
NL2SQL进阶系列(1):DB-GPT-Hub、SQLcoder、Text2SQL开源应用实践详解
[NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]](https://blog.csdn.net/sinat_3...)
NL2SQL基础系列(2):主流大模型与微调方法精选集,Text2SQL经典算法技术回顾七年发展脉络梳理
1. MindSQL(库)
MindSQL 是一个 Python RAG(检索增强生成)库,旨在仅使用几行代码来简化用户与其数据库之间的交互。 MindSQL 与 PostgreSQL、MySQL、SQLite 等知名数据库无缝集成,还通过扩展核心类,将其功能扩展到 Snowflake、BigQuery 等主流数据库。 该库利用 GPT-4、Llama 2、Google Gemini 等大型语言模型 (LLM),并支持 ChromaDB 和 Fais 等知识库。
官方链接:https://pypi.org/project/mind...
https://github.com/Mindinvent...
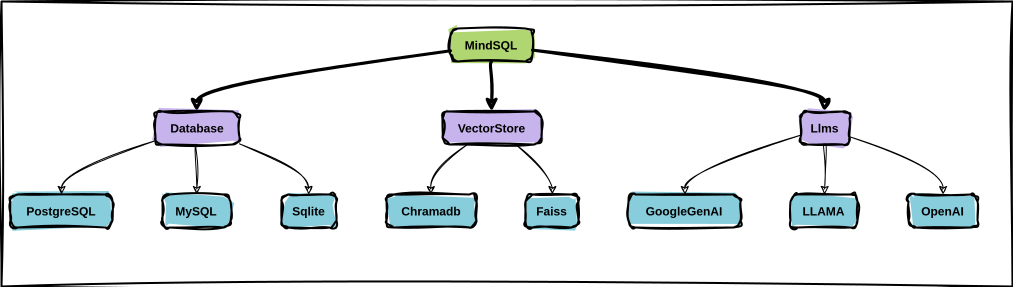
使用案例
#!pip install mindsql from mindsql.core import MindSQLCore from mindsql.databases import Sqlite from mindsql.llms import GoogleGenAi from mindsql.vectorstores import ChromaDB #Add Your Configurations config = {"api_key": "YOUR-API-KEY"} #Choose the Vector Store. LLM and DB You Want to Work With And #Create MindSQLCore Instance With Configured Llm, Vectorstore, And Database minds = MindSQLCore( llm=GoogleGenAi(config=config), vectorstore=ChromaDB(), database=Sqlite() ) #Create a Database Connection Using The Specified URL connection = minds.database.create_connection(url="YOUR_DATABASE_CONNECTION_URL") #Index All Data Definition Language (DDL) Statements in The Specified Database Into The Vectorstore minds.index_all_ddls(connection=connection, db_name='NAME_OF_THE_DB') #Index Question-Sql Pair in Bulk From the Specified Example Path minds.index(bulk=True, path="your-qsn-sql-example.json") #Ask a Question to The Database And Visualize The Result response = minds.ask_db( question="YOUR_QUESTION", connection=connection, visualize=True ) #Extract And Display The Chart From The Response chart = response["chart"] chart.show() #Close The Connection to Your DB connection.close()
2.DB-GPT-Hub:利用LLMs实现Text-to-SQL微调
DB-GPT-Hub是一个利用LLMs实现Text-to-SQL解析的实验项目,主要包含数据集收集、数据预处理、模型选择与构建和微调权重等步骤,通过这一系列的处理可以在提高Text-to-SQL能力的同时降低模型训练成本,让更多的开发者参与到Text-to-SQL的准确度提升工作当中,最终实现基于数据库的自动问答能力,让用户可以通过自然语言描述完成复杂数据库的查询操作等工作。
2.1、数据集
本项目案例数据主要以Spider数据集为示例 :
其他数据集:
