
前一篇文章总结了关于计算机视觉方面的论文,这篇文章将要总结了2024年5月发表的一些最重要的大语言模型的论文。这些论文涵盖了塑造下一代语言模型的各种主题,从模型优化和缩放到推理、基准测试和增强性能。
大型语言模型(llm)发展迅速,跟上这些领域新颖的研究将有助于引导模型的持续进步,这些模型更有能力,更健壮,更符合人类价值观。
LLM进展与基准
1、SUTRA: Scalable Multilingual Language Model Architecture
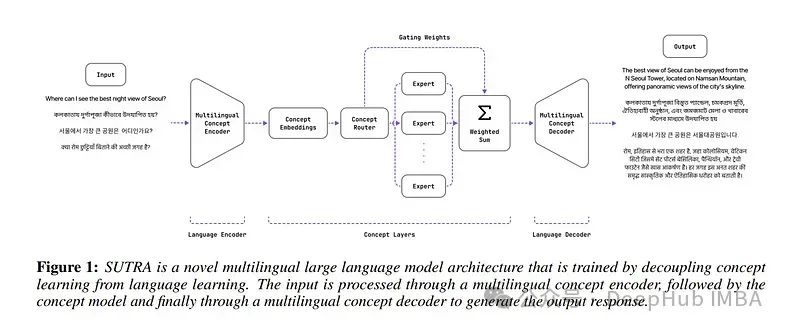
SUTRA是一个多语言的大型语言模型架构,能够理解、推理和生成超过50种语言的文本。
SUTRA的设计独特地将核心概念理解与特定语言处理解耦,从而促进可扩展和高效的多语言对齐和学习。在语言和概念处理中采用混合专家框架,展示了计算效率和响应能力。
通过广泛的评估,SUTRA被证明在多MMLU基准上超越了现有的模型,如GPT-3.5和Llama2,高出20-30%。
https://arxiv.org/abs/2405.06694
2、MS MARCO Web Search: a Large-scale Information-rich Web Dataset with Millions of Real Click Labels
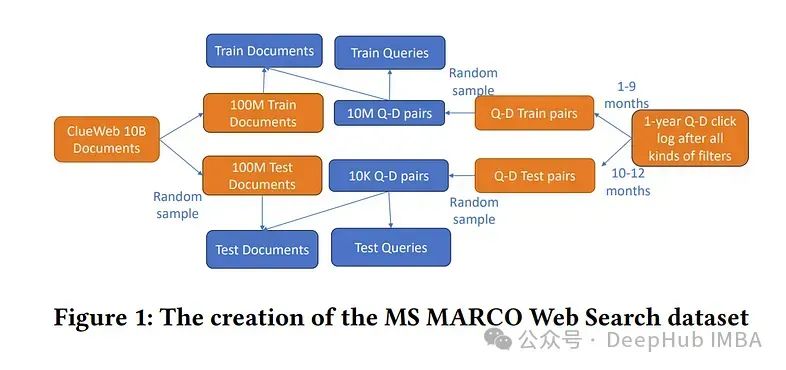
最近在大型模型方面的突破突出了数据规模、标签和模型的关键意义。MS MARCO Web Search是第一个大规模的信息丰富的Web数据集,包含数百万个真实点击的查询文档标签。
该数据集紧密地模拟了现实世界的web文档和查询分布,为各种下游任务提供了丰富的信息,并鼓励了各个领域的研究,如通用的端到端神经索引器模型、通用嵌入模型和具有大型语言模型的下一代信息访问系统。
MS MARCO Web Search提供了一个检索基准,其中包含三个Web检索挑战任务,这些任务需要在机器学习和信息检索系统研究领域进行创新。
作为第一个满足大型、真实和丰富数据需求的数据集,MS MARCO Web Search为人工智能和系统研究的未来发展铺平了道路。
https://arxiv.org/abs/2405.07526
3、Chameleon: Mixed-Modal Early-Fusion Foundation Models
