
本文将整理4月发表的计算机视觉的重要论文,重点介绍了计算机视觉领域的最新研究和进展,包括图像识别、视觉模型优化、生成对抗网络(gan)、图像分割、视频分析等各个子领域

扩散模型
1、Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization
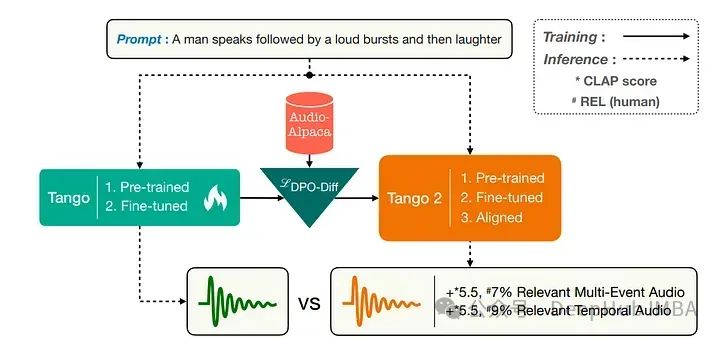
在音乐和电影行业中,从文本提示生成音频是一个重要的研究方向。最近许多基于扩散模型的文本到音频方法专注于在大量的提示音频对的数据集上进行训练。
这些模型并没有显式关注输出音频中与输入提示相关的概念或事件及其时间顺序。而这篇论文的假设聚焦于音频生成中如何在数据有限的情况下提升音频生成性能。
使用现有的文本到音频模型Tango,合成创建一个偏好数据集,其中每个提示都有一个好的音频输出和一些不合适音频输出。理论上,不合适输出中有一些来自提示的概念缺失或顺序错误。
所以使用diffusion-DPO(直接偏好优化)损失对公开的Tango文本到音频模型进行微调,在这个的偏好数据集上训练后,模型能够在自动和手动评估指标上比Tango和AudioLDM2改善音频输出。
https://arxiv.org/abs/2404.09956
2、Ctrl-Adapter: An Efficient and Versatile Framework for Adapting Diverse Controls to Any Diffusion Model
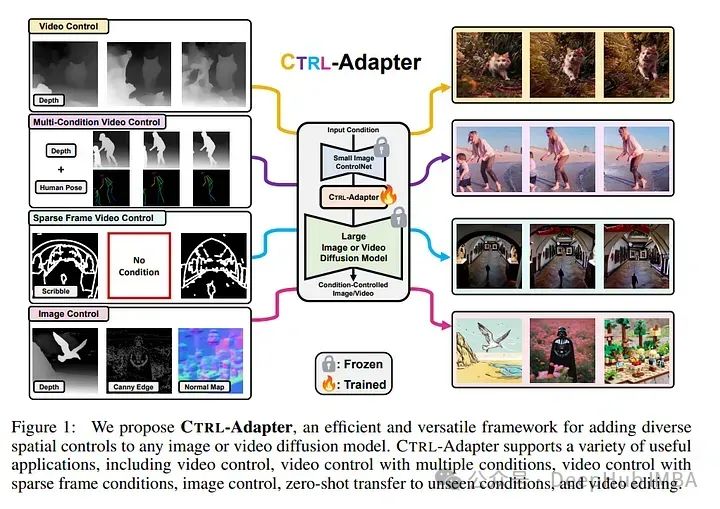
ControlNets广泛用于在图像生成中添加空间控制,如深度图、Canny边缘和人体姿势。但是在利用预训练的图像控制网进行受控视频生成时则有一些挑战。
首先,预训练的ControlNet由于特征空间不匹配,不能直接插入新的基础模型中,为新基础模型训练ControlNet的成本非常高。
其次,不同帧的ControlNet特征可能无法有效处理时间上的连贯性。
为应对这些挑战,论文引入了Ctrl-Adapter,通过适配预训练的ControlNets(并改进视频的时间对齐),为任何图像/视频扩散模型添加多样的控制。
Ctrl-Adapter提供多样的功能,包括图像控制、视频控制、稀疏帧视频控制、多条件控制、与不同基础模型的兼容性、适应未见控制条件和视频编辑。
在Ctrl-Adapter中,训练适配层将预训练的ControlNet特征融合到不同的图像/视频扩散模型中,同时保持ControlNets和扩散模型的参数不变。Ctrl-Adapter由时间和空间模块组成,因此能有效处理视频的时间连贯性。
论文还提出了潜在跳过和逆时间步采样技术,用于稳定的适应和稀疏控制。此外Ctrl-Adapter通过简单地取ControlNet输出的(加权)平均值,实现了多条件控制。
Ctrl-Adapter可以搭配多样的图像/视频扩散后端(SDXL, Hotshot-XL, I2VGen-XL, 和 SVD),在图像控制方面与ControlNet匹敌,在视频控制方面超越所有基准(在DAVIS 2017数据集上达到了最高的准确率),且计算成本显著降低(少于10个GPU小时)。
