
随着开源大型语言模型的性能不断提高,编写和分析代码、推荐、文本摘要和问答(QA)对的性能都有了很大的提高。但是当涉及到QA时,LLM通常会在未训练数据的相关的问题上有所欠缺,很多内部文件都保存在公司内部,以确保合规性、商业秘密或隐私。当查询这些文件时,会使得LLM产生幻觉,产生不相关、捏造或不一致的内容。
为了处理这一挑战的一种可用技术是检索增强生成(retrieve - augmented Generation, RAG)。它涉及通过在响应生成之前引用其训练数据源之外的权威知识库来增强响应的过程。RAG应用程序包括一个检索系统,用于从语料库中获取相关文档片段,以及一个LLM,用于使用检索到的片段作为上下文生成响应,所以语料库的质量及其在向量空间中的表示(称为嵌入)在RAG的准确性中发挥重要作用。
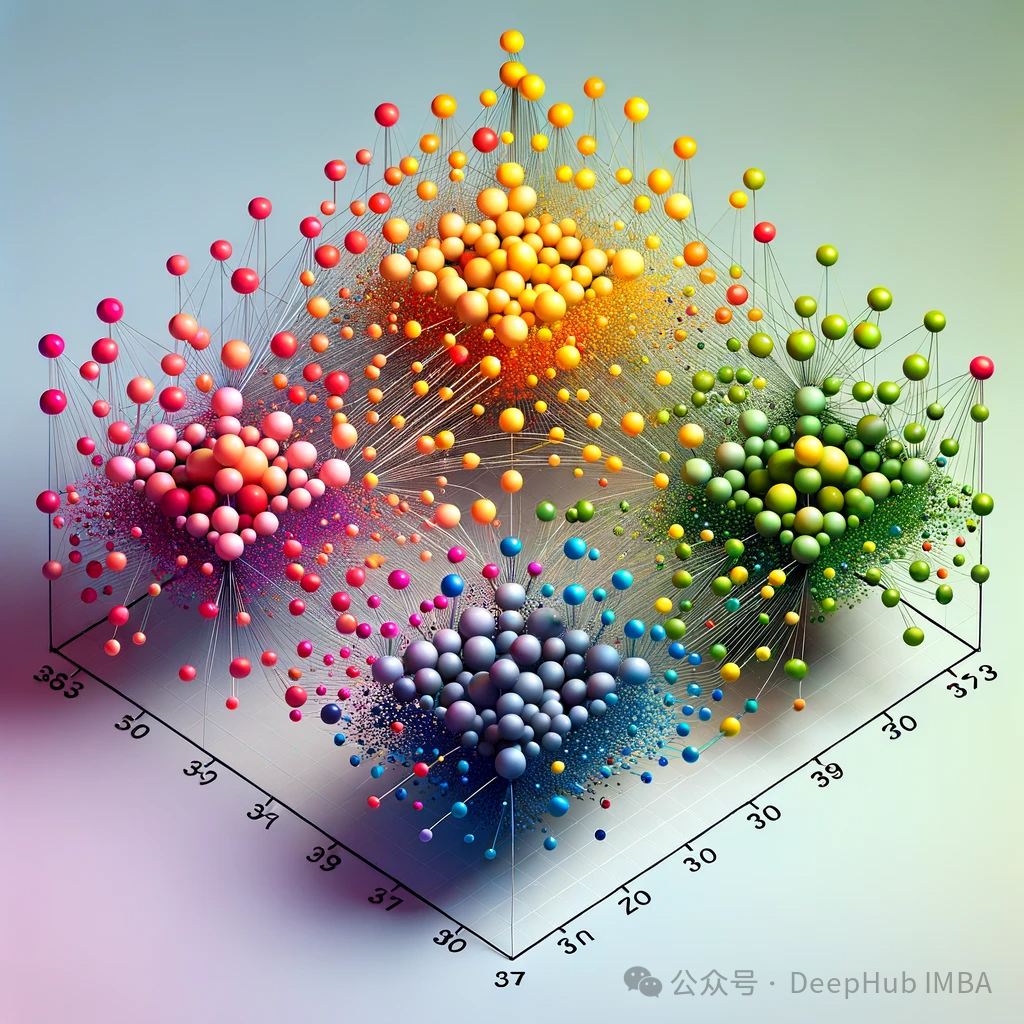
在本文中,我们将使用可视化库renumics-spotlight在2-D中可视化FAISS向量空间的多维嵌入,并通过改变某些关键的矢量化参数来寻找提高RAG响应精度的可能性。对于我们选择的LLM,将采用TinyLlama 1.1B Chat,这是一个紧凑的模型,与Llama 2相同的架构。它的优点是具有更小的资源占用和更快的运行时间,但其准确性没有成比例的下降,这使它成为快速实验的理想选择。
系统设计
QA系统有两个模块,如图所示。
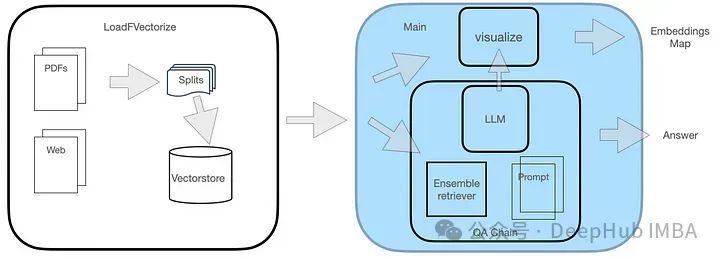
LoadFVectorize模块加载pdf或web文档。对于最初的测试和可视化。第二个模块加载LLM并实例化FAISS检索,然后创建包含LLM、检索器和自定义查询提示的检索链。最后我们对它的向量空间进行可视化。
代码实现
1、安装必要的库
renumics-spotlight库使用类似umap的可视化,将高维嵌入减少到更易于管理的2D可视化,同时保留关键属性。我们在以前的文章中也介绍过umap的使用,但是只是功能性的简单介绍,这次我们作为完整的系统设计,将他整合到一个真正可用的实际项目中。首先是安装必要的库:
pip install langchain faiss-cpu sentence-transformers flask-sqlalchemy psutil unstructured pdf2image unstructured_inference pillow_heif opencv-python pikepdf pypdf
pip install renumics-spotlight
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir上面的最后一行是安装带有Metal支持的llama- pcp -python库,该库将用于在M1处理器上加载带有硬件加速的TinyLlama。
2、LoadFVectorize模块
模块包括3个功能:
load_doc处理在线pdf文档的加载,每个块分割512个字符,重叠100个字符,返回文档列表。
vectorize调用上面的函数load_doc来获取文档的块列表,创建嵌入并保存到本地目录opdf_index,同时返回FAISS实例。
load_db检查FAISS库是否在目录opdf_index中的磁盘上并尝试加载,最终返回一个FAISS对象。
该模块代码的完整代码如下:
