
该论文探讨了Mamba架构(包含状态空间模型SSM)是否有必要用于视觉任务,如图像分类、目标检测和语义分割。通过实验证实了了Mamba在视觉识别任务中的效果,认为其不如传统的卷积和注意力模型。

论文理论化认为Mamba更适合具有长序列和自回归特性的任务,而这些特性大多数视觉任务不具备。并进行了一下的实验
- 构建了一系列名为MambaOut的模型,使用了不带SSM的门控CNN块。
- 将MambaOut的性能与视觉Mamba模型在ImageNet上的图像分类和COCO上的目标检测和分割任务进行比较。
实验结论如下:
对于图像分类任务,SSM是没有必要的,因为此任务不符合长序列或自回归特性。实验证据表明,MambaOut在图像分类上超越了视觉Mamba模型。
对于检测和分割任务,SSM可能有潜在的好处,因为这些任务符合长序列特性,尽管它们不是自回归的。MambaOut在这些任务中的表现不如最先进的视觉Mamba模型,支持了SSM在这些任务中仍有价值的假设。
我总结了论文主要阐述的三个问题:
1、论文认为SSM更适合长序列和自回归特性的任务
长序列特性:
- RNN-like机制:SSM具备RNN-like(类RNN)机制,即通过固定大小的隐状态来存储历史信息。隐状态在每个时间步更新,但其大小保持不变,因此计算复杂度与序列长度无关。这使得SSM在处理长序列时非常高效。
- 记忆合并效率:由于隐状态的固定大小,SSM能够在合并历史信息和当前输入时保持计算复杂度不变,不会随着序列长度的增加而显著增长。这与注意力机制不同,后者存储所有过去的键和值,并随着序列长度的增加,记忆合并的复杂度呈二次增长。
自回归特性:
- 因果模式:SSM的递归特性使其只能访问前一个和当前时间步的信息,这种特性被称为因果模式(causal mode)。在因果模式下,每个时间步的输出仅依赖于当前及之前的输入。这非常适合自回归生成任务,其中每个令牌只能依赖于之前的令牌。
- 因果约束的必要性:在自回归任务中,模型需要根据当前和之前的信息逐步生成输出,SSM的因果模式能够很好地满足这一需求。而对于理解任务(如视觉任务),模型可以一次性看到整个输入图像,不需要因果约束,因果模式反而会导致性能下降。
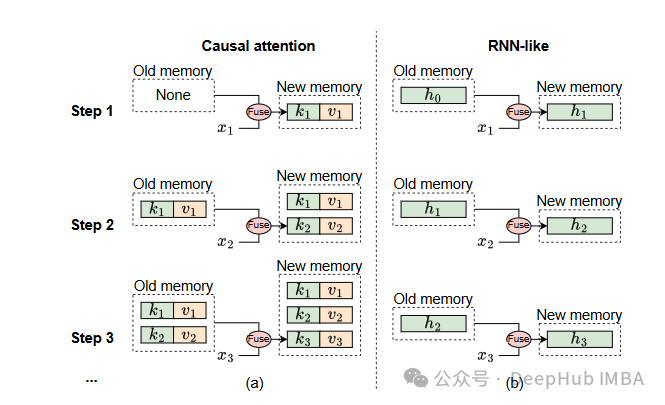
论文认为SSM适合长序列和自回归特性的任务,因为其高效的记忆合并机制和因果模式能够在这些任务中发挥优势。而视觉任务大多不具备这两个特性,因此SSM在这些任务中表现不佳。
2、MambaOut在图像分类上的性能以及研究意义
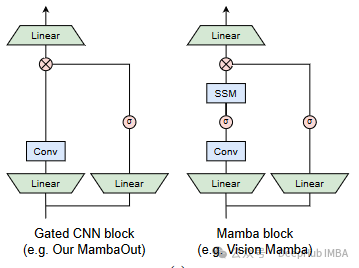
实验结果表明,MambaOut在ImageNet图像分类任务中表现优异,超越了包含SSM的视觉Mamba模型。例如,MambaOut模型在不同大小的参数配置下均表现出色,尤其是在ImageNet上的Top-1准确率显著提高。
MambaOut-Small模型的Top-1准确率达到了84.1%,比LocalVMamba-S高出0.4%,同时仅需要79%的MACs(乘法累加操作)。
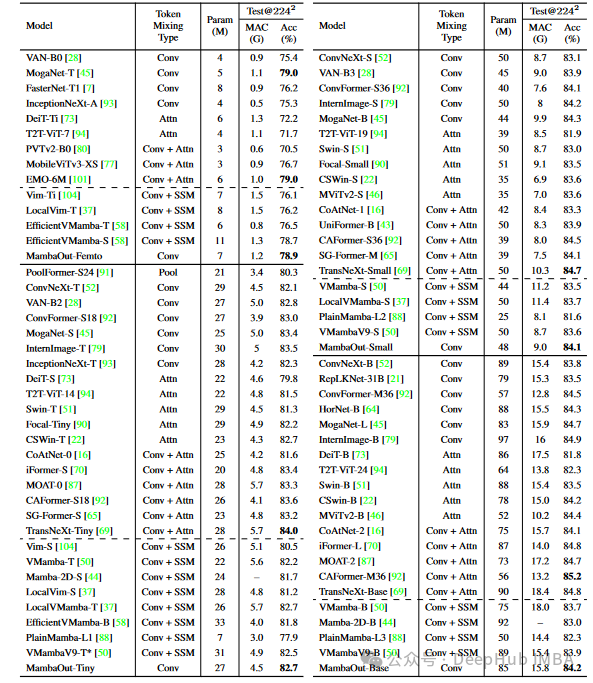
在多种模型规模下,MambaOut模型都能超越视觉Mamba模型,证明了其在图像分类任务中的有效性。
- 实验证明SSM在图像分类任务中是没有必要的。图像分类任务不符合长序列或自回归特性,因此去掉SSM的MambaOut模型能够在性能上超越包含SSM的视觉Mamba模型。
- MambaOut采用了更简单的架构(去除了SSM),根据奥卡姆剃刀原则,简单的模型如果能提供相同或更好的性能,则更为优越。这意味着未来的视觉任务研究可以优先考虑不包含SSM的简化模型。
