
Command-R+, Mixtral-8x22b和Llama 3 70b都在最近的几周内发布了,这些模型是巨大的。它们都有超过700亿个参数:
Command-R+: 104B参数
Mixtral-8x22b:具有141B参数的混合专家(MoE)模型
Llama 370b: 70.6B参数
你能在电脑上微调和运行这些模型吗?
在本文中,我将介绍如何计算这些模型用于推理和微调的最小内存。这种方法适用于任何的llm,并且精确的计算内存总消耗。

推理所需的内存
这三个模型都以16位权重发布:Command-R+为float16, Mixtral和Llama 370b为bfloat16。也就是说一个参数消耗16位或2字节的内存。
10亿个参数则将占用20亿个字节,或者说10亿个字节等于1GB,那么1B个参数占用2GB的内存。100B参数就需要占用200GB内存。这是一个近似值,因为1 KB不等于1,000字节,而是1,024字节。我们通过这种简单的方法可以大概评估内存的占用,后面我们还会有详细的计算过程。
要知道一个模型有多少个参数而不需要下载,可以查看模型卡:
如果在GPU上做快速推理,需要将模型完全加载到GPU RAM上。
对于Command-R+: 193.72 GB的GPU RAM
对于Mixtral-8x22B: 262.63 GB的GPU RAM
对于Llama 370b: 131.5 GB的GPU RAM
或者说你将需要2x80 GB的GPU,例如两个h100。
激活的内存消耗
一旦模型被加载,我们需要更多的内存来存储模型的激活,即在推理过程中创建的张量。这些张量从一层传递到下一层。它们在内存中的大小并不容易估计。为了估计这些激活的内存消耗,我使用了《Reducing Activation Recomputation in Large Transformer Models》提出的方法。
我们需要知道以下内容来估计内存消耗:
s:最大序列长度(输入中的令牌数量)
b:批大小
h:模型的隐藏维度
a:注意头的数量标准transformer 层由自注意力块和MLP块组成,每个块由两个layer-norms连接。每个组件的内存消耗估计如下。
1、注意力块
注意块由自注意力机制、线性投射和dropout 组成。内存要求包括:
线性投影保留其输入激活,其大小为2sbh,而dropout 需要占用sbh的掩码。
线性投影和自注意力输入激活,各需要2sbh。
查询(Q)和键(K)矩阵需要4sbh。
Softmax和它的dropout分别需要2as²b和as²b。
值(V)上应用的注意存储(V)加起来等于2as²b + 2sbh。所以注意块所需的总内存为11sbh + 5as²b。
这里的sbh等于 s b h,我们下面也会这样简写。
2、MLP块
MLP块包括两个线性层和一个dropout:
线性层存储花费2sbh和8sbh的输入,GeLU非线性也需要8sbh。我们不需要为推理存储GeLU的激活,但我仍然会对它们进行计数,以防某些推理的框架存储这些激活。Dropout存储的掩码大小为sbh。
所以MLP块需要19sbh的空间。
3、layer-norms
每个LN存储它的输入需要2sbh,两层就为4sbh。
4、对于整个层
总内存需求总计为11sbh + 5as²b(来自注意力块)+ 19sbh(来自MLP块)+ 4sbh(来自LN)。
每层激活内存消耗= 34 sbh + 5as²b
如果我们使用16位数据类型,那么需要将这个数字乘以2,因为每个激活参数将需要2字节。
5、总计
这个等式大致近似于实际内存消耗。大多数推理框架都经过优化,通过在张量无用时立即删除它们,所以一般情况下会比这个数值少。但是在推理期间也会创建各种消耗内存的缓冲区。但是通过实验,我发现我们计算的这个数值基本上近似于Hugging Face的Transformers框架。而对于vLLM和TGI等其他优化得更好的框架,内存消耗则会减少。
如果使用FlashAttention、Alibi或RoPE等高级技术,处理长序列的内存消耗也将大大减少。
6、估算用于推理的Command-R+、Mixtral-8x22B和Llama 370b的内存消耗
在模型的参数和激活都是16位的标准场景下,我们还需要设置解码超参数。
S = 512(序列长度),B = 8(批量大小)