# LoadFVectorize.py
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import OnlinePDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
# access an online pdf
def load_doc() -> 'List[Document]':
loader = OnlinePDFLoader("https://support.riverbed.com/bin/support/download?did=7q6behe7hotvnpqd9a03h1dji&version=9.15.0")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=100)
docs = text_splitter.split_documents(documents)
return docs
# vectorize and commit to disk
def vectorize(embeddings_model) -> 'FAISS':
docs = load_doc()
db = FAISS.from_documents(docs, embeddings_model)
db.save_local("./opdf_index")
return db
# attempts to load vectorstore from disk
def load_db() -> 'FAISS':
embeddings_model = HuggingFaceEmbeddings()
try:
db = FAISS.load_local("./opdf_index", embeddings_model)
except Exception as e:
print(f'Exception: {e}\nNo index on disk, creating new...')
db = vectorize(embeddings_model)
return db3、主模块
主模块最初定义了以下模板的TinyLlama提示符模板:
<|system|>{context}</s><|user|>{question}</s><|assistant|>
另外采用来自TheBloke的量化版本的TinyLlama可以极大的减少内存,我们选择以GGUF格式加载量化LLM。
然后使用LoadFVectorize模块返回的FAISS对象,创建一个FAISS检索器,实例化RetrievalQA,并将其用于查询。
# main.py
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain_community.llms import LlamaCpp
from langchain_community.embeddings import HuggingFaceEmbeddings
import LoadFVectorize
from renumics import spotlight
import pandas as pd
import numpy as np
# Prompt template
qa_template = """<|system|>
You are a friendly chatbot who always responds in a precise manner. If answer is
unknown to you, you will politely say so.