- WikiSQL: 一个大型的语义解析数据集,由80,654个自然语句表述和24,241张表格的sql标注构成。WikiSQL中每一个问句的查询范围仅限于同一张表,不包含排序、分组、子查询等复杂操作。
- CHASE: 一个跨领域多轮交互text2sql中文数据集,包含5459个多轮问题组成的列表,一共17940个<query, SQL>二元组,涉及280个不同领域的数据库。
- BIRD-SQL:数据集是一个英文的大规模跨领域文本到SQL基准测试,特别关注大型数据库内容。该数据集包含12,751对文本到SQL数据对和95个数据库,总大小为33.4GB,跨越37个职业领域。BIRD-SQL数据集通过探索三个额外的挑战,即处理大规模和混乱的数据库值、外部知识推理和优化SQL执行效率,缩小了文本到SQL研究与实际应用之间的差距。
- CoSQL:是一个用于构建跨域对话文本到sql系统的语料库。它是Spider和SParC任务的对话版本。CoSQL由30k+回合和10k+带注释的SQL查询组成,这些查询来自Wizard-of-Oz的3k个对话集合,查询了跨越138个领域的200个复杂数据库。每个对话都模拟了一个真实的DB查询场景,其中一个工作人员作为用户探索数据库,一个SQL专家使用SQL检索答案,澄清模棱两可的问题,或者以其他方式通知。
- 按照NSQL的处理模板,对数据集做简单处理,共得到约20w条训练数据
2.2、基座模型
DB-GPT-HUB目前已经支持的base模型有:
- [x] CodeLlama
- [x] Baichuan2
- [x] LLaMa/LLaMa2
- [x] Falcon
- [x] Qwen
- [x] XVERSE
- [x] ChatGLM2
- [x] ChatGLM3
- [x] internlm
- [x] Falcon
- [x] sqlcoder-7b(mistral)
- [x] sqlcoder2-15b(starcoder)
模型可以基于quantization_bit为4的量化微调(QLoRA)所需的最低硬件资源,可以参考如下:
| 模型参数 | GPU RAM | CPU RAM | DISK |
|---|---|---|---|
| 7b | 6GB | 3.6GB | 36.4GB |
| 13b | 13.4GB | 5.9GB | 60.2GB |
其中相关参数均设置的为最小,batch_size为1,max_length为512。根据经验,如果计算资源足够,为了效果更好,建议相关长度值设置为1024或者2048。
2.3 快速使用
- 环境安装
git clone https://github.com/eosphoros-ai/DB-GPT-Hub.git
cd DB-GPT-Hub
conda create -n dbgpt_hub python=3.10
conda activate dbgpt_hub
pip install poetry
poetry install2.3.1 数据预处理
DB-GPT-Hub使用的是信息匹配生成法进行数据准备,即结合表信息的 SQL + Repository 生成方式,这种方式结合了数据表信息,能够更好地理解数据表的结构和关系,适用于生成符合需求的 SQL 语句。
从spider数据集链接 下载spider数据集,默认将数据下载解压后,放在目录dbgpt_hub/data下面,即路径为dbgpt_hub/data/spider。
数据预处理部分,只需运行如下脚本即可:
##生成train数据 和dev(eval)数据,
poetry run sh dbgpt_hub/scripts/gen_train_eval_data.sh在dbgpt_hub/data/目录你会得到新生成的训练文件example_text2sql_train.json 和测试文件example_text2sql_dev.json ,数据量分别为8659和1034条。 对于后面微调时的数据使用在dbgpt_hub/data/dataset_info.json中将参数file_name值给为训练集的文件名,如example_text2sql_train.json。
生成的json中的数据形如:
{
"db_id": "department_management",
"instruction": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n\n",
"input": "###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:",
"output": "SELECT count(*) FROM head WHERE age > 56",
"history": []
