

高通的DSP
芝能智芯出品
现代手机要处理很多电话和视频的信号,还要尽量省电。数字信号处理器(DSP)是一种专门的芯片,可以帮助手机做这些事情,让CPU不用太累。
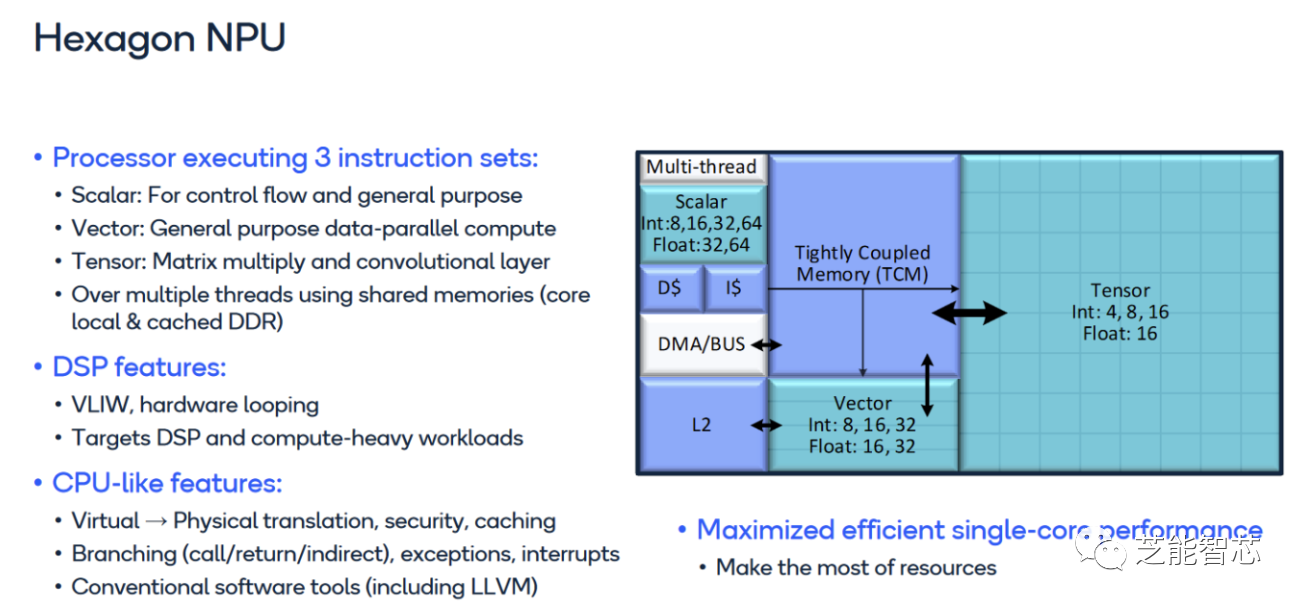
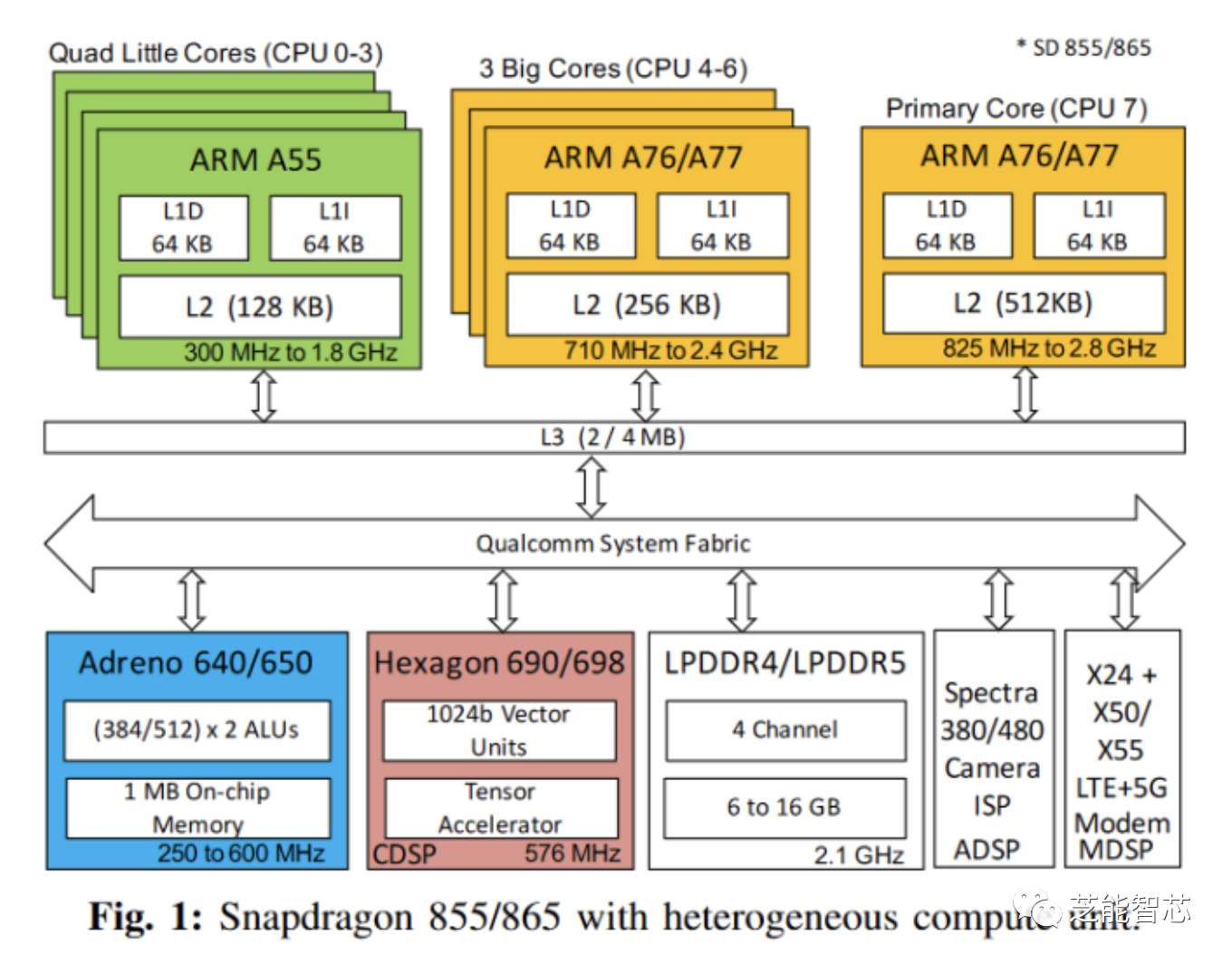
Hexagon处理器是Qualcomm公司设计的一种NPU,用在它们的骁龙产品里。不仅可以处理信号,还可以处理机器学习的任务,因为它有一种叫做矩阵乘法的功能。 
Hexagon是一种可以一次执行四条指令的芯片,而且有一些特别的功能来处理信号。它可以同时运行多个线程,也就是说它可以同时做几件事情。