- 去除SSM后的MambaOut模型在计算复杂度和效率上都有提升。固定大小的隐状态减少了内存需求和计算开销,使得模型在实际应用中更加高效和可扩展。
- MambaOut因为其简洁且高效的设计,可以作为未来视觉任务研究中的基线模型,帮助研究人员在更简化的模型架构上进行优化和改进。
总结来说,MambaOut在图像分类任务中的优异表现不仅验证了SSM在此类任务中的不必要性,还提供了一个高效、简洁的模型架构,为未来的研究工作奠定了基础。
3、Mamba在检测和分割任务中的潜力
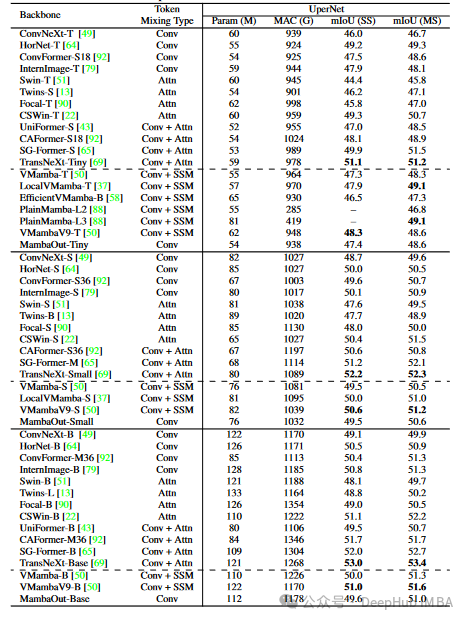
长序列特性:
- 检测和分割任务通常处理更大尺寸的图像(例如COCO和ADE20K数据集),这些任务涉及的序列长度较长,符合Mamba模型处理长序列的优势。
- Mamba的高效内存合并机制可以在长序列任务中保持计算复杂度恒定,从而提高处理效率。
局部信息整合:
- 尽管视觉任务不是自回归的,但检测和分割任务可以从Mamba的因果模式中受益,通过局部信息的逐步整合,有助于更细致的目标识别和区域分割。
- Mamba的选择性状态空间模型(SSM)能够在处理长序列时有效地保持和传递局部信息,有助于提升模型的表现。
4、可以进行的额外研究来验证这一点
改进现有的Mamba模型:
- 局部Mamba:增强Mamba模型的局部感受野,例如LocalMamba,通过引入窗口选择性扫描来提升局部信息处理能力。
- 混合模型:将Mamba与其他先进的模型架构(如卷积和注意力机制)相结合,构建混合模型,以便充分利用各自的优势。
更大规模的数据集实验:
- 在更多且更大规模的数据集上测试Mamba模型,如Cityscapes、Pascal VOC等,验证其在不同数据分布和任务复杂度下的表现。进行跨数据集的迁移学习实验,评估Mamba在不同视觉任务中的通用性和适应性。
优化模型训练策略:
- 探索更有效的训练策略,例如多任务学习,将图像分类、目标检测和语义分割结合在一个统一的训练框架中,以充分挖掘Mamba模型的潜力。引入自监督学习和迁移学习技术,通过在无标签数据上预训练Mamba模型,提升其在有限标签数据上的表现。
更细致的模型分析:
- 通过可视化工具和解释性技术,深入分析Mamba模型在检测和分割任务中的决策过程,理解其内在机制和优势。对比不同任务和数据集下Mamba模型的性能瓶颈,针对性地进行架构改进和优化。
通过上述研究方向,可以更全面地验证Mamba在改进检测和分割任务方面的潜力,并进一步提升其在实际应用中的表现。
尽管Mamba架构在视觉任务中的整体表现并不突出,但作者通过去除其核心组件SSM构建的MambaOut模型在特定任务中显示出了潜力。这一发现表明,对于不同的视觉任务,可能需要考虑使用不同的架构或模型组件来优化性能。此外,对于具有长序列特性的视觉任务,如检测和分割,进一步探索Mamba的潜力可能是一个值得研究的方向。
八卦:
我个人认为这是一篇论非常好的论文,不仅论述证明了观点,而且这个观点在以往中也是经常被讨论的,其实就是我们以前的bert和gpt的遮蔽(嵌入)模型和因果模型在应用方面的区别。论文通过另外的一种方式来证明了这个而观点,给出了详细的代码,非常容易懂,并且也对比了分类,分割和检测任务的区别,有研究这个方向的可以以这篇论文的思路进行优化。
但是问题就来了,这个名字起的就让网友们开始发挥了,你要知道在全球最大的同性交友网站发这种谐音梗的后果是什么呢,那么请看这个代码的issues吧,非常好的一篇论文就被整的不那么正经了。
https://avoid.overfit.cn/post/fb3bd5f87003447bba430ca6ba2552bc

