它们以' system_message.txt '的格式组织,用于系统消息,' abc_caps.txt '对用于少数几个示例用户输入,' abc_conf .txt '用于少数几个示例参考输出。
请注意,它们的格式可能不同。例如,' conversation '在' json '中,详细描述是只回答的。我们在初步实验中选择的格式比我们尝试的一组有限的替代方案稍微好一些:“json”,更自然的格式,只有答案。如果有兴趣,您可以尝试其他变体或对此进行更仔细的研究。欢迎投稿!
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