Hexagon有一个小的协作器来帮助它执行向量和张量的运算,这些运算可以让它每秒钟做很多次计算。
Hexagon也支持虚拟内存和缓存,这些是一些可以让它更快地读写数据的技术。但是它有一个不同的执行模型,就是它先提交指令,然后再执行。这样做可以让它有一个深度的执行管道,但是也有一个缺点,就是如果出现了一些错误,可能不能及时发现。
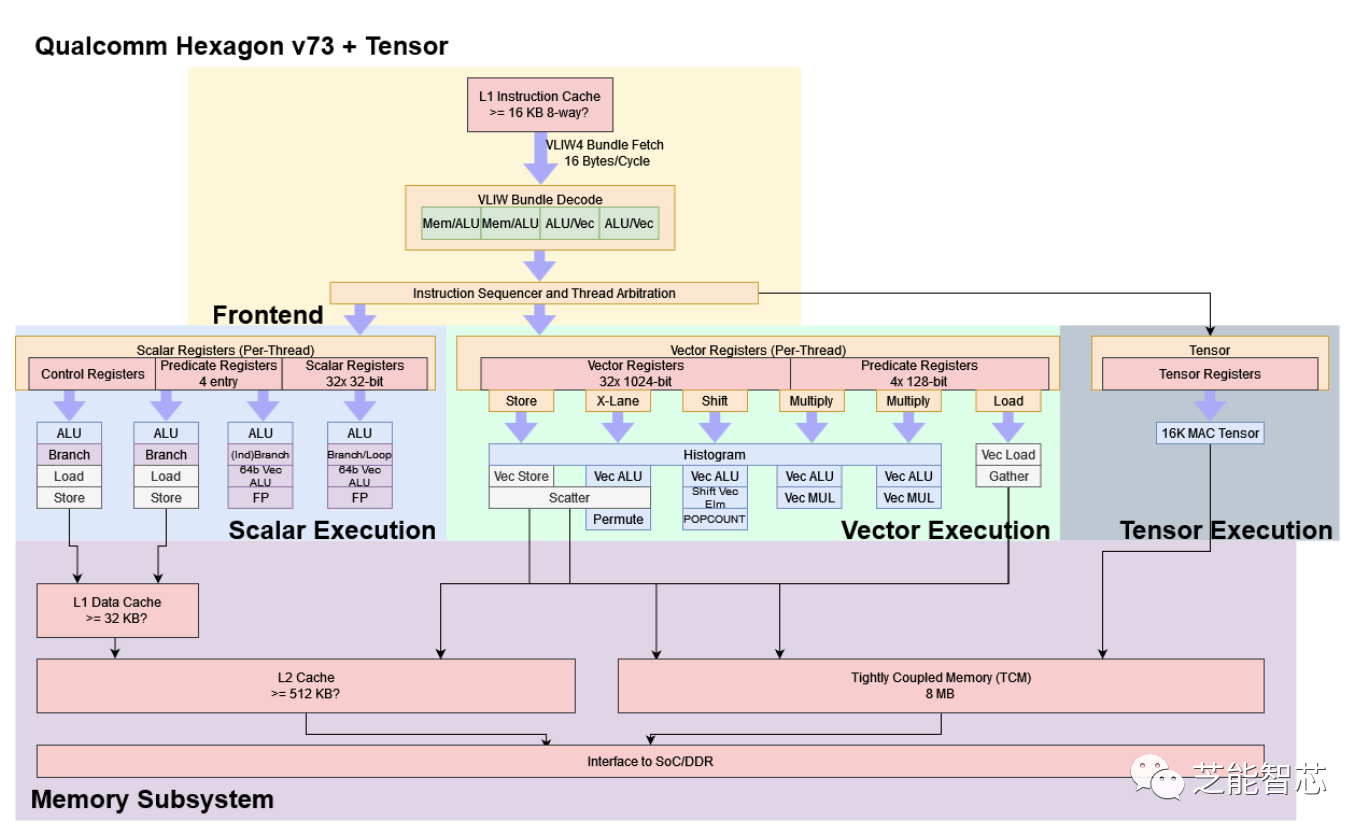
在骁龙8 Gen 2里,Hexagon可以同时运行6个线程,比一般的CPU强大,但是也没有GPU那么强大。每个Hexagon线程默认只有一个标量上下文,也就是说只能做一些简单的计算。