Use the following context to answer the question below:
{context}</s>
<|user|>
{question}</s>
<|assistant|>
"""
# Create a prompt instance
QA_PROMPT = PromptTemplate.from_template(qa_template)
# load LLM
llm = LlamaCpp(
model_path="./models/tinyllama_gguf/tinyllama-1.1b-chat-v1.0.Q5_K_M.gguf",
temperature=0.01,
max_tokens=2000,
top_p=1,
verbose=False,
n_ctx=2048
)
# vectorize and create a retriever
db = LoadFVectorize.load_db()
faiss_retriever = db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}, max_tokens_limit=1000)
# Define a QA chain
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=faiss_retriever,
chain_type_kwargs={"prompt": QA_PROMPT}
)
query = 'What versions of TLS supported by Client Accelerator 6.3.0?'
result = qa_chain({"query": query})
print(f'--------------\nQ: {query}\nA: {result["result"]}')
visualize_distance(db,query,result["result"])向量空间可视化本身是由上面代码中的最后一行visualize_distance处理的:
visualize_distance访问FAISS对象的属性__dict__,index_to_docstore_id本身是值docstore-ids的关键索引字典,用于向量化的总文档计数由索引对象的属性ntotal表示。
vs = db.__dict__.get("docstore")
index_list = db.__dict__.get("index_to_docstore_id").values()
doc_cnt = db.index.ntotal调用对象索引的方法reconstruct_n,可以实现向量空间的近似重建
embeddings_vec = db.index.reconstruct_n()有了docstore-id列表作为index_list,就可以找到相关的文档对象,并使用它来创建一个包括docstore-id、文档元数据、文档内容以及它在所有id的向量空间中的嵌入的列表:
doc_list = list()
for i,doc-id in enumerate(index_list):
a_doc = vs.search(doc-id)
doc_list.append([doc-id,a_doc.metadata.get("source"),a_doc.page_content,embeddings_vec[i]])然后使用列表创建一个包含列标题的DF,我们最后使用这个DF进行可视化
df = pd.DataFrame(doc_list,columns=['id','metadata','document','embedding'])在继续进行可视化之前,还需要将问题和答案结合起来,我们创建一个单独的问题以及答案的DF,然后与上面的df进行合并,这样能够显示问题和答案出现的地方,在可视化时我们可以高亮显示:
# add rows for question and answer
embeddings_model = HuggingFaceEmbeddings()
question_df = pd.DataFrame(
{
"id": "question",
"question": question,
"embedding": [embeddings_model.embed_query(question)],
})
answer_df = pd.DataFrame(
{
"id": "answer",
"answer": answer,
"embedding": [embeddings_model.embed_query(answer)],
})
df = pd.concat([question_df, answer_df, df])这里使用使用np.linalg.norm在文件和问题嵌入上的进行距离大小的计算:
question_embedding = embeddings_model.embed_query(question)
# add column for vector distance
df["dist"] = df.apply(
lambda row: np.linalg.norm(
np.array(row["embedding"]) - question_embedding
),axis=1,)因为spotlight可以对df进行可视化,所有我们直接调用即可
spotlight.show(df)这一步将在浏览器窗口中启动spotlight。
运行测试
1、基本测试
下面是我们选择的样本问题:
What versions of TLS supported by Client Accelerator 6.3.0?
正确答案是:
Client Accelerator 6.3.0 supports TLS 1.1 or 1.2.
以下额外信息可能包含在响应中。
You must enable this capability using the following CLI command on the Client Accelerator:(config) # policy id <id-number> ssl backend client-tls-1.2Even though TLS 1.1 is not mentioned in the syntax of this command, using this command automatically enables support for both TLS 1.1 and 1.2.
然后我们看看TinyLlama对上述问题的回答:
Client Accelerator 6.3.0 supports TLS 1.1 or 1.2 as the default supported TLS versions with Client Accelerator. You must enable this capability using the following CLI command on the Client Accelerator:
(config) # policy id <id-number> ssl backend client-tlss1.2Note that this command only applies to TLS 1.1 or TLS 1.2. If you need to support older TLS versions, you can use thessl backendcommand with the
client-tlss1.0or
client-tlss1.1option instead.
看起来与实际答案非常相似,但它并不完全正确,因为这些TLS版本不是其默认值。
那么我们来看看他是从哪些段落中找到的答案呢?
