
LiRank是LinkedIn在2月份刚刚发布的论文,它结合了最先进的建模架构和优化技术,包括残差DCN、密集门控模块和Transformers。它引入了新的校准方法,并使用基于深度学习的探索/利用策略来优化模型,并且通过压缩技术,如量化和词表压缩,实现了高效部署。
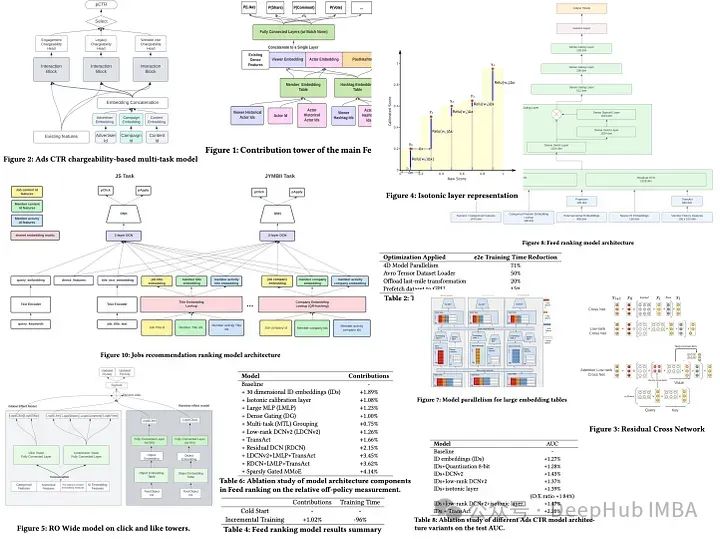
LinkedIn将其应用于Feed、职位推荐和广告点击率预测后,带来了显著的性能改进:Feed的会员会话增加了0.5%,工作申请增加了1.76%,广告点击率提高了4.3%。
Large ranking models
Feed排名模型
LinkedIn的主要Feed排名模型使用逐点方法来预测每个member 和候选post对的各种行为(喜欢、评论、分享、投票、点击和长停留)的可能性。这些预测被线性组合起来计算出一个post的最终得分。
模型是建立在TensorFlow多任务学习架构上,有两个主要组件:用于点击和长停留概率的点击塔,以及用于贡献动作和相关预测的贡献塔。两个塔使用相同的规范化密集特征和多个全连接层,而稀疏ID嵌入特征通过查找特定嵌入表转换为密集嵌入。
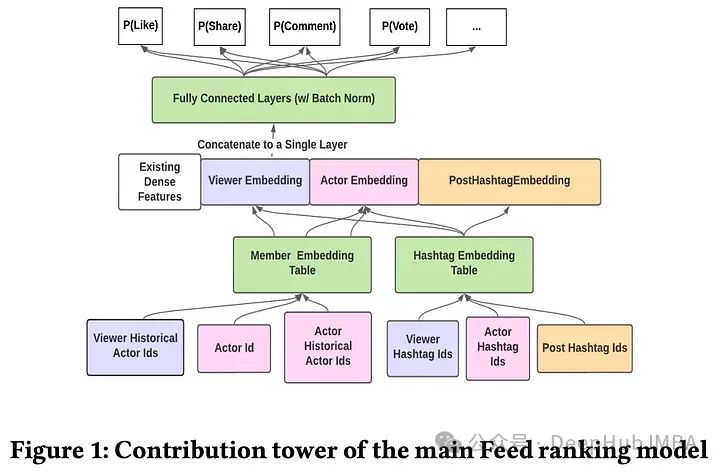
广告点击率模型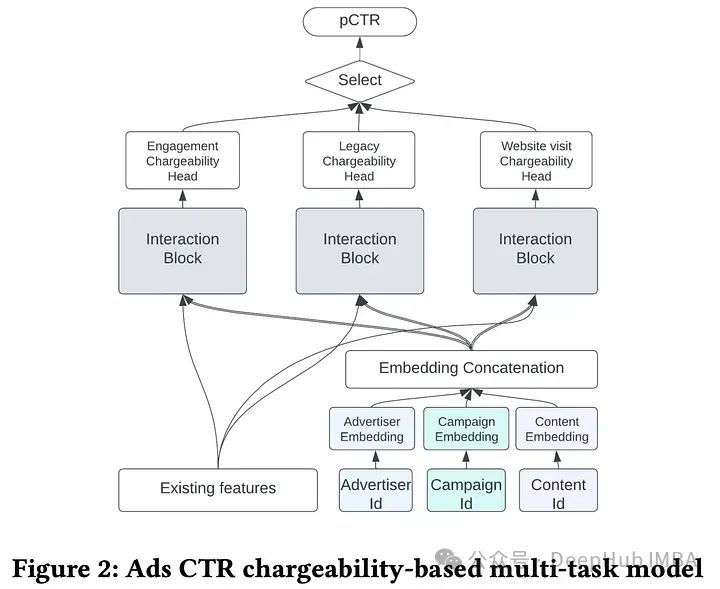
广告选择使用点击率预测模型来估计会员点击推荐广告的可能性,然后为广告拍卖决策提供信息。一些广告商会计算“喜欢”或“评论”等社交互动,而另一些广告商只考虑对广告网站的访问量,所以广告商可以定义什么是可收费的行为。CTR预测模型是一个MTL模型,有三个头用于不同的收费类别,将相似的收费行为分组在一起。每个头使用独立的交互块,包括MLP和DCNv2。模型还结合了来自会员和广告商的传统特征,以及代表广告商、活动和广告的ID特征。