如果要用到向量或张量协作器,就要先申请。 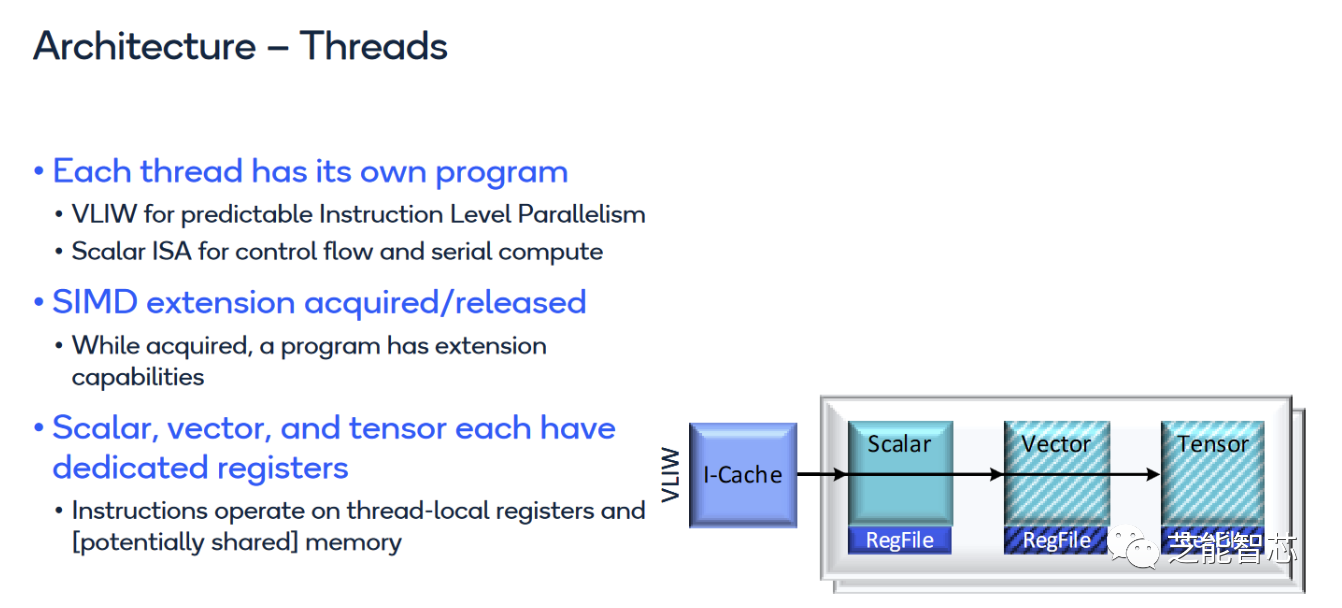
在前端,分支预测是一种可以让它提前知道接下来要执行哪些指令的技术。这样可以节省时间和能源。Qualcomm为Hexagon实现了分支预测,并且提供了一些性能监控事件来显示分支预测的效果,大部分分支只需要两个周期就能处理好,少数分支需要三个周期。
当分支预测给出了目标地址后,Hexagon就从指令缓存中取出一个128位的VLIW捆绑。每个VLIW捆绑包含最多四条指令,这让我想知道为什么Qualcomm选择了“Hexagon”这个名字。
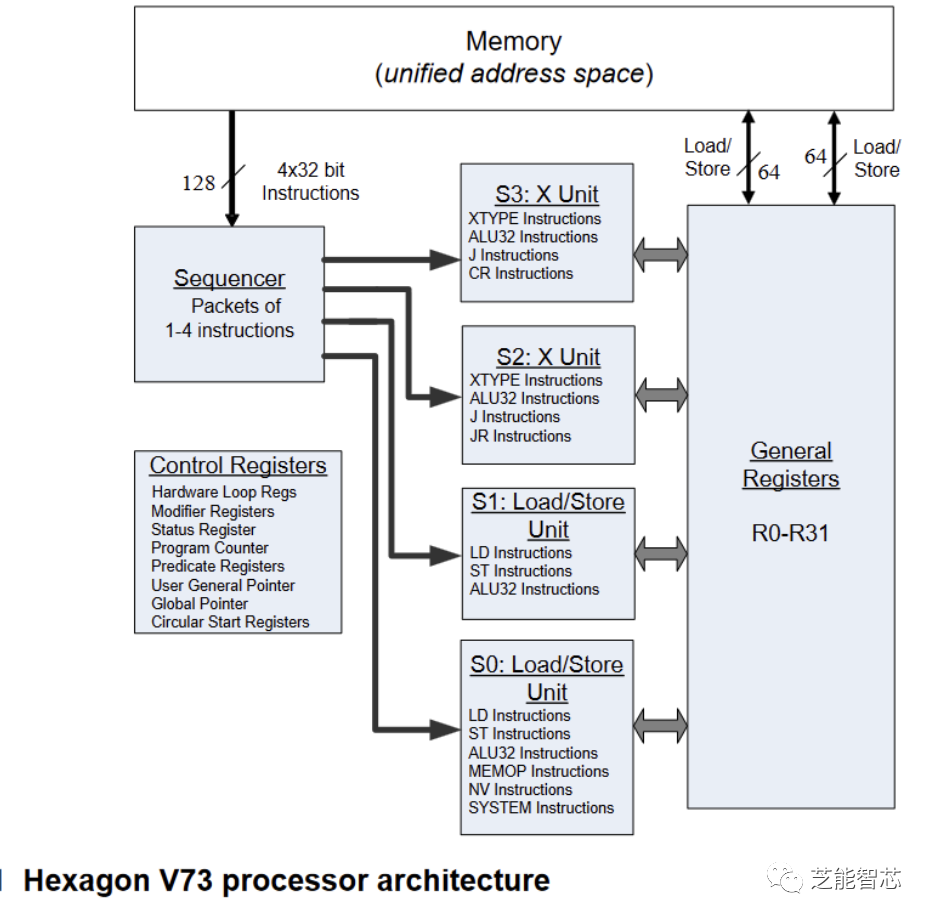