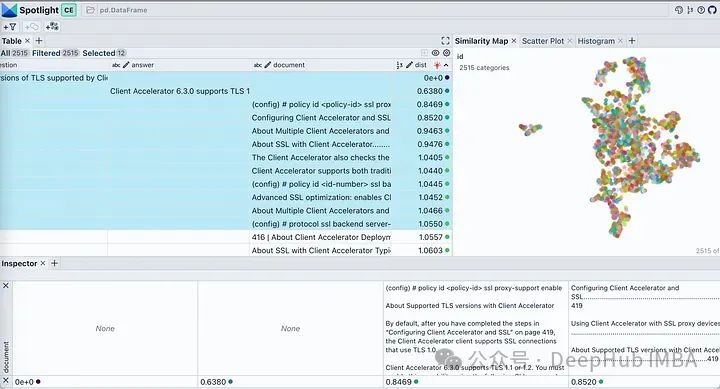
在可以spotlight中使用visible 按钮来控制显示的列。按“dist”对表格进行排序,在顶部显示问题、答案和最相关的文档片段。查看我们文档的嵌入,它将几乎所有文档块描述为单个簇。这是合理的,因为我们原始pdf是针对特定产品的部署指南,所以被认为是一个簇是没有问题的。
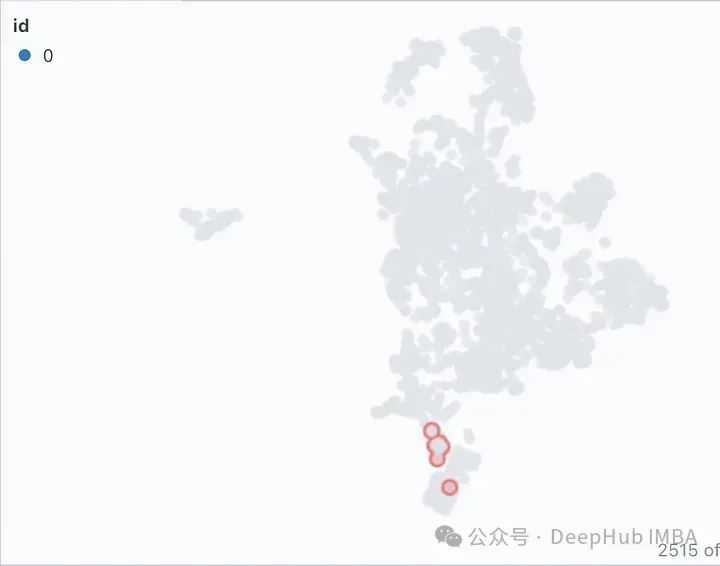
单击Similarity Map选项卡中的过滤器图标,它只突出显示所选的文档列表,该列表是紧密聚集的,其余的显示为灰色,如图下所示。
2、测试块大小和重叠参数
由于检索器是影响RAG性能的关键因素,让我们来看看影响嵌入空间的几个参数。TextSplitter的块大小chunk size(1000,2000)和/或重叠overlap (100,200)参数在文档分割期间是不同的。
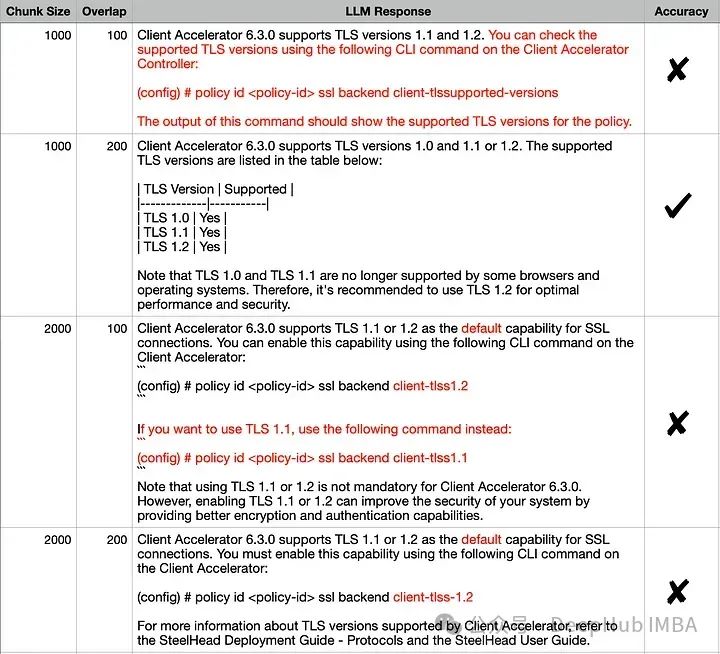
对所有组合的对于输出似乎相似,但是如果我们仔细比较正确答案和每个回答,准确答案是(1000,200)。其他回答中不正确的细节已经用红色突出显示。我们来尝试使用可视化嵌入来解释这一行为:
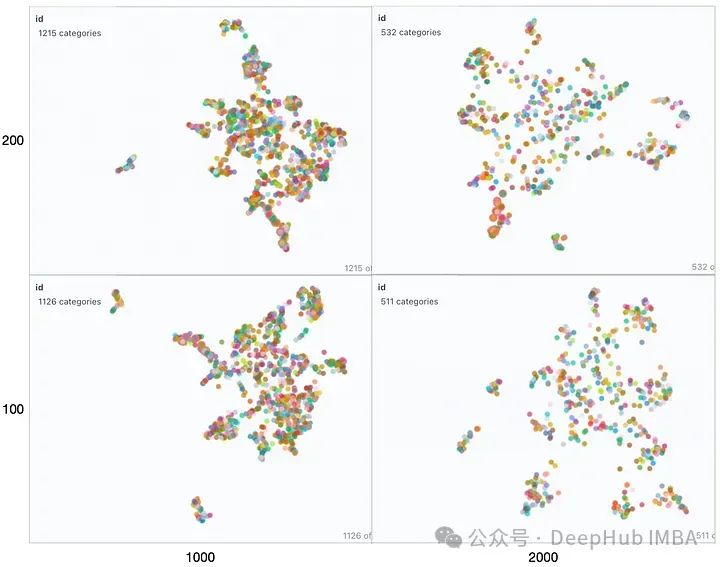
从左到右观察,随着块大小的增加,我们可以观察到向量空间变得稀疏且块更小。从底部到顶部,重叠逐渐增多,向量空间特征没有明显变化。在所有这些映射中整个集合仍然或多或少地呈现为一个单一的簇,并只有几个异常值存在。这种情况在生成的响应中是可以看到的因为生成的响应都非常相似。
如果查询位于簇中心等位置时由于最近邻可能不同,在这些参数发生变化时响应很可能会发生显著变化。如果RAG应用程序无法提供预期答案给某些问题,则可以通过生成类似上述可视化图表并结合这些问题进行分析,可能找到最佳划分语料库以提高整体性能方面优化方法。
为了进一步说明,我们将两个来自不相关领域(Grammy Awards和JWST telescope)的维基百科文档的向量空间进行可视化展示。
def load_doc():