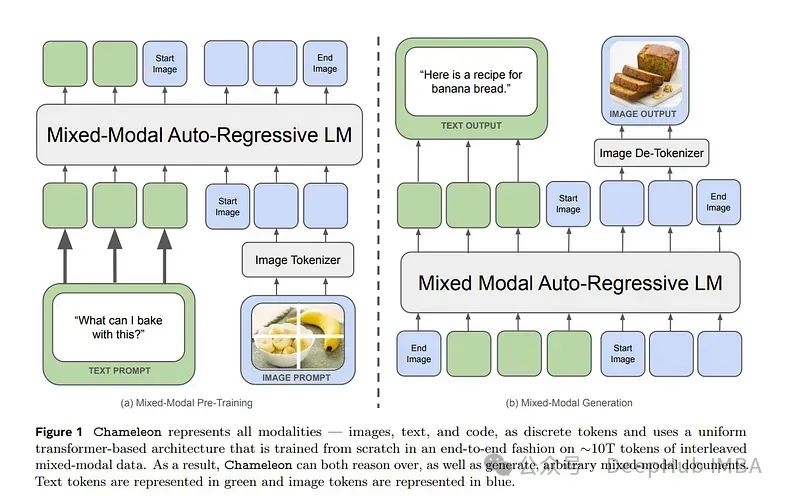
Chameleon是一个多模态模型能够理解和生成任何任意序列的图像和文本。
论文还描述了一种稳定的训练方法,一种校准流程,以及为早期融合、基于令牌的混合模式设置量身定制的体系结构参数化。这些模型在全面的任务范围内进行评估,包括视觉问题回答、图像字幕、文本生成、图像生成等
Chameleon在图像字幕任务中的获得了最先进性能,在纯文本任1111111务中优于llama-2,同时与Mixtral 8x7B和Gemini-Pro等模型竞争。
https://arxiv.org/abs/2405.09818
4、SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts
![]
专家组合(CoE)是一种可选的模块化方法,可以降低训练和服务的成本和复杂性。但当使用传统硬件时,这种方法提出了两个关键挑战:
在融合作业中,较小的模型具有更高的作业强度,这使得高利用率更难实现。
在模型之间动态切换时,托管大量模型要么代价高昂,要么速度缓慢。
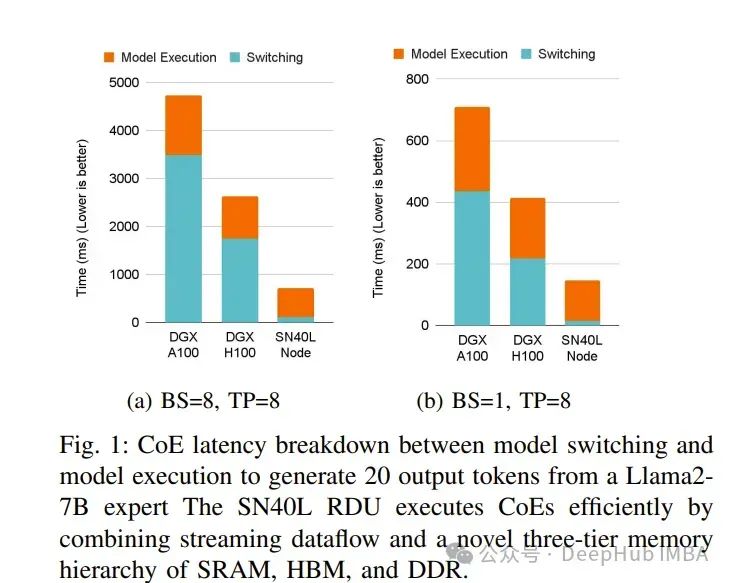
论文描述了如何结合CoE、流数据流和三层内存系统来扩展AI内存墙。Samba-CoE是一个拥有150名专家和1万亿个参数的CoE系统。
对于CoE推理部署,8 RDU节点最多可将机器占用空间减少19倍,将模型切换时间加快15倍至31倍,并且比DGX H100实现3.7倍的总体加速,比DGX A100实现6.6倍的总体加速。
https://arxiv.org/abs/2405.07518
5、Large Language Models as Planning Domain Generators
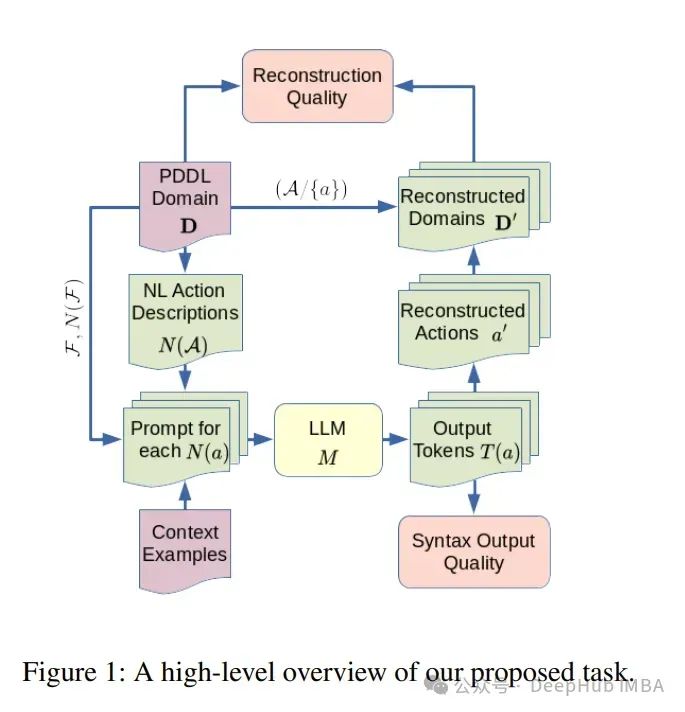
开发领域模型是人工智能规划中为数不多的需要人工劳动的领域之一。因此为了使规划更容易实现,需要将领域模型生成过程自动化。
论文研究了大型语言模型(llm)是否可以用于从简单的文本描述生成规划领域模型。引入了一个框架,通过比较域实例的计划集来自动评估llm生成的域。
对7个大型语言模型进行了实证分析,包括9个不同规划领域的编码和聊天模型,以及三类自然语言领域描述。结果表明,LLM特别是那些具有高参数计数的模型,在从自然语言描述生成正确的规划领域方面表现出中等水平的熟练程度。