https://arxiv.org/abs/2404.09967
视觉语言模型(VLMs)
3、Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies
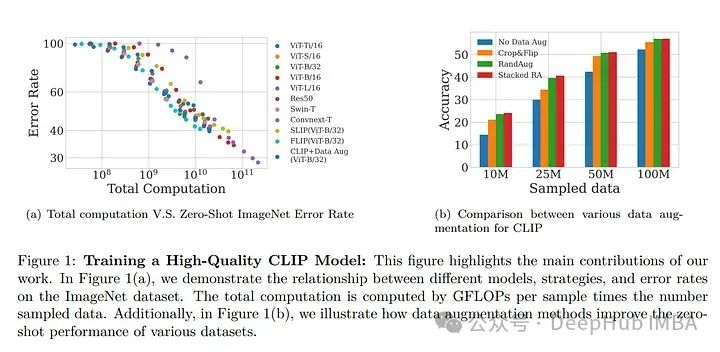
论文研究了在计算资源有限的条件下,对比语言图像预训练(CLIP)模型的性能表现。从数据、架构和训练策略三个维度探讨了CLIP模型。
关于数据,展示了高质量训练数据的重要性,并证明了小规模的高质量数据集可以胜过大规模的低质量数据集。
还研究了模型性能随不同数据集大小的变化情况,发现较小的ViT模型更适合小数据集,而较大的模型在固定计算资源下对大数据集的表现更佳。
此外,论文还研究了何时选择基于CNN的架构或基于ViT的架构进行CLIP训练。比较了四种CLIP训练策略——SLIP、FLIP、CLIP和CLIP+数据增强——并显示训练策略的选择取决于可用的计算资源。
分析揭示,CLIP+数据增强可以仅使用一半的训练数据达到与CLIP相当的性能。这项工作提供了如何有效训练和部署CLIP模型的实用见解,使其在各种应用中更易于获取和负担得起。
https://arxiv.org/abs/2404.08197
4、On the Robustness of Language Guidance for Low-Level Vision Tasks: Findings from Depth Estimation
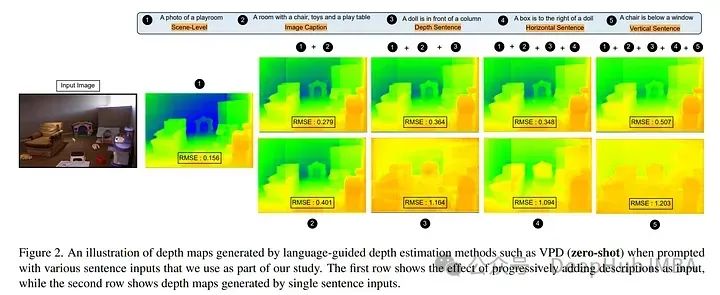
最近在单目深度估计领域的进展时通过引入自然语言作为额外的指导而取得。尽管取得了令人印象深刻的结果,但语言先验在泛化能力和鲁棒性方面的影响尚未被探索。
所以论文通过量化这种先验的影响并介绍了一种评估其在不同环境中有效性的方法来填补这一空白。作者生成了描述物体中心的三维空间关系的“低级”句子,将它们作为额外的语言先验,并评估它们对深度估计的下游影响。
论文主要发现是,当前的语言引导的深度估计器只有在使用场景级描述时才能表现最佳,而使用低级描述时的表现却出人意料地更差。虽然利用了额外的数据,但这些方法对有针对性的对抗攻击不具备鲁棒性,并且随着分布偏移的增加表现出下降。
最后为了给后续的研究提供基础,论文确定了失败的点并提供了洞见以更好地理解这些缺点。
https://arxiv.org/abs/2404.08540
图像生成与编辑
5、Probing the 3D Awareness of Visual Foundation Models
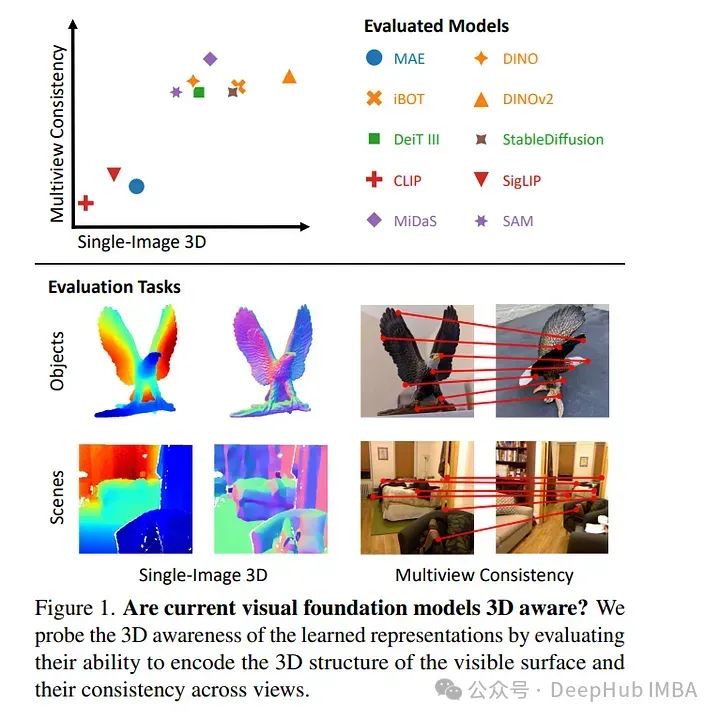
大规模预训练的进展已经产生了具有强大能力的视觉基础模型。最近的模型不仅可以推广到任意图像的训练任务,而且它们的中间表示对于其他视觉任务(如检测和分割)也很有用。