}, 项目的数据处理代码中已经嵌套了chase 、cosql、sparc的数据处理,可以根据上面链接将数据集下载到data路径后,在dbgpt_hub/configs/config.py中将 SQL_DATA_INFO中对应的代码注释松开即可。
2.3.2 快速开始
首先,用如下命令安装dbgpt-hub:
pip install dbgpt-hub
然后,指定参数并用几行代码完成整个Text2SQL fine-tune流程:
from dbgpt_hub.data_process import preprocess_sft_data
from dbgpt_hub.train import start_sft
from dbgpt_hub.predict import start_predict
from dbgpt_hub.eval import start_evaluate
#配置训练和验证集路径和参数
data_folder = "dbgpt_hub/data"
data_info = [
{
"data_source": "spider",
"train_file": ["train_spider.json", "train_others.json"],
"dev_file": ["dev.json"],
"tables_file": "tables.json",
"db_id_name": "db_id",
"is_multiple_turn": False,
"train_output": "spider_train.json",
"dev_output": "spider_dev.json",
}
]
#配置fine-tune参数
train_args = {
"model_name_or_path": "codellama/CodeLlama-13b-Instruct-hf",
"do_train": True,
"dataset": "example_text2sql_train",
"max_source_length": 2048,
"max_target_length": 512,
"finetuning_type": "lora",
"lora_target": "q_proj,v_proj",
"template": "llama2",
"lora_rank": 64,
"lora_alpha": 32,
"output_dir": "dbgpt_hub/output/adapter/CodeLlama-13b-sql-lora",
"overwrite_cache": True,
"overwrite_output_dir": True,
"per_device_train_batch_size": 1,
"gradient_accumulation_steps": 16,
"lr_scheduler_type": "cosine_with_restarts",
"logging_steps": 50,
"save_steps": 2000,
"learning_rate": 2e-4,
"num_train_epochs": 8,
"plot_loss": True,
"bf16": True,
}
#配置预测参数
predict_args = {
"model_name_or_path": "codellama/CodeLlama-13b-Instruct-hf",
"template": "llama2",
"finetuning_type": "lora",
"checkpoint_dir": "dbgpt_hub/output/adapter/CodeLlama-13b-sql-lora",
"predict_file_path": "dbgpt_hub/data/eval_data/dev_sql.json",
"predict_out_dir": "dbgpt_hub/output/",
"predicted_out_filename": "pred_sql.sql",
}
#配置评估参数
evaluate_args = {
"input": "./dbgpt_hub/output/pred/pred_sql_dev_skeleton.sql",
"gold": "./dbgpt_hub/data/eval_data/gold.txt",
"gold_natsql": "./dbgpt_hub/data/eval_data/gold_natsql2sql.txt",
"db": "./dbgpt_hub/data/spider/database",
"table": "./dbgpt_hub/data/eval_data/tables.json",
