
这是一篇2022由纽约州立大学布法罗分校和Meta AI发布的论文,它主要的观点如下:
具有专家混合(MoEs)的稀疏激活mlp在保持计算常数的同时显着提高了模型容量和表达能力。此外gMLP表明,所有mlp都可以在语言建模方面与transformer相匹配,但在下游任务方面仍然落后。所以论文提出了sMLP,通过设计确定性路由和部分预测来解决下游任务方面的问题。
sMLP
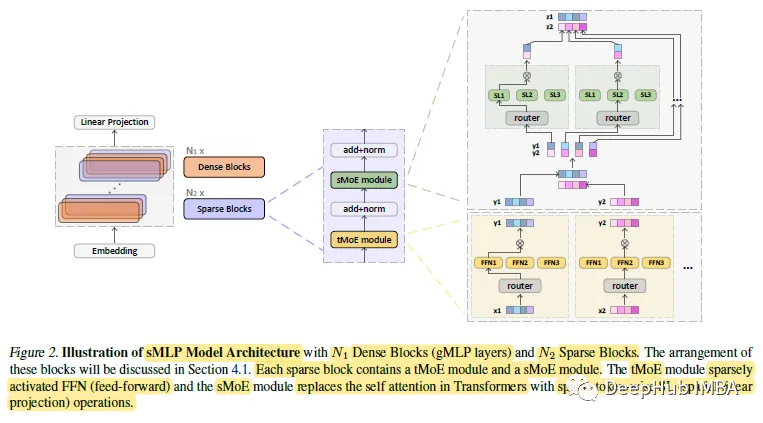
sMLP模型包含N1个密集块和N2个稀疏块。在每个稀疏块中,包含两个模块:
tMoE模块:采用Base Layers (Lewis et al., 2021)中的MoE代替transformer中的FFN模块。
sMoE模块:这是轮文提出的sMoE模块,目的是为了取代gMLP的自注意模块和空间门控单元。
稀疏激活 all-MLP
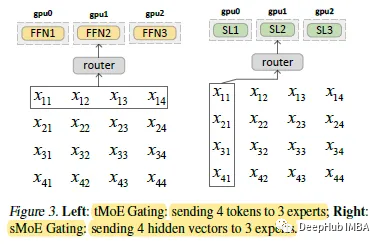
左:一个来自现有基于transformer的moe (tMoE)的门控功能示例。tMoE使用学习到的门控函数将这四个令牌发送给FFN层的3位专家。
右图:在稀疏的all-MLP体系结构中,论文提出沿隐藏维度对隐藏表示进行分块,并将分块向量发送给不同的专家。
特征空间中的路由
与路由令牌相比,路由隐藏维度在自回归模型中面临着独特的挑战,如果只预测未来的令牌,信息就会泄露。
所以采用确定性路由,将向量在隐藏维度上进行分块,并将隐藏向量确定性地发送给专家。并且令牌X1的前20%用于决定路由,令牌X2的其余80%用于预测。
训练方法是不在整个序列长度T上训练语言模型,而是训练它来预测X2。而X1用来学习门控权值Wr。
结果
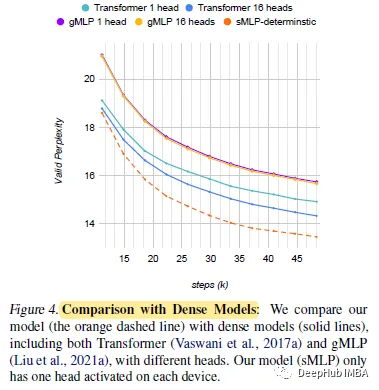
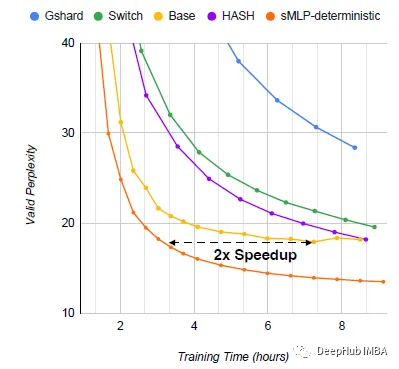
sMLP显著地提高了全基于mlp的模型的性能,并且也优于Transformer模型。
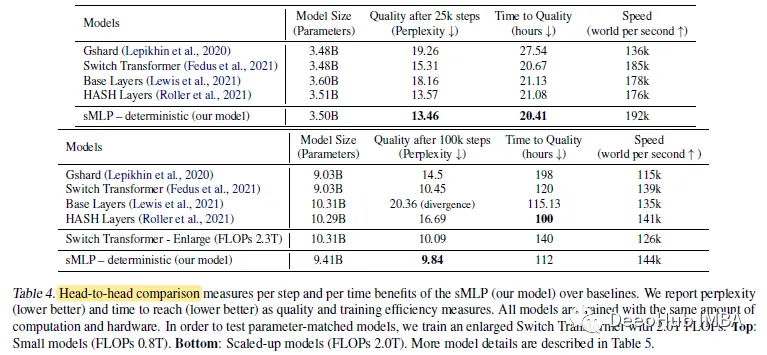
sMLP在25k训练步长时达到了最好的泛化效果,同时达到了最高的训练速度。
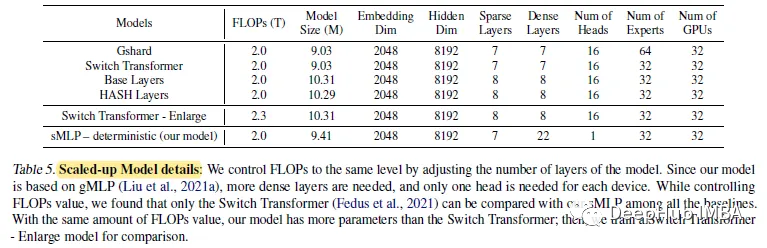
对于2.0 TFLOPs训练,模型大小增加。嵌入从1024调整为2048,隐藏维数从4096调整为8192。
sMLP仍然优于Switch Transformer,并且后者有更多的flop。
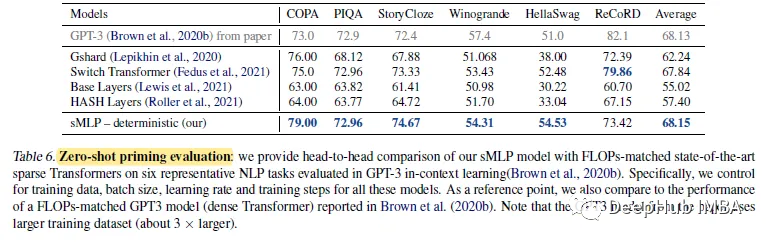
sMLP在平均精度方面优于所有稀疏Transformers 。显著的改进来自常识推理任务,如COPA、StoryCloze和HellaSwag。
论文地址:
Efficient Language Modeling with Sparse all-MLP
https://avoid.overfit.cn/post/92556271c70242719a322ad2788f4066

