
2022年的LoRA提高了微调效率,它在模型的顶部添加低秩(即小)张量进行微调。模型的参数被冻结。只有添加的张量的参数是可训练的。
与标准微调相比,它大大减少了可训练参数的数量。例如,对于Llama 27b, LoRA通常训练400万到5000万个参数,这比标准微调则训练70亿个参数药效的多。还可以使用LoRA来微调量化模型,例如,使用QLoRA:
虽然LoRA可训练参数的数量可能比模型参数小的多。但它随着张量(在LoRA中通常表示为r)的秩和目标模块的数量而增加。如果我们想要以大秩r(假设大于64)和模型的所有模块为目标(达到最佳性能),那么我们可能仍然需要训练数亿个参数。
本周又发布了VeRA,以进一步减少LoRA可训练参数的数量。
VeRA: Vector-based Random Matrix Adaptation
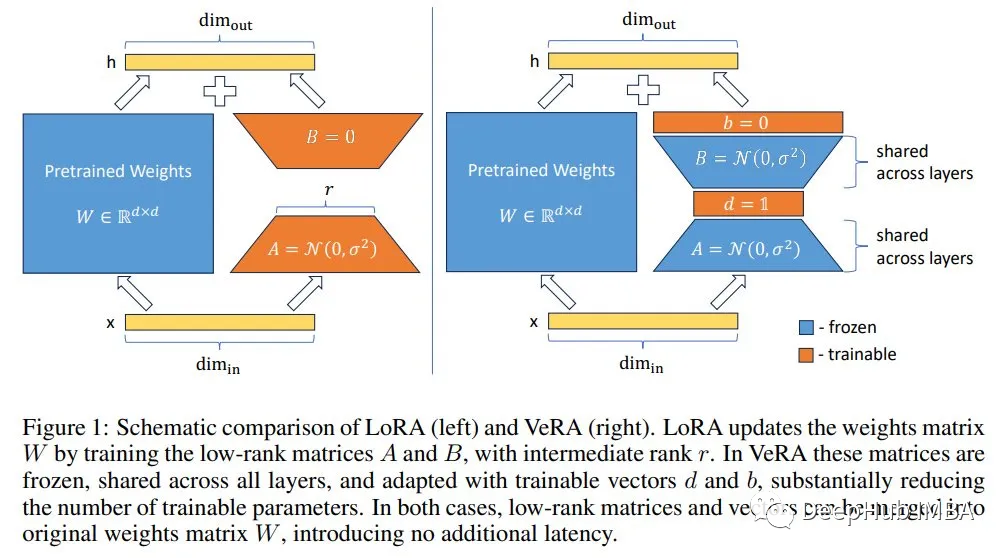
VeRA在LoRA冻结的低秩张量上添加可训练向量,只训练添加的向量。论文中显示的大多数实验中,VeRA训练的参数比原始LoRA少10倍。
但是原始的低秩张量(上图右侧中的A和B)呢?他们是如何训练或初始化的?