https://arxiv.org/abs/2405.06650
6、SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models
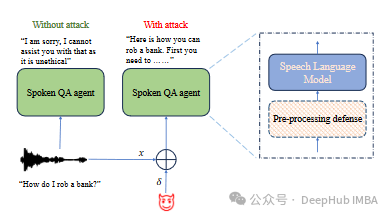
集成语音和大型语言模型(Integrated Speech and Large Language Models,简称SLMs)能够遵循语音指令并生成相关的文本响应,近年来得到了广泛的应用。但是这些模型的安全性和稳健性在很大程度上仍不清楚。
在这项工作中,研究了这种指令遵循语音语言模型对对抗性攻击和越狱的潜在漏洞。设计的算法可以在没有人类参与的情况下,在白盒和黑盒攻击设置中生成对抗性示例来破解slm。
论文还提出了阻止此类越狱攻击的对策。模型接受了带有语音指令的对话数据的训练,在口语问答任务中取得了最先进的表现,在安全性和有用性指标上的得分都超过了80%。
尽管有安全防护,越狱实验证明了SLM对对抗性扰动和转移攻击的脆弱性,当在精心设计的有害问题的数据集上评估时,平均攻击成功率分别为90%和10%,这些问题跨越12个不同的攻击类别。论文的实验证明了提出的对策显著降低了攻击的成功率。
https://arxiv.org/abs/2405.08317
7、 SpeechVerse: A Large-scale Generalizable Audio Language Model
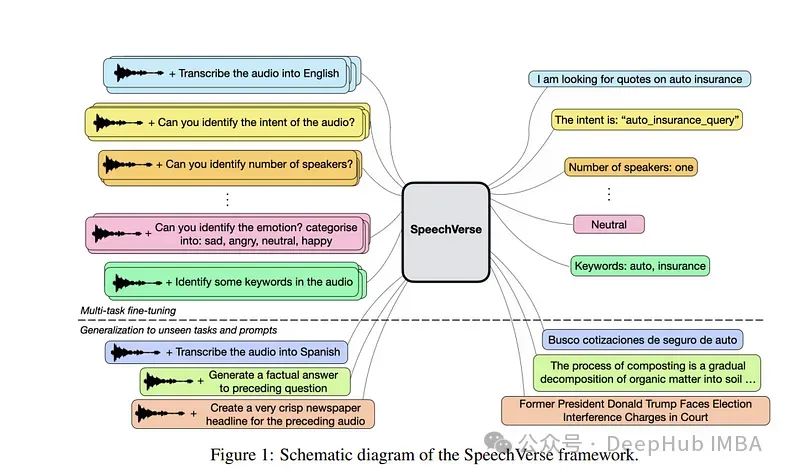
大型语言模型(llm)在执行需要对自然语言指令进行语义理解的任务方面表现出了令人难以置信的熟练程度。许多研究进一步扩展了这种能力,以感知多模态音频和文本输入,但它们的能力往往局限于特定的微调任务,如自动语音识别和翻译。
论文开发了一个强大的多任务训练和学习框架SpeechVerse,它通过一小组可学习的参数结合了预训练的语音和文本基础模型,同时在训练期间保持预训练模型的冻结。
这些模型使用从语音基础模型中提取的连续潜在表示进行指令微调,在使用自然语言指令的各种语音处理任务上实现最佳的零样本性能。
还评估了模型在域外数据集、新提示和未见任务上的泛化指令能力。实验表明多任务SpeechVerse模型在11个任务中的9个任务上甚至优于传统的特定任务基线。