考虑到这些模型可以在2D中对物体进行分类、描绘和定位,论文尝试它们是否也代表3D结构,分析了视觉基础模型的三维意识。
论文假设3D感知意味着表征(1)对场景的3D结构进行编码,(2)跨视图一致地表示真值。使用任务特定探针和零样本推理程序对冻结特征进行了一系列实验,揭示了当前模型的几个局限性。
https://arxiv.org/abs/2404.08636
6、HQ-Edit: A High-Quality Dataset for Instruction-based Image Editing

论文引入了一个高质量的基于指令的图像编辑数据集HQ-Edit,其编辑量约为20万次。与之前依赖属性指导或人工反馈构建数据集的方法不同,设计了一个利用先进的基础模型(GPT-4V和DALL-E 3)的可扩展数据收集管道。
为了确保其高质量,首先在线收集各种示例,然后进行扩展,用于创建具有输入和输出图像的高质量双连画,并附有详细的文本提示,然后通过后处理确保精确对齐。
论文还提出了两个评估指标,对齐和一致性,定量评估使用GPT-4V图像编辑对的质量。HQ-Edit的高分辨率图像,丰富的细节,并伴随着全面的编辑提示,大大增强了现有的图像编辑模型的能力。
经过HQ-Edit微调的InstructPix2Pix可以获得最先进的图像编辑性能,甚至超过那些经过人工注释数据微调的模型。
https://arxiv.org/abs/2404.09990
7、EdgeFusion: On-Device Text-to-Image Generation

稳定扩散(SD)算法在文本到图像生成过程中的大量计算量对其实际应用构成了很大的障碍。为了应对这一挑战,最近的研究集中在减少采样步骤的方法上,比如潜在一致性模型(Latent Consistency Model, LCM),以及架构优化,包括剪枝和知识蒸馏。
与现有的方法不同,论文从紧凑的SD变体BK-SDM开始。观察到直接将LCM应用于BK-SDM与常用的抓取数据集产生不满意的结果。
然后开发了两种策略:(1)利用来其他生成模型的高质量图像-文本对;(2)设计为LCM量身定制的高级蒸馏过程。通过对量化、分析和设备上部署的深入探索,只需两步即可快速生成逼真的文本对齐图像,在资源有限的边缘设备上延迟不到一秒。
https://arxiv.org/abs/2404.11925
8、Dynamic Typography: Bringing Words to Life
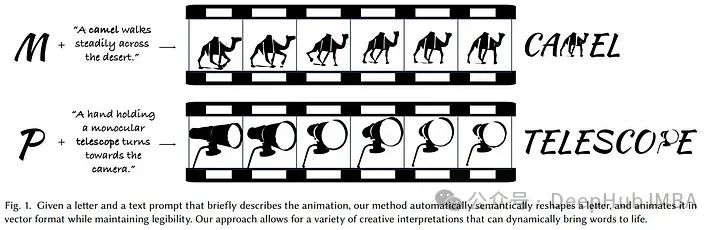
文本动画作为一种表达媒介,通过给文字注入运动来唤起情感,强调意义,构建引人入胜的叙事。
制作具有语义意识的动画提出了重大挑战,要求图形设计和动画方面的专业知识。论文则提出了一个自动文本动画方案,称为“Dynamic Typography”,它结合了两个具有挑战性的任务。它通过变形字母来传达语义,并根据用户提示为字母注入充满活力的动作。
利用矢量图形表示和基于端到端优化的框架。采用神经位移场将字母转换为基本形状,并应用逐帧运动,鼓励与预期文本概念的一致性。在整个动画过程中,采用形状保持技术和感知损失正则化来保持易读性和结构完整性。