“Qualcomm Quadrilateral”听起来更合理,也更好听。VLIW捆绑可以让它用简单的硬件来执行多条指令。解码器便宜,因为每个VLIW位置只能放一种类型的指令。硬件不用解决冲突,因为打包到VLIW捆绑中的指令不能互相影响,并且不能写入同一个寄存器。执行管道选择逻辑也更简单,因为每个VLIW位置对应一个执行管道。
指令取出和解码后,就被发送到相应的单位或协作器进行执行。

Hexagon有一个32位标量单元,每个线程上下文有32个寄存器。这个标量单元很强大,可以独立处理一些轻量级的DSP任务。因为VLIW打包,它可以每个周期完成最多四条指令,并且每条指令可以做很多事情。有一些专门的指令用于图像处理和视频解码等任务。“标量”单元甚至可以执行向量操作。比如说,它可以把几个小的数据放到一个寄存器里,然后一起处理。标量单元的两个管道也可以处理浮点运算。这有点像Intel的MMX,只是它用的是通用寄存器。
有一些专用的控制寄存器可以让它自动循环,这样就不用每次都检查循环条件。循环缓冲区也是一种可以让它更快地访问数据的技术。一个特殊的“全局指针”寄存器可以帮助它访问全局或静态数据。这些技术可以减少寄存器的压力。

Hexagon矢量扩展(HVX)为更重的DSP任务提供了更多支持。HVX提供32个1024位矢量寄存器和一组执行管道,可以做一些向量运算。Hexagon的矢量上下文比标量多,所以线程要用到HVX就要先申请。