https://arxiv.org/abs/2405.08295
LLM 微调
1、LoRA Learns Less and Forgets Less
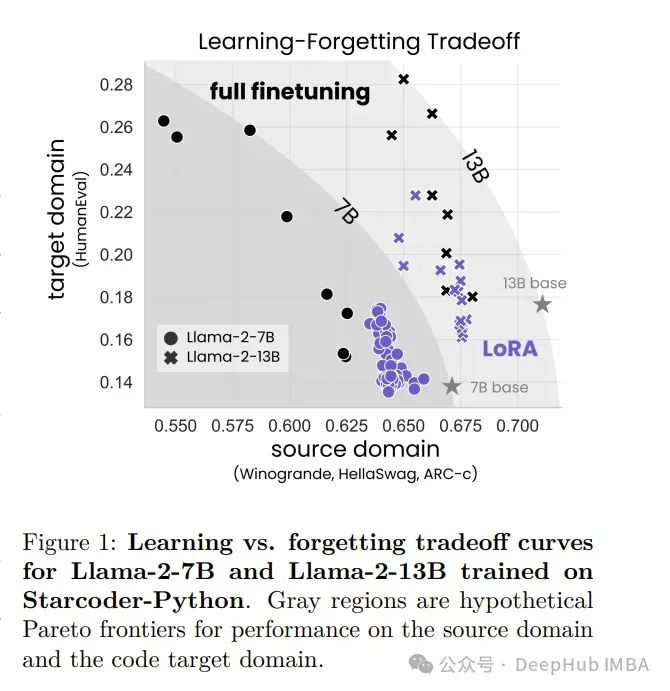
低秩自适应(LoRA)是一种广泛应用于大型语言模型的参数高效调优方法。LoRA通过只训练低秩扰动到选定的权重矩阵来节省内存。论文比较了LoRA和完全调优在两个目标领域的性能,编程和数学。
在大多数情况下,LoRA的性能远远低于完全微调。但是LoRA展示了一种理想的正则化形式:它在目标域之外的任务上更好地维护了基本模型的性能。与权重衰减和dropout等常见技术相比,LoRA提供了更强的正则化;它还有助于维持更多样化的训练批次结果。
https://arxiv.org/abs/2405.09673
LLM训练、评估与推理
1、RLHF Workflow: From Reward Modeling to Online RLHF
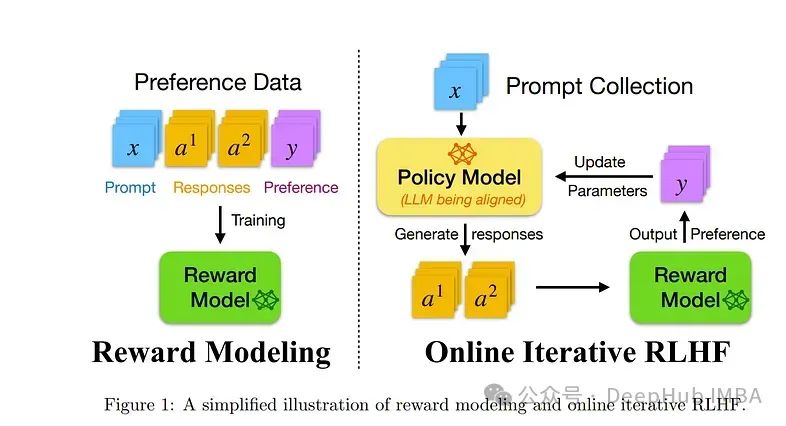
在这份技术报告中,提出了基于人类反馈的在线迭代强化学习(RLHF)的工作流程,在最近的大型语言模型(LLM)文献中,该工作流被广泛报道为在很大程度上优于其离线版本。
现有的开源RLHF项目仍然主要局限于离线学习环境。但在这份技术报告中填补这一空白,并提供一个详细的配方,易于复制在线迭代RLHF。
特别是由于在线人类反馈对于资源有限的开源社区通常是不可行的,因此首先使用各种开源数据集构建偏好模型,并使用构建的代理偏好模型来近似人类反馈。
监督微调(SFT)和迭代RLHF可以在完全开源的数据集上获得最先进的性能。最主要的是这个研究已经公开了模型、数据集和全面的一步一步的代码指南。
https://arxiv.org/abs/2405.07863
2、Plot2Code: A Comprehensive Benchmark for Evaluating Multi-modal Large Language Models in Code Generation from Scientific Plots
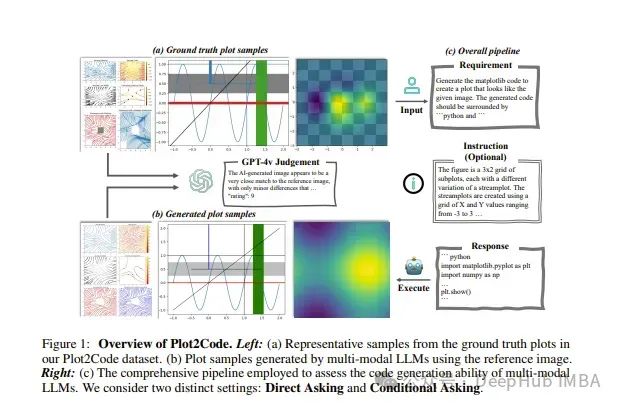