论文展示了这种方法在各种文本到视频模型中的通用性,并强调了端到端方法优于基线。通过定量和定性的评估,证明了论文的框架在生成连贯的文本动画方面的有效性,这些动画忠实地解释了用户提示,同时保持了可读性。
https://arxiv.org/abs/2404.11614
视频理解与生成
9、Video2Game: Real-time, Interactive, Realistic and Browser-Compatible Environment from a Single Video

创建高质量的交互式虚拟环境,例如游戏和模拟器,通常涉及复杂且昂贵的手动建模过程。
论文提出了一种新颖的方法Video2Game,可以自动将现实世界场景的视频转换为现实的交互式游戏环境。系统的核心是三个核心组件:(i)神经辐射场(NeRF)模块,有效捕获场景的几何形状和视觉外观;(ii)从NeRF中提取知识以加快渲染的网格模块;以及(iii)物理模块,对象之间的相互作用和物理动力学进行建模。
通过精心设计的管道,可以构建一个可交互和可操作的真实世界的数字复制品。在室内和大型室外场景中对系统进行基准测试。不仅可以实时制作高度逼真的渲染图,还可以在上面构建互动游戏。
https://arxiv.org/abs/2404.09833
10、AniClipart: Clipart Animation with Text-to-Video Priors
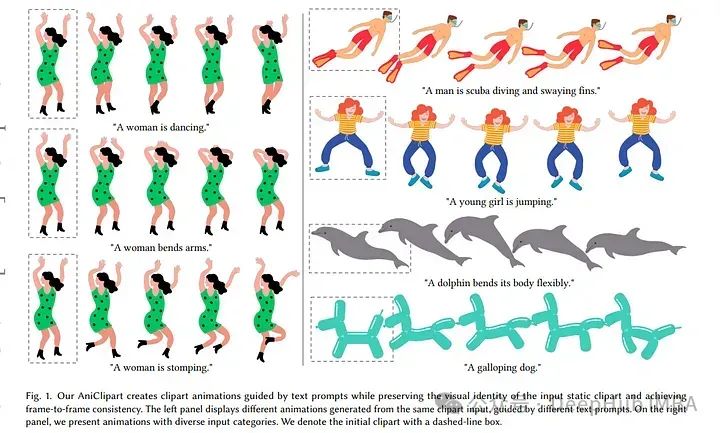
剪贴画是一种预先制作好的图形艺术形式,它提供了一种方便有效的方式来说明视觉内容。将静态剪贴画图像转换为运动序列的传统工作流程既费力又耗时,并且涉及许多复杂的步骤。
最近在文本到视频生成方面取得的进展在解决这一问题方面具有很大的潜力。但是直接应用文本到视频生成模型往往难以保持剪贴画图像的视觉识别或生成卡通风格的运动,导致动画效果不理想。
论文介绍了AniClipart,一个将静态剪贴画图像转换为高质量运动序列的系统,该系统由文本到视频先验引导。为了生成卡通风格的平滑运动,我们首先在剪贴画图像的关键点上定义Bezier 曲线,作为运动正则化的一种形式。
然后通过优化视频分数蒸馏采样(VSDS)损失,将关键点的运动轨迹与提供的文本提示对齐,该损失在预训练的文本到视频扩散模型中编码了足够的自然运动知识。采用可微的As-Rigid-As-Possible形状变形算法,可以在保持变形刚度的情况下实现端到端优化。
实验结果表明,所提出的AniClipart在文本-视频对齐、视觉身份保持和运动一致性方面始终优于现有的图像-视频生成模型。论文还展示了AniClipart的多功能性,通过调整它来生成更广泛的动画格式,例如分层动画,它允许拓扑更改。
https://arxiv.org/abs/2404.12347
https://avoid.overfit.cn/post/6ea12c7caca64be2a03317a8bce92bed