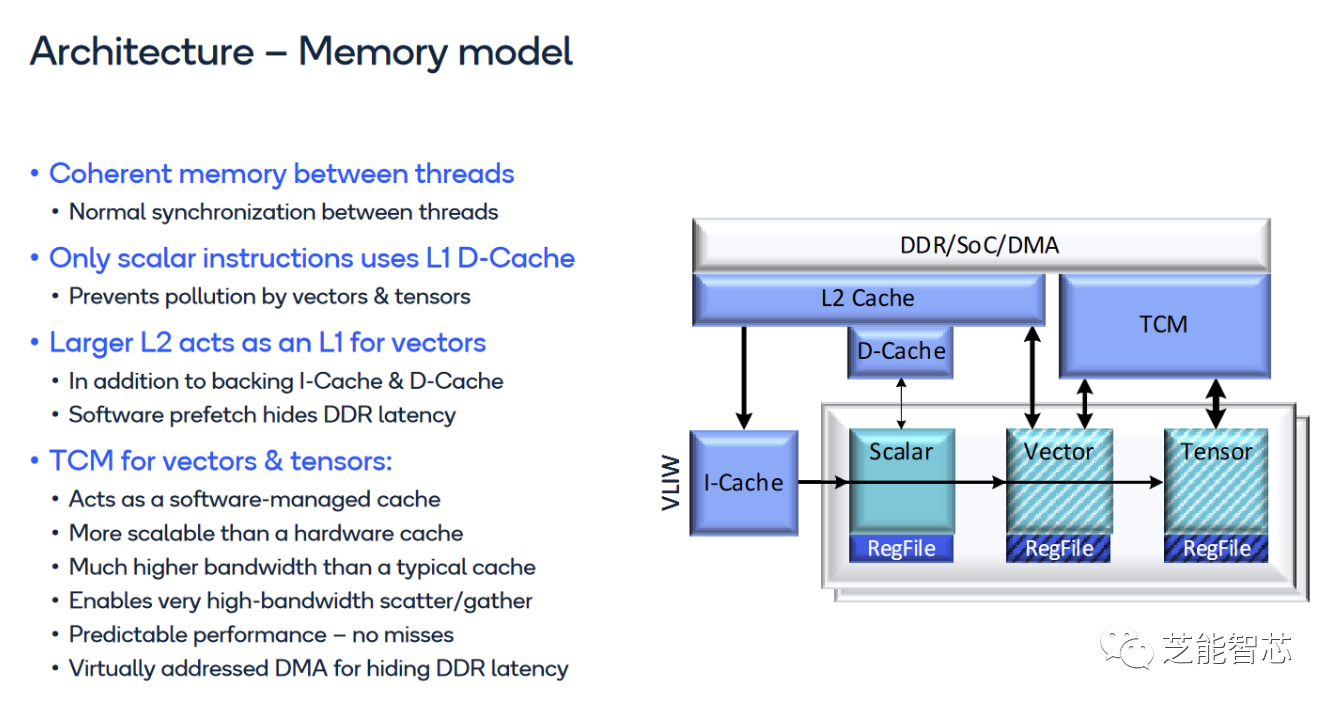
向量化应用程序需要访问很多数据,Qualcomm甚至不在L1里缓存向量访问。相反,矢量单元直接用L2缓存作为它的第一级缓存。除了L2缓存,Hexagon还有一个大型TCM(紧密耦合内存)。这是一种软件管理的临时存储器,类似于AMD GCN的LDS,但更大。在骁龙8 Gen 2的Hexagon上,有一个8 MB的TCM。
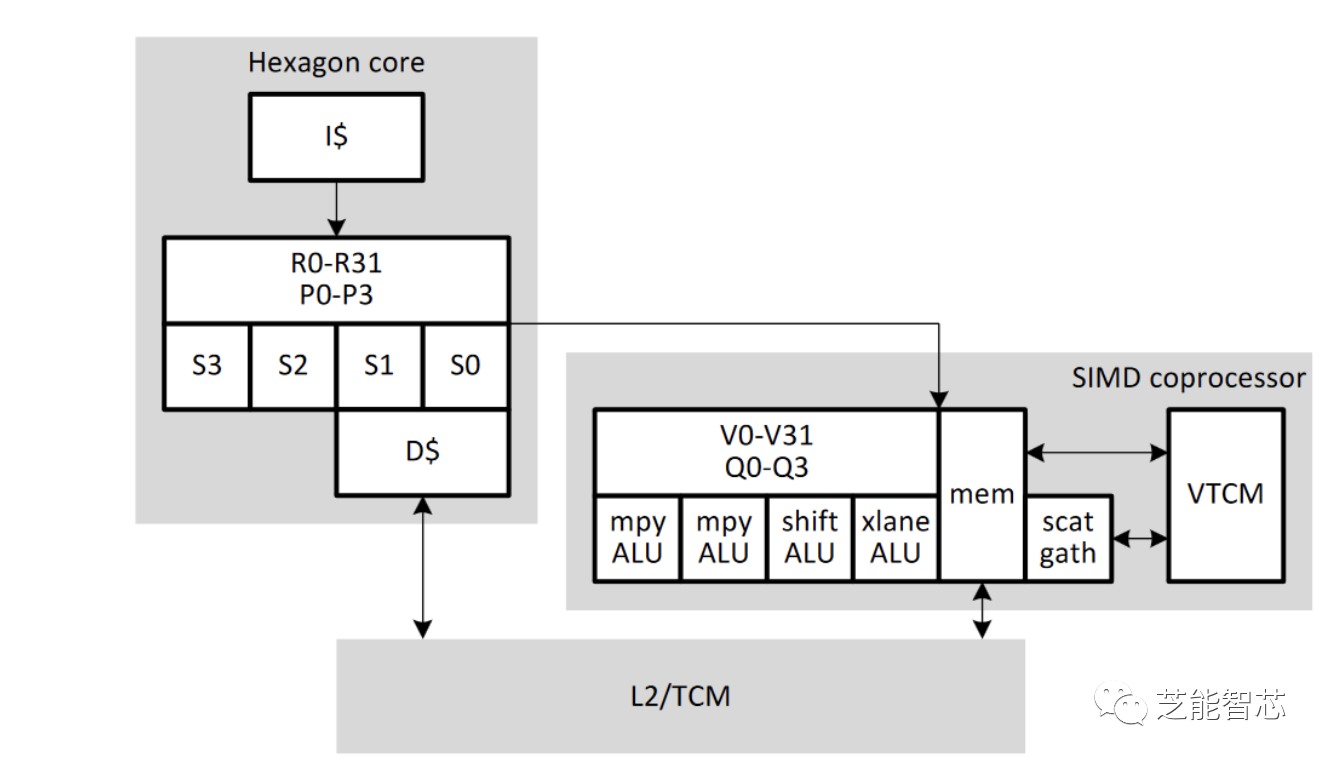
TCM对于Hexagon的散点和聚集操作很重要。散点和聚集操作是一种可以把数据从内存中的不连续位置放到向量里,或者反过来的操作。