"table_natsql": "./dbgpt_hub/data/eval_data/tables_for_natsql2sql.json",
"etype": "exec",
"plug_value": True,
"keep_distict": False,
"progress_bar_for_each_datapoint": False,
"natsql": False,
}
#执行整个Fine-tune流程
preprocess_sft_data(
data_folder = data_folder,
data_info = data_info
)
start_sft(train_args)
start_predict(predict_args)
start_evaluate(evaluate_args)2.3.3、模型微调
本项目微调不仅能支持QLoRA和LoRA法,还支持deepseed。 可以运行以下命令来微调模型,默认带着参数--quantization_bit 为QLoRA的微调方式,如果想要转换为lora的微调,只需在脚本中去掉quantization_bit参数即可。
默认QLoRA微调,运行命令:
poetry run sh dbgpt_hub/scripts/train_sft.sh微调后的模型权重会默认保存到adapter文件夹下面,即dbgpt_hub/output/adapter目录中。
如果使用多卡训练,想要用deepseed ,则将train_sft.sh中默认的内容进行更改,
调整为:
CUDA_VISIBLE_DEVICES=0 python dbgpt_hub/train/sft_train.py \
--quantization_bit 4 \
...更改为:
deepspeed --num_gpus 2 dbgpt_hub/train/sft_train.py \
--deepspeed dbgpt_hub/configs/ds_config.json \
--quantization_bit 4 \
...如果需要指定对应的显卡id而不是默认的前两个如3,4,可以如下
deepspeed --include localhost:3,4 dbgpt_hub/train/sft_train.py \
--deepspeed dbgpt_hub/configs/ds_config.json \
--quantization_bit 4 \
...其他省略(...)的部分均保持一致即可。 如果想要更改默认的deepseed配置,进入 dbgpt_hub/configs 目录,在ds_config.json 更改即可,默认为stage2的策略。
脚本中微调时不同模型对应的关键参数lora_target 和 template,如下表:
| 模型名 | lora_target | template |
|---|---|---|
| LLaMA-2 | q_proj,v_proj | llama2 |
| CodeLlama-2 | q_proj,v_proj | llama2 |
| Baichuan2 | W_pack | baichuan2 |
| Qwen | c_attn | chatml |
| sqlcoder-7b | q_proj,v_proj | mistral |
| sqlcoder2-15b | c_attn | default |
| InternLM | q_proj,v_proj | intern |
| XVERSE | q_proj,v_proj | xverse |
| ChatGLM2 | query_key_value | chatglm2 |
| LLaMA | q_proj,v_proj | - |
| BLOOM | query_key_value | - |
| BLOOMZ | query_key_value | - |
| Baichuan | W_pack | baichuan |
| Falcon | query_key_value | - |
train_sft.sh中其他关键参数含义:
quantization_bit:是否量化,取值为[4或者8]
model_name_or_path: LLM模型的路径
dataset: 取值为训练数据集的配置名字,对应在dbgpt_hub/data/dataset_info.json 中外层key值,如example_text2sql。
max_source_length: 输入模型的文本长度,如果计算资源支持,可以尽能设大,如1024或者2048。
max_target_length: 输出模型的sql内容长度,设置为512一般足够。