DCNv2
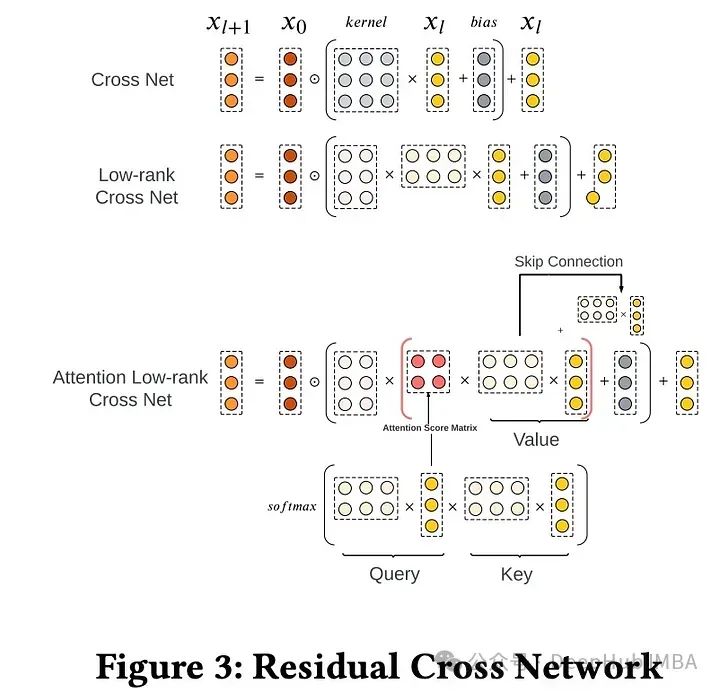
为了增强特征交互捕获能力,采用了DCNv2模块。作者用两个低秩矩阵替换了权重矩阵,并通过嵌入表查找降低了输入特征维度,实现了近30%的参数减少,这样可以大大降低DCN在大特征输入维度下的参数数量。另外还加入了低秩近似的注意力机制。
等温校准层(Isotonic Calibration Layer)
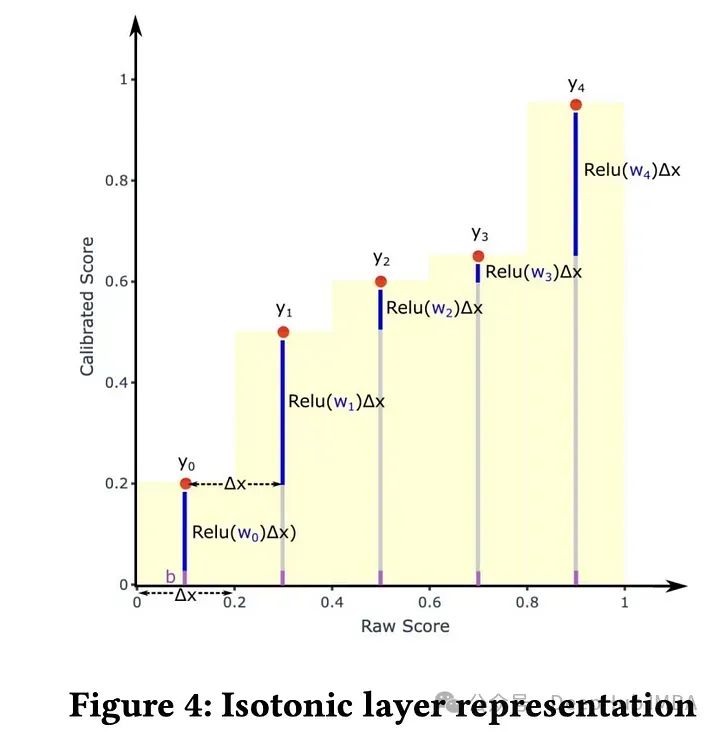
在深度神经网络(DNN)中,等温校准层(Isotonic Calibration Layer)用于改善网络输出概率的校准。校准指的是预测的概率与真实事件发生的概率之间的一致性。
模型校准对于确保估计的类别概率准确反映真实情况至关重要,由于参数空间的限制和多特征的可扩展性问题,传统的校准方法如Platt标度和等温回归在深度神经网络中面临挑战。为了克服这些问题,作者开发了一个定制的等温回归层,并直接与深度神经网络集成。这一层在网络中是可训练的,它使用分段拟合的方法对预测值进行分类,并为每个分类分配可训练的权重。ReLU激活函数通过非负权重保证了等温性。对于具有多个特征的校准,将权重与校准特征的嵌入表示相结合,增强了模型的校准能力。
门控和MLP