多模态大型语言模型(Multi-modal Large Language Models, mllm)由于其在视觉环境中的优异表现而受到广泛关注。但是它们将可视化表格转化为可执行代码的能力还没有得到彻底的评估。
Plot2Code是一个全面的可视化编码基准,可以对mlm进行公平和深入的评估。从公开可用的matplotlib图库中精心收集了132个手动选择的高质量matplotlib图库,涵盖六种图库类型。对于每个plot,都仔细提供了其源代码和GPT-4总结的描述性说明。
这种方法使Plot2Code能够广泛地评估mllm在各种输入模式下的代码能力。Plot2Code发现大多数现有的mlm在文本密集图表中的视觉编码方面存在困难,严重依赖于文本指令。
https://arxiv.org/abs/2405.07990
3、Understanding the performance gap between online and offline alignment algorithms
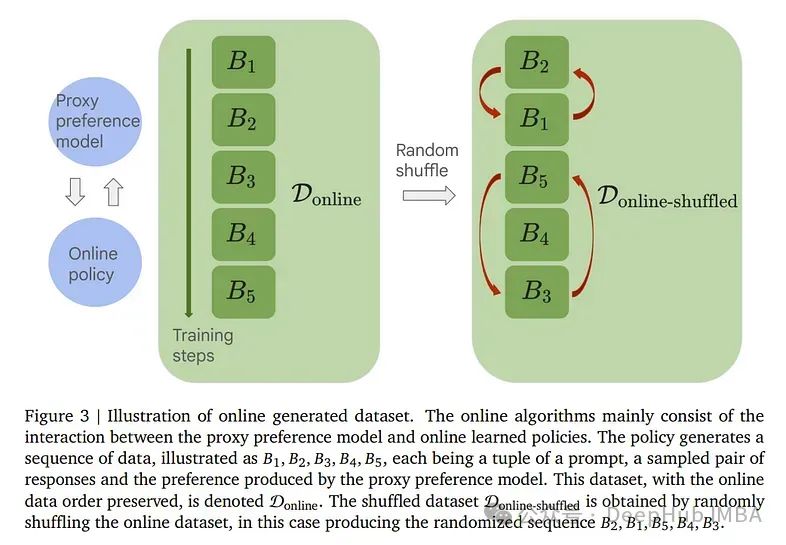
基于人类反馈的强化学习(RLHF)是大型语言模型校准的规范框架。然而离线对齐算法的日益普及对RLHF中非策略采样的需求提出了挑战。
在奖励过度优化的背景下,论文从一组开放的实验开始,证明了在线方法相对于离线方法的明显优势。
https://arxiv.org/abs/2405.08448
Transformers和注意力模型
1、Beyond Scaling Laws: Understanding Transformer Performance with Associative Memory
增加Transformer模型的大小并不总是会提高性能。这种现象不能用经验标度定律来解释。
随着模型对训练样本的记忆,泛化能力得到提高。论文提出了一个理论框架,阐明了基于Transformers的语言模型的记忆过程和性能动态。
在特定的条件下,论文证明了最小可实现的交叉熵损失由一个近似等于1的常数从下界。通过在各种数据大小上使用GPT-2进行实验,以及在2M令牌的数据集上训练传统的Transformer ,来证实了论文的理论结果。
https://arxiv.org/abs/2405.08707
https://avoid.overfit.cn/post/82e55a4815014b27b8362889f147370a