output_dir : SFT微调时Peft模块输出的路径,默认设置在dbgpt_hub/output/adapter/路径下 。
per_device_train_batch_size : batch的大小,如果计算资源支持,可以设置为更大,默认为1。
gradient_accumulation_steps : 梯度更新的累计steps值
save_steps : 模型保存的ckpt的steps大小值,默认可以设置为100。
num_train_epochs : 训练数据的epoch数
2.3.4、模型预测
项目目录下./dbgpt_hub/下的output/pred/,此文件路径为关于模型预测结果默认输出的位置(如果没有则建上)。
预测运行命令:
poetry run sh ./dbgpt_hub/scripts/predict_sft.sh脚本中默认带着参数--quantization_bit 为QLoRA的预测,去掉即为LoRA的预测方式。
其中参数predicted_input_filename 为要预测的数据集文件, --predicted_out_filename 的值为模型预测的结果文件名。默认结果保存在dbgpt_hub/output/pred目录。
2.3.5、模型权重
可以从Huggingface查看社区上传的第二版Peft模块权重huggingface地址 (202310) ,在spider评估集上的执行准确率达到0.789。
模型和微调权重合并
如果你需要将训练的基础模型和微调的Peft模块的权重合并,导出一个完整的模型。则运行如下模型导出脚本:poetry run sh ./dbgpt_hub/scripts/export_merge.sh注意将脚本中的相关参数路径值替换为你项目所对应的路径。
2.3.6、模型评估
对于模型在数据集上的效果评估,默认为在spider数据集上。
运行以下命令来:
poetry run python dbgpt_hub/eval/evaluation.py --plug_value --input Your_model_pred_file你可以在这里找到最新的评估和实验结果。
注意: 默认的代码中指向的数据库为从Spider官方网站下载的大小为95M的database,如果你需要使用基于Spider的test-suite中的数据库(大小1.27G),请先下载链接中的数据库到自定义目录,并在上述评估命令中增加参数和值,形如--db Your_download_db_path。
2.4 小结
整个过程会分为三个阶段:
阶段一:
- 搭建基本框架,基于数个大模型打通从数据处理、模型SFT训练、预测输出和评估的整个流程
现在支持 - [x] CodeLlama
- [x] Baichuan2
- [x] LLaMa/LLaMa2
- [x] Falcon
- [x] Qwen
- [x] XVERSE
- [x] ChatGLM2
- [x] ChatGLM3
- [x] internlm
- [x] sqlcoder-7b(mistral)
- [x] sqlcoder2-15b(starcoder)
- 搭建基本框架,基于数个大模型打通从数据处理、模型SFT训练、预测输出和评估的整个流程
阶段二:
- [x] 优化模型效果,支持更多不同模型进行不同方式的微调。
- [x] 对
prompt优化 - [x] 放出评估效果,和优化后的还不错的模型,并且给出复现教程(见微信公众号EosphorosAI)
阶段三:
- [ ] 推理速度优化提升
- [ ] 业务场景和中文效果针对性优化提升
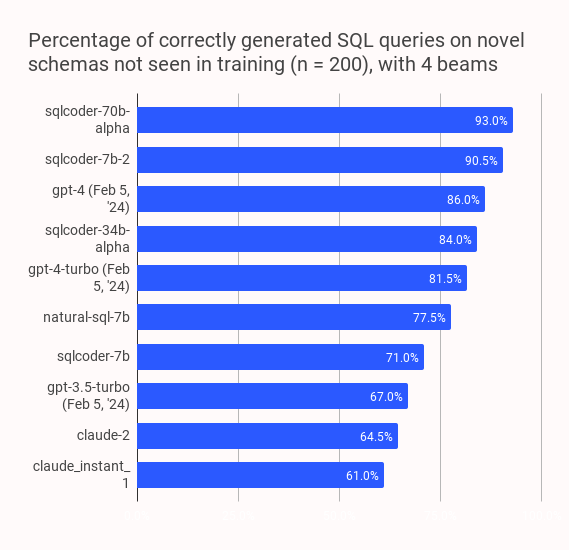
3.sqlcoder
官方链接:https://github.com/defog-ai/s...
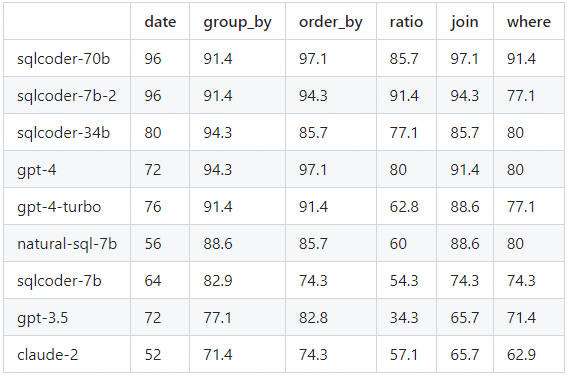
Defog组织提出的先进的Text-to-SQL的大模型,表现亮眼,效果优于GPT3.5、wizardcoder和starcoder等,仅次于GPT4。
将每个生成的问题分为6类。该表显示了每个模型正确回答问题的百分比,并按类别进行了细分。
4.modal_finetune_sql
项目基于LLaMa 2 7b模型进行Text-to-SQL微调,有完整的训练、微调、评估流程。
链接:https://github.com/run-llama/...
5.LLaMA-Efficient-Tuning
这是一个易于使用的LLM微调框架,支持LLaMA-2、BLOOM、Falcon、Baichuan、Qwen、ChatGLM2等。
链接:https://github.com/hiyouga/LL...