个性化嵌入被添加到全局模型中,可以促进密集特征之间的交互,包括多维计数和分类特征。作者发现增加MLP层的宽度可以提高模型性能,最大的测试配置是具有4层的MLP,每个层宽3500个单元,主要在使用个性化嵌入时显示增益。作者在隐藏层引入了受Gate Net启发的门控机制来调节信息流,以最小的额外计算成本增强学习,并持续提高在线性能。
增量训练
大型推荐系统需要经常更新,作者使用增量训练,不仅从先前的模型初始化权值,而且根据当前和先前模型权值的差异添加信息正则化项,并通过遗忘因子进行调整。为了进一步减轻灾难性遗忘,还将初始冷启动模型和先验模型都用于权重初始化和正则化,并且引入一个称为冷权重的新参数来平衡初始模型和先验模型的影响。
训练的可扩展性

为了增强训练大型排名模型的可扩展性,使用了几种优化技术:
4D模型并行:利用Horovod跨多个gpu扩展同步训练,在TensorFlow中实现了4D模型并行方法。该方法通过全对全通信模式促进特征交换,减少了梯度同步时间,将训练时间从70小时减少到20小时。
Avro张量数据集加载器:作者实现了一个优化的TensorFlow Avro读取器(并且开源),实现了比现有读取器快160倍的性能。优化包括删除不必要的类型检查、融合I/O操作和自动平衡线程,从而将端到端训练时间减半。
预取数据到GPU:为了解决CPU到GPU内存复制的开销,特别是在更大的批处理规模下,使用自定义的TensorFlow数据集管道和Keras输入层在下一个训练步骤之前并行预取数据到GPU,优化训练期间GPU资源的使用。
实验结果
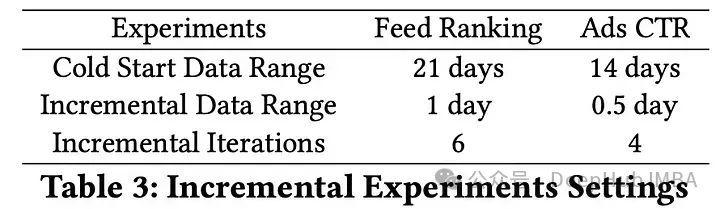
增量训练应用于Feed排名和广告点击率模型,在调整参数后显示出指标的显著的改进和训练时间的减少。