loader = WebBaseLoader(['https://en.wikipedia.org/wiki/66th_Annual_Grammy_Awards','https://en.wikipedia.org/wiki/James_Webb_Space_Telescope'])
documents = loader.load()
...只修改了上面代码其余的代码保持不变。运行修改后的代码,我们得到下图所示的向量空间可视化。
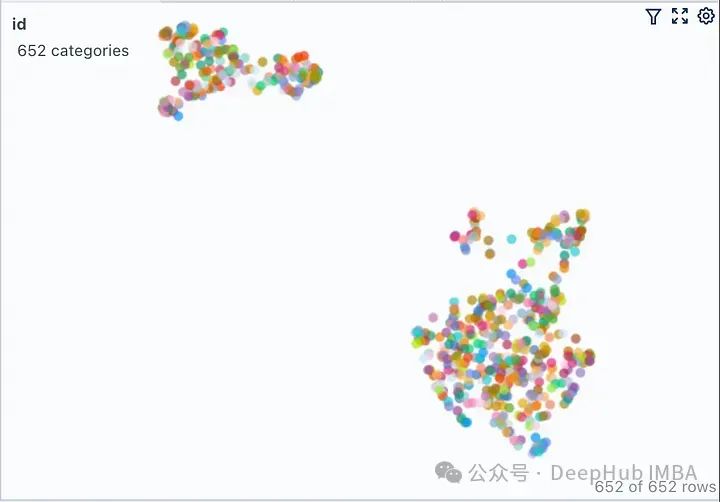
这里有两个不同的不重叠的簇。如果我们要在任何一个簇之外提出一个问题,那么从检索器获得上下文不仅不会对LLM有帮助,而且还很可能是有害的。提出之前提出的同样的问题,看看我们LLM产生什么样的“幻觉”
Client Accelerator 6.3.0 supports the following versions of Transport Layer Security (TLS):
- TLS 1.2\2. TLS 1.3\3. TLS 1.2 with Extended Validation (EV) certificates\4. TLS 1.3 with EV certificates\5. TLS 1.3 with SHA-256 and SHA-384 hash algorithms
这里我们使用FAISS用于向量存储。如果你正在使用ChromaDB并想知道如何执行类似的可视化,renumics-spotlight也是支持的。
总结
检索增强生成(RAG)允许我们利用大型语言模型的能力,即使LLM没有对内部文档进行训练也能得到很好的结果。RAG涉及从矢量库中检索许多相关文档块,然后LLM将其用作生成的上下文。因此嵌入的质量将在RAG性能中发挥重要作用。
在本文中,我们演示并可视化了几个关键矢量化参数对LLM整体性能的影响。并使用renumics-spotlight,展示了如何表示整个FAISS向量空间,然后将嵌入可视化。Spotlight直观的用户界面可以帮助我们根据问题探索向量空间,从而更好地理解LLM的反应。通过调整某些矢量化参数,我们能够影响其生成行为以提高精度。
https://avoid.overfit.cn/post/30168a23de744b3f91ec22da1725eb14