对于缓存来说,散点和聚集操作很难处理,因为一个1024位向量可能需要访问128个不同的地址。在关联组缓存中查找一行需要比较很多次。最坏的情况下,散点操作可能需要比较1024次。因为TCM不是缓存,它不用比较,所以更快。Hexagon甚至不在可缓存的内存上执行散点和聚集操作,只在TCM上执行。 
除了大型矢量寄存器文件,HVX为每个线程提供了四个128位谓词寄存器。谓词寄存器可以保存向量比较的结果,并且可以用作某些指令的掩码,例如条件累积。
过去的Hexagon实现主要做向量整数操作,但为了让HVX更灵活,Qualcomm增加了浮点功能。 
机器学习促使Qualcomm在Hexagon中添加了一个张量协作器。张量协作器可以做矩阵乘法这样的运算,这样每条指令就可以做更多的事情,而且省电。累加器也得到了特殊处理,因为它们只用来保存结果,而不用读取。 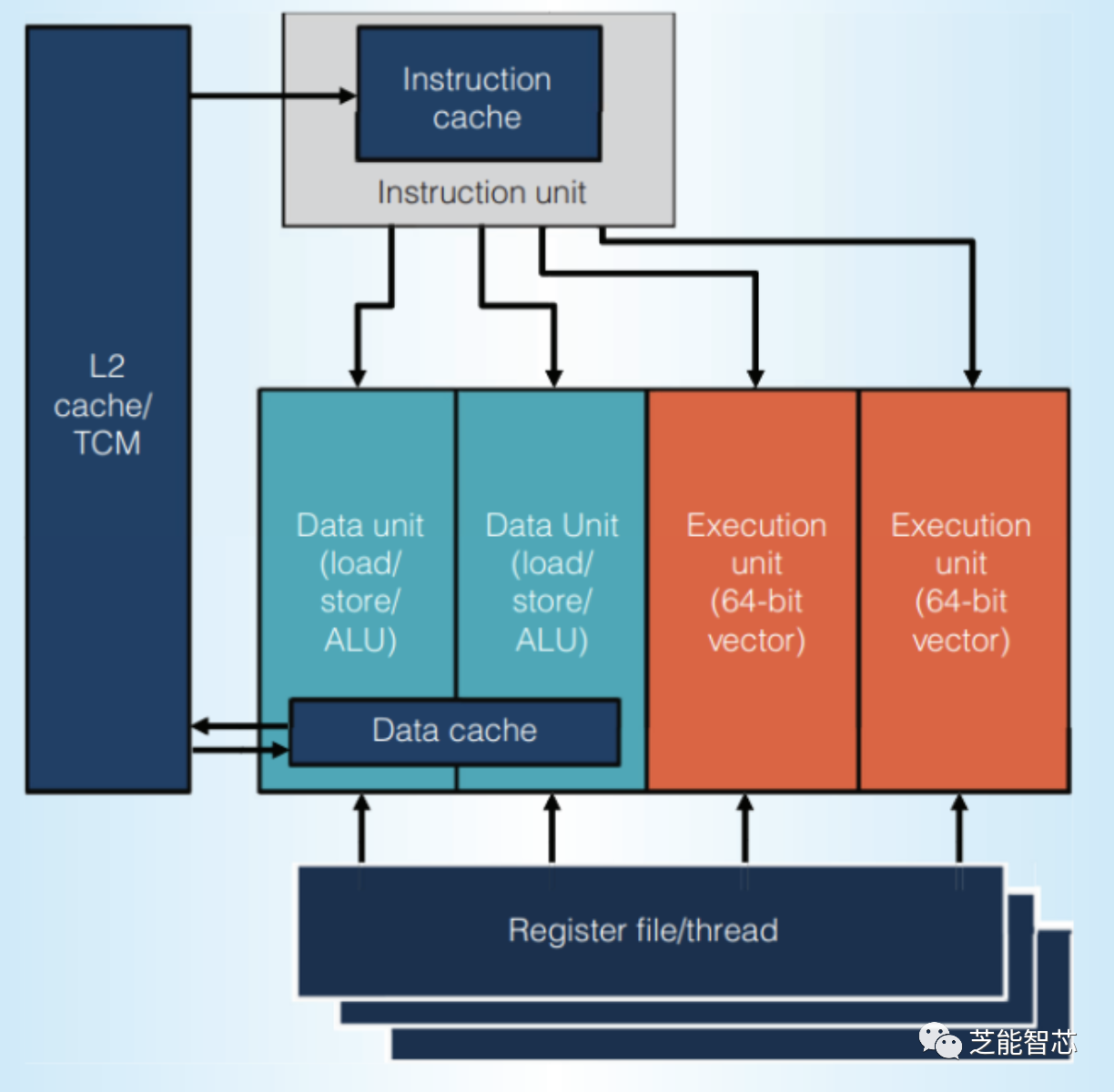
总结:Hexagon让我们看到了DSP奇妙世界的一部分。它介于CPU和GPU之间,既有CPU舒适功能,又有GPU强大功能。它使用VLIW执行来平衡灵活性和性能。它有一个强大的标量单元来处理轻量级DSP任务。
随着处理要求的增加,Qualcomm增加了HVX和张量协作器来提高DSP吞吐量。这些协作器可以处理向量和张量运算,并且有专门的内存技术来支持它们。