- 多种模型:LLaMA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
- 集成方法:(增量)预训练、指令监督微调、奖励模型训练、PPO 训练、DPO 训练和 ORPO 训练。
- 多种精度:32 比特全参数微调、16 比特冻结微调、16 比特 LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8 的 2/4/8 比特 QLoRA 微调。
- 先进算法:GaLore、DoRA、LongLoRA、LLaMA Pro、LoRA+、LoftQ 和 Agent 微调。
- 实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
- 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
- 极速推理:基于 vLLM 的 OpenAI 风格 API、浏览器界面和命令行接口。
- 训练方法
| 方法 | 全参数训练 | 部分参数训练 | LoRA | QLoRA |
|---|---|---|---|---|
| 预训练 | ✔ | ✔ | ✔ | ✔ |
| 指令监督微调 | ✔ | ✔ | ✔ | ✔ |
| 奖励模型训练 | ✔ | ✔ | ✔ | ✔ |
| PPO 训练 | ✔ | ✔ | ✔ | ✔ |
| DPO 训练 | ✔ | ✔ | ✔ | ✔ |
| ORPO 训练 | ✔ | ✔ | ✔ | ✔ |
- 可视化使用教学
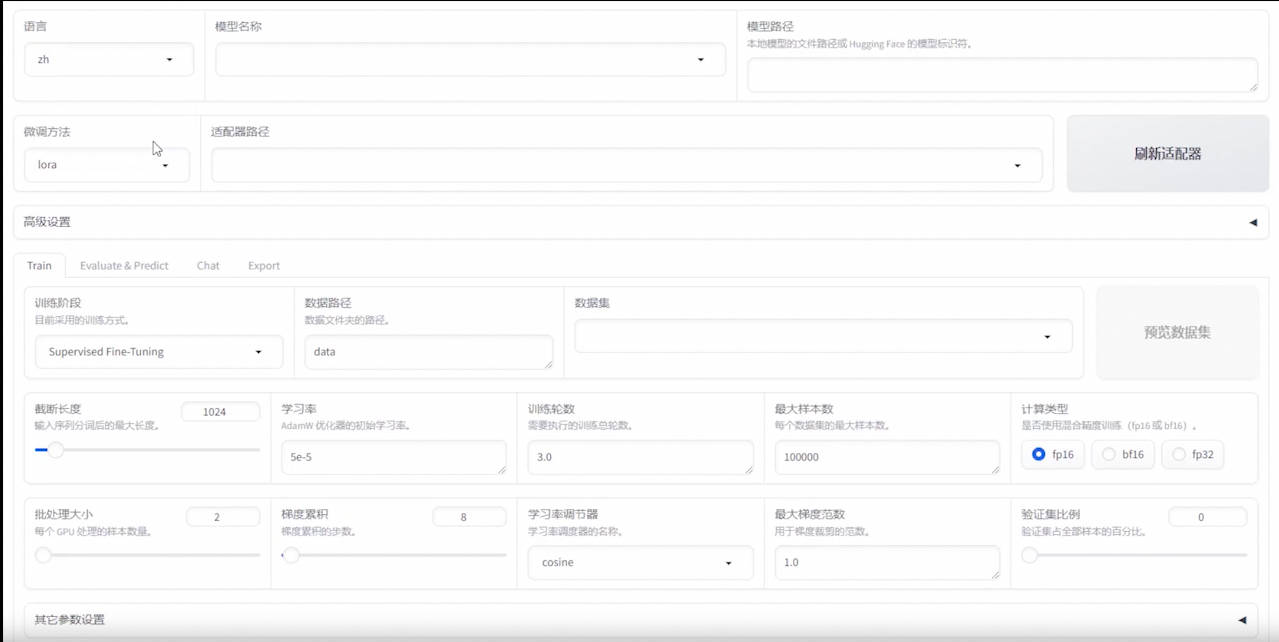

https://github.com/hiyouga/LL...
- 参考链接
- Awesome Text2SQL:https://github.com/eosphoros-...
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