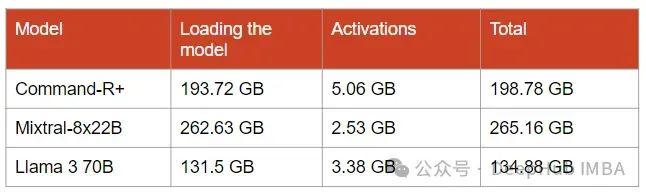
与内存中模型的大小相比,激活的大小可以忽略不计。但是它们的大小会随着批大小和序列长度的增加而迅速增加。
减少推理的内存消耗
大部分用于推理的内存消耗来自模型的参数。最近的量化算法可以显著减少这种内存消耗。他们通过减少大多数参数的位宽来压缩模型,同时尽量保持模型的准确性。
8位量化几乎是无损的,而4位量化只会略微降低性能。4位量化将模型的内存消耗除以4,因为大多数参数都是4位,即0.5字节而不是2字节。我推荐使用AWQ进行4位量化,它运行简单,生成快速模型。
对于超过100B个参数的非常大的模型,精度较低的量化,例如2.5位或3位,仍然可以得到准确的结果。例如,AQLM对Mixtral-8x7B的2位量化表现出良好的性能。但是AQLM的问题在于量化模型的成本非常高。对于非常大的模型,可能需要几个星期的时间。
另一种选择是将模型移动到另一个存储设备,例如,CPU RAM。但是他的缺点和明显,太慢了,特别是在批处理解码时。针对CPU推理进行优化的框架有助于保持推理的合理速度。例如,Neural Speed是使用量化模型在CPU上进行推理的最快框架之一。
如果使用CPU,那么仍然需要大量的CPU RAM来加载模型和存储激活,计算的方法是相同的。
微调所需的内存
对于微调llm,估计内存消耗稍微复杂一些。除了存储模型权重和激活之外,对于所有层,我们还需要存储优化器状态。
优化器状态的内存消耗
AdamW优化器是最流行的微调llm,它为模型的每个参数创建并存储2个新参数。如果我们有一个100B的模型,优化器将创建200B的新参数!为了更好的训练稳定性,优化器的参数为float32,即每个参数占用4字节的内存。
这就是微调比推理消耗更多内存的主要原因。
例如,对于Mixtral-8x22B,优化器创建2*141B = 282B float32参数。它消耗了1053.53 GB的内存,我们必须加上模型本身占用的内存,即262.63 GB。所以总共需要1315.63 GB的GPU内存。这大约是17个80gb的A100 !
并且这还不足以对模型进行微调。我们还需要内存来存储激活。
计算梯度所需的内存
与推理相比,我们只需要在传递给下一层之前存储单个层的激活,微调需要存储前向传播过程中创建的所有激活。这对于计算梯度是必要的,然后用于反向传播误差并更新模型的权重。
为了估计计算梯度所需的内存,我们可以使用用于推理的相同公式,然后将结果乘以层数。
如果L是层数,那么计算梯度所消耗的内存为
L(34sbh + 5as²b)估算Llama 3 70b、Mixtral-8x22B和Command R+微调的内存消耗
我们需要估计模型的大小,并添加所有层的激活大小和优化器状态的大小。
我设置了以下超参数进行微调:
S = 512(序列长度)
B = 8(批量大小)
对于优化器状态,我假设它们是float32。
所以得到
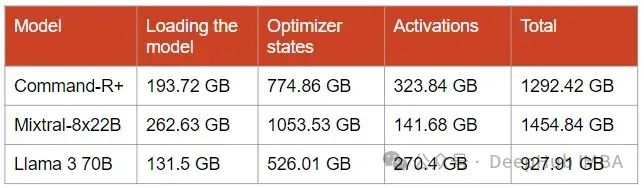
这是最坏情况下的内存消耗,也就是说没有使用任何优化来减少内存消耗。幸运的是,我们可以应用许多优化来减少内存需求。
减少微调内存消耗
由于优化器状态消耗大量内存,因此已经进行了大量的研究来减少它们的内存占用,例如:
LoRA:冻结整个模型,并添加一个具有数百万个参数的可训练适配器。使用LoRA,我们只存储适配器参数的优化器状态。
QLoRA: LoRA,但模型量化为4位或更低精度。
AdaFactor和AdamW-8bit:更高效的内存优化器,提供接近AdamW的性能。但AdaFactor在训练期间可能不稳定。
GaLore:将梯度投影到低秩子空间中,这可以将优化器状态的大小减少80%。
内存的另一个重要部分被激活所消耗。为了减少它通常采用梯度检查点。当需要计算梯度时,它会重新计算一些激活。它减少了内存消耗但也减慢了微调速度。
最后,还有一些框架,如Unsloth,在使用LoRA和QLoRA进行微调方面进行了极大的优化。
总结
在本文中,我们介绍了如何估计transformer 模型的内存消耗。这个方法不适用于transformer以外的其他体系结构的模型。例如,曼巴和RWKV的激活记忆消耗明显较低,因为它们不使用注意力机制。
https://avoid.overfit.cn/post/0046a7ef3a47406e9ed98d4ce947a14d

