
RAG领域已经取得了相当大的发展,这篇论文的是如何分解RAG过程,加入多文件检索、记忆和个人信息等定制化的元素。
大型语言模型(llm)在自然语言任务中表现出色,但在对话系统中的个性化和上下文方面面临挑战。这个研究提出了一个统一的多源检索-增强生成系统(UniMS-RAG),通过将任务分解为知识来源选择、知识检索和响应生成来解决个性化问题。

这个系统包括一个自我改进的机制,这个机制基于响应和检索证据之间的一致性分数迭代地改进生成的响应。实验结果表明,UniMS-RAG在知识来源选择和响应生成任务方面具有先进的性能。
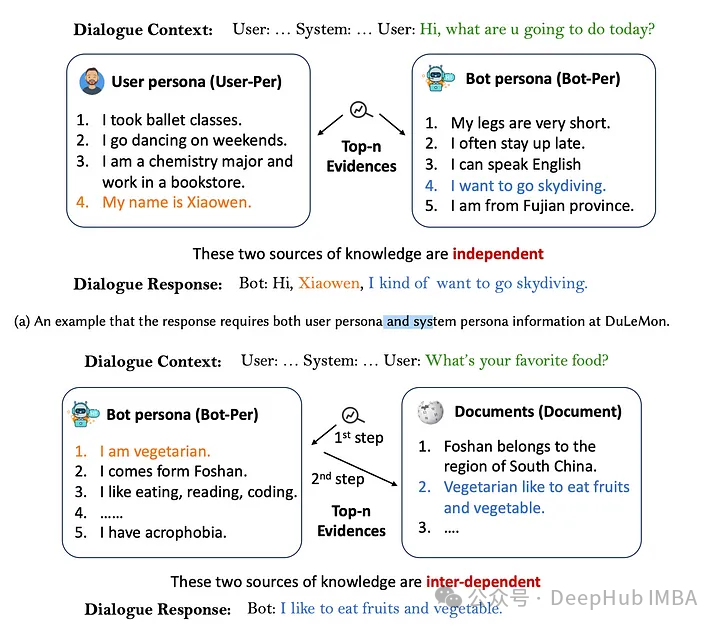
上图展示了两个场景,其中用户和机器人角色是独立的,而在第二个示例中则是相互依赖的。对于相互依赖的方法,需要有评估令牌和代理令牌。
论文要点
1、知识来源选择
智能和准确的知识来源选择和对多个信息来源综合成一个连贯而简洁的答案将变得至关重要。
使用RAG的一个优点是其实现的简单。但是在agenic RAG、多文档搜索和添加会话历史等方面,还需要很多的手动工作。代理RAG是将代理层次结构与RAG实现相结合的地方,这会带来很大的复杂性。
2、个性化与情境
个性化和通过会话历史维护上下文是优秀用户体验的重要元素。UniMS-RAG会对这些元素进行优先排序。
3、持续改进
论文的方法还包括一种自我细化推理算法,通过结合RAG会带来很大程度的可检查性和可观察性。
UniMS-RAG框架
UniMS-RAG统一了计划、检索和阅读任务的训练过程,并将它们集成到一个综合框架中。利用大型语言模型(llm)的力量来利用外部知识来源,UniMS-RAG增强了llm在个性化知识基础对话中无缝连接各种资源的能力。这种集成简化了传统上分离的检索器和训练任务,并允许以统一的方式进行自适应证据检索和相关性评分评估。
下图是所提出的称为UniMS-RAG的方法的说明。
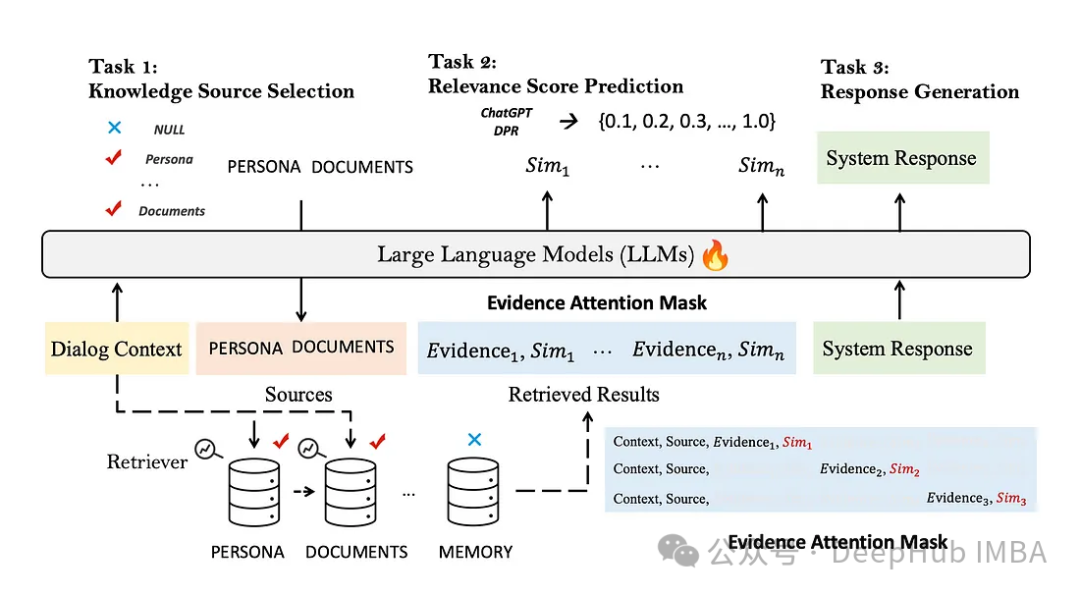
精心设计了三个优化任务:
Knowledge Source Selection:知识来源选择在给定不同来源之间的关系的情况下,创建一系列应该使用哪些特定知识来源的决策的过程。
Relevance Score Prediction:相关性评分预测会根据决策从外部数据库检索前n个结果。
Response Generation:最终将所有检索到的知识合并到最终的响应,生成结果
总结
论文提出的方法可在多源环境中解决个性化的基于知识的对话任务,将问题分解为三个子任务:知识库选择、知识检索和响应生成。提出的统一多源检索-增强对话系统(UniMS-RAG)使用大型语言模型(llm)同时作为计划者、检索者和读者。
这个框架在推理过程中还引入了自改进,使用一致性和相似性分数来改进响应。
在两个数据集上的实验结果表明,UniMS-RAG产生了更加个性化和真实的反应,优于基线模型。
论文地址:
https://avoid.overfit.cn/post/93a42fde82df483d8d64e286eb3a726a