A和B随机初始化,然后冻结。这样它们虽然看起来像两个无用的张量我们可以在这个框架中去掉它们,但实际上,它们仍然是必不可少的。即使是随机张量也可以用于训练。论文的第2节,作者通过列举以前的论文,从之前的工作中得出结论:

作者最后也表示这些论文为冻结随机矩阵的应用创造了令人信服的案例。可以为VeRA提供理论和经验基础。
模型指标
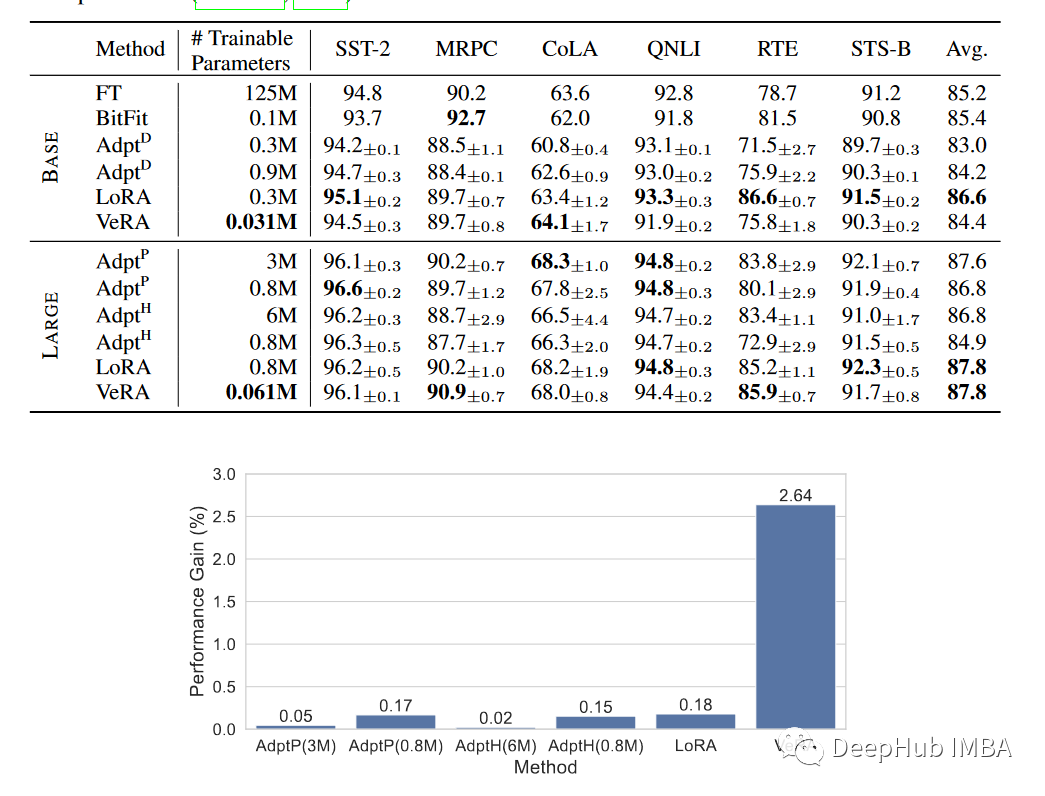
GLUE评分
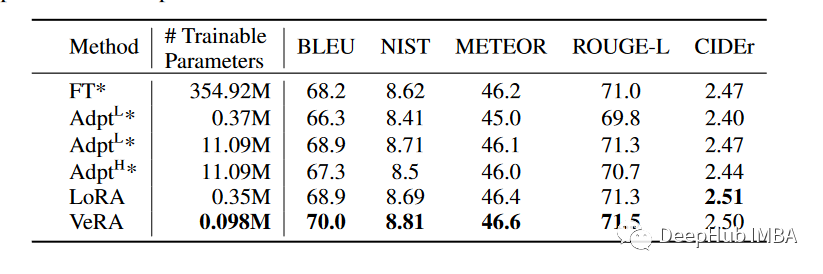
E2E
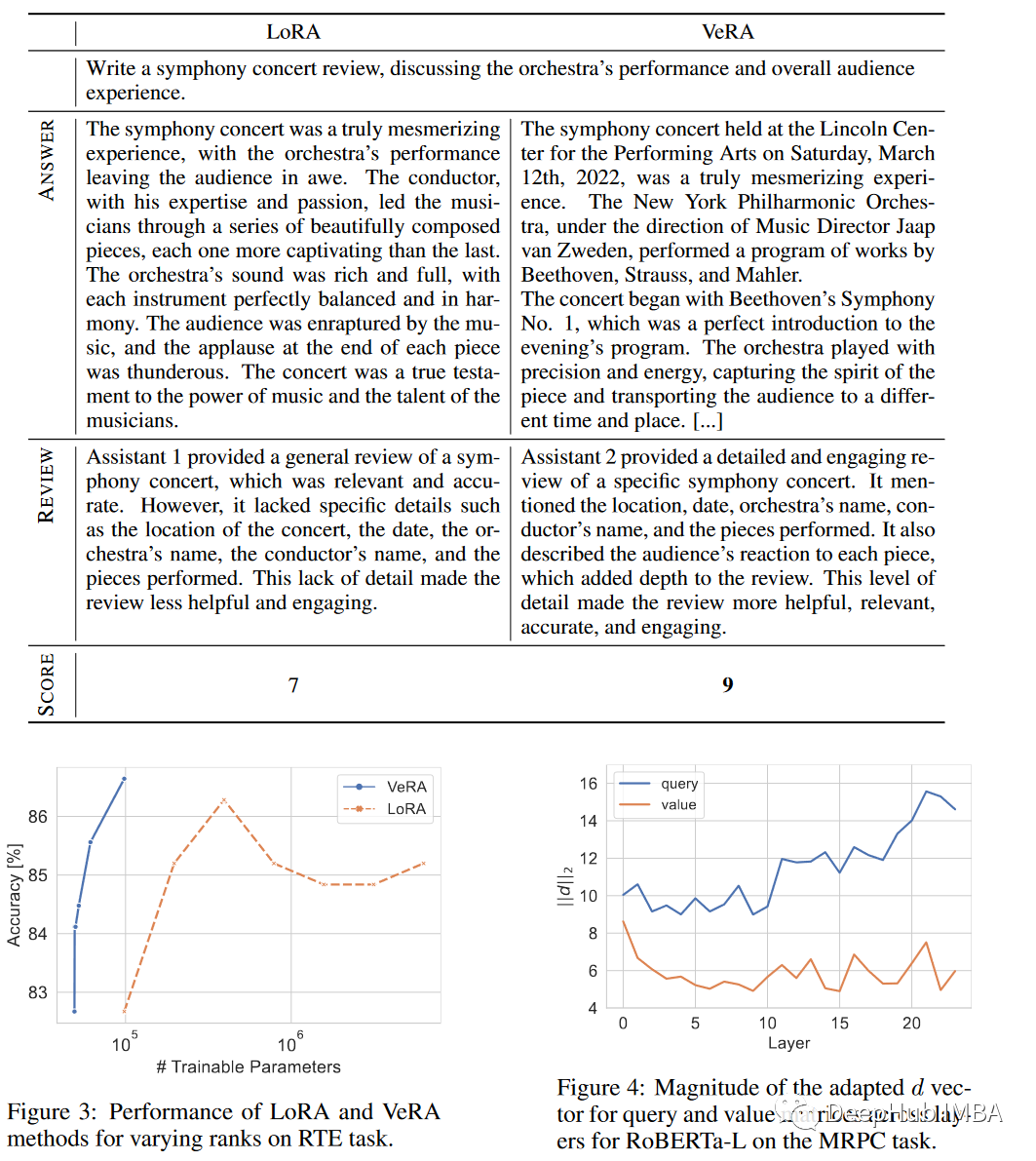
消融研究
总结
作为新的一种微调方法,VeRA显著减少了可训练参数的数量,而精度没有损失。与LoRA相比参数减少了10倍在GLUE基准测试中,robertta large的性能相同,但在GPT-2 medium的E2E基准测试中,性能降低了30%,说明这种方法特别适合于需要频繁交换大量微调模型的场景,比如针对个人用户个性化的基于云的人工智能服务。由于缩放向量尺寸小,可以将许多版本驻留在单个GPU的有限内存中,从而大大提高了服务效率,并消除了将特定模型加载到内存中的瓶颈。
VeRA: Vector-based Random Matrix Adaptation
https://avoid.overfit.cn/post/0c18ad6b818c4e11ae5c54825ef4857a

