
时间序列分析跨越了一系列广泛的应用,从天气预报到通过心电图进行健康监测。
但是由于缺乏大型且整合的公开时间序列数据,所以在时间序列数据上预训练大型模型具有挑战性。为了应对这些挑战,MOMENT团队整理了一个庞大而多样的公共时间序列集合,作者将其称为Time-series Pile。代码地址我们会在文章的最后贴出来。
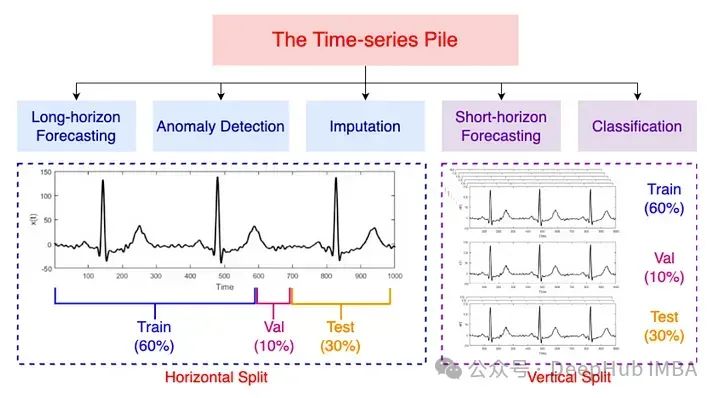
根据作者的介绍,MOMENT则是第一个开源,大型预训练时间序列模型家族。可以服务于各种时间序列分析任务的基础角色:预测,分类,异常检测和输入。为什么要在标题中说又一个呢,因为2024年刚过去3个月,我们已经看到好几个了。
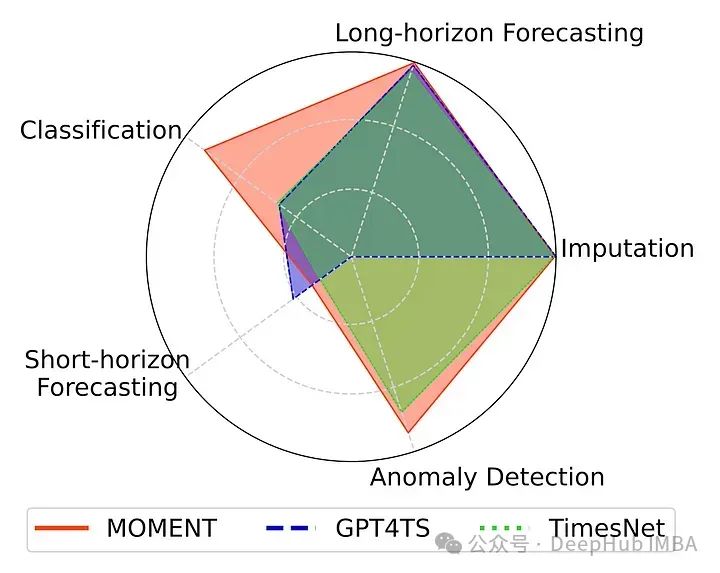
模型为高容量transformer 模型,通过屏蔽时间序列预测任务对不同数据集进行预训练。以下是MOMENT在各种任务下的表现
模型的背景
Transformers 在各个领域中发展迅速,但在时间序列任务中自注意力机制却带来了挑战,特别是当复杂度随输入大小而变化时。MOMENT利用遮蔽预训练,这是一种自我监督的学习方法,其中模型学习重建其输入的遮蔽部分。这种技术特别适合于预测和输入任务,可以有效地预测缺失或未来的数据点。
MOMENT探讨了如何通过以下方式使大型语言模型(llm)适应时间序列分析:
跨模态建模:时间序列Transformers 可以跨各种模态对序列进行建模。
随机初始化的好处:从随机权重开始比使用语言模型权重更有效。
优越的时间序列预训练:直接预训练的模型在任务和数据集上优于基于llm的模型。
MOMENT架构
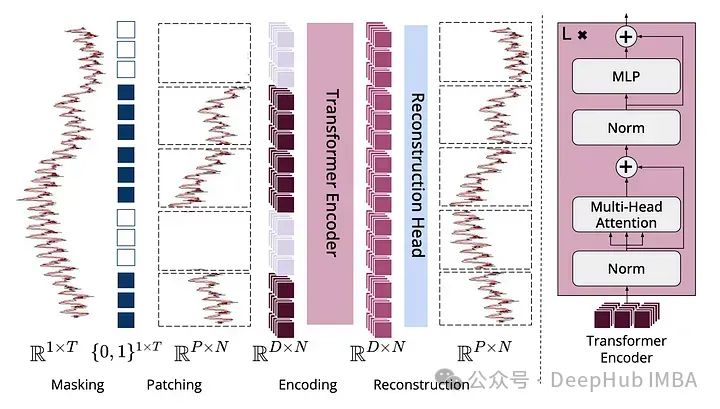
将时间序列分解为不相交的固定长度的子序列,称为patches,每个patches被映射到一个d维补丁嵌入中。在预训练过程中,通过使用一种特殊的掩码嵌入[mask]来替换其patches嵌入,从而均匀随机地对patches进行掩码。预训练的目标是学习可以使用轻量级重建头重建输入时间序列的嵌入。
这个方法和ViT是不是有点类似,看来对于所有的数据对于Transformer来说,都是patches,只不过是怎么分这个patches的问题。果然是 Patches Are All You Need
虽然这么说,但这个模型还是改进了一些Transformer架构,比如:
调整Layer norm的位置,去除附加偏差,并增加了关系位置嵌入。
MOMENT性能
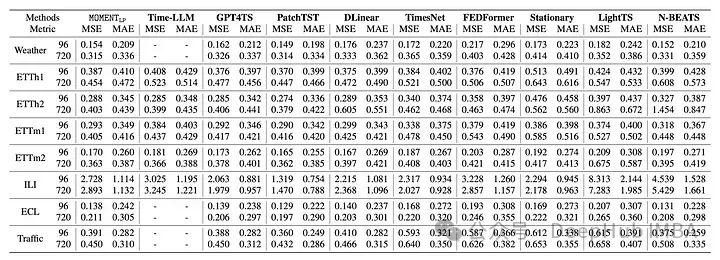
预测可以接近最先进的长期预测,在异常检测的多个数据集的上表现优异。对于时间序列的插值填充,也可以实现最低的重建误差(这应该是肯定的,因为mask就是来干这个的)
总结
论文的研究方法和设计在几个关键方面具有创新性。其中包括开发一套预训练时间序列模型的开源方法,创建“时间序列堆”以解决数据稀缺问题,多数据集预训练方法,以及在资源有限的情况下评估性能的基准框架。这些方法允许在各种时间序列分析任务(如预测、分类、异常检测和输入)之间有效地利用最小数据和特定于任务的微调。论文强调对时间序列数据进行大规模、多数据集的预训练,对隐含的时间序列特征(如趋势和频率)进行编码,并展示了这种方法的好处。
最后我个人感觉这种方法对于异常检测、插值填充和分类方面应该是可以超过传统的方法(因为这是mask的强项),但是真正对于数值的预测可能还不好说。
有兴趣的请自行阅读原文吧:
https://avoid.overfit.cn/post/14f11a68473d4612ab1779d845141609