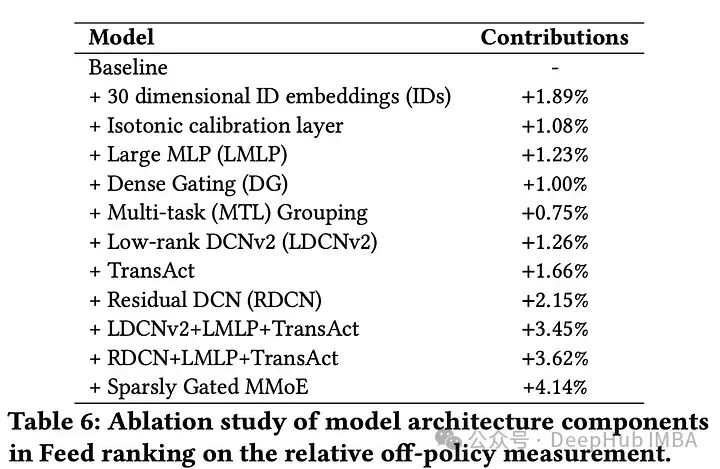
对于Feed排名,通过伪随机排名方法估计在线贡献率(喜欢、评论、转发),使用离线“重放”指标来比较模型。这种方法允许对模型进行无偏的离线比较。
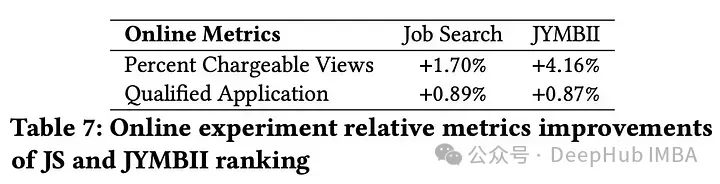
在工作中,嵌入字典压缩和特定于任务的DCN层在没有性能损失的情况下,显著提升了工作职位搜索和JYMBII模型的离线AUC。这使得在线a /B测试中的合格工作申请程序提高了1.76%。

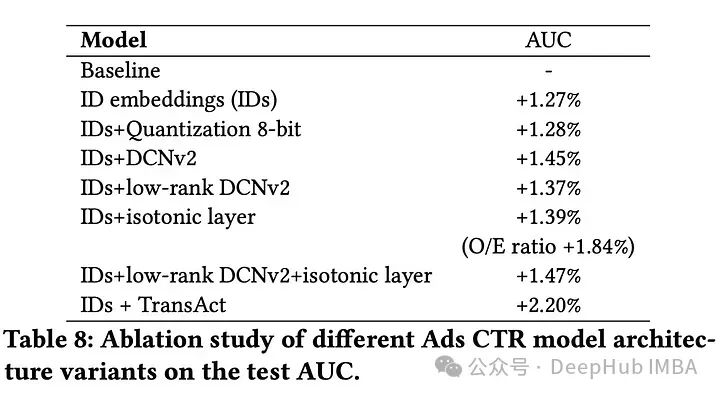
对于广告点击率,在多层感知机基线模型的基础上,使用ID嵌入、量化和等渗校准等技术进行了渐进式改进。这些技术使得在线a /B测试的点击率相对提高了4.3%。
总结
这是一篇非常好的论文,不仅介绍了模型的细节,还介绍了LinkedIn是如何在线上部署训练和管理模型、处理大量数据的,这些经验都值得我们学习。
为什么LinkedIn会一直关注排名模型?
LinkedIn是一个面向职业人士的社交网络平台也就是说它的用户比FB更加专业,更加集中。这样对于数据方面是有天然的优势的。另外LinkedIn的业务也比较单一,所以使用AI来改善业务需求也比FB等大型公司要大的多,并且效果也非常好评估,所以LinkedIn的这篇文章非常值得我们去深入的研究和学习。
论文地址:
https://avoid.overfit.cn/post/e3d54a21fd8b4cce8f730110aa1a65f2

