
本文总结了2024年5月第四周发表的一些最重要的LLM论文。这些论文的主题包括模型优化和缩放到推理、基准测试和增强性能。
LLM发展与基准
1、Towards Modular LLMs by Building and Reusing a Library of LoRAs
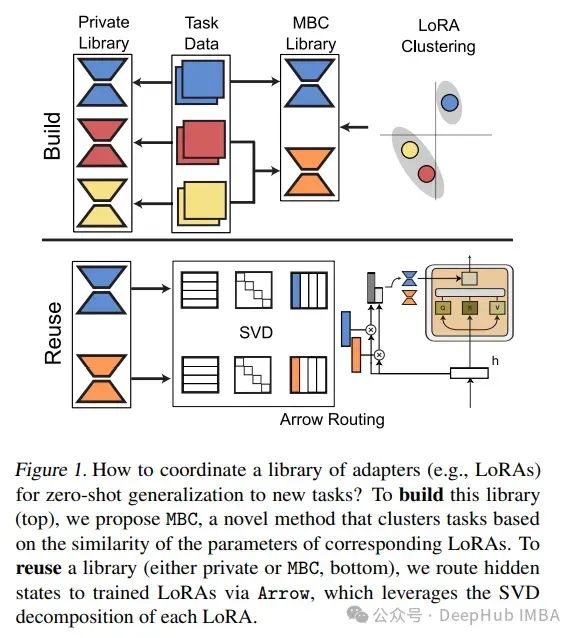
基本大型语言模型(LLM)的参数越来越对,这就要求我们研究出更高效的微调适配器来提高新任务的性能。
论文研究了如何在给定多任务数据的情况下最好地构建适配器库,并设计了在该库中通过路由实现零样本和监督任务泛化的技术。
对构建该库的现有方法进行了基准测试,引入了基于模型的聚类方法MBC,这是一种基于适配器参数的相似性对任务进行分组的方法,间接优化了跨多任务数据集的传输。
最后还提出了一种新的零样本路由机制Arrow,它可以动态选择最相关的适配器,而无需重新训练。
对几个llm(如Phi-2和Mistral)进行了实验,在各种各样的任务上进行了测试,验证了基于mb的适配器和Arrow路由能够更好地泛化到新任务。
https://arxiv.org/abs/2405.11157
2、Grounded 3D-LLM with Referent Tokens

先前对3D场景理解的研究主要是针对特定任务开发专门的模型,或者需要针对特定任务进行微调。这篇论文提出了Grounded 3D-LLM,它探索了大型3D多模态模型(3D lmm)在统一生成框架内整合各种3D视觉任务的潜力。
该模型使用场景参考标记作为特殊的名词短语来引用3D场景,从而能够处理3D和文本数据交织的序列。也就是说提供了一种使用任务特定指令模板将3D视觉任务翻译成文本格式的自然方法。
为了便于在随后的语言建模中使用参考标记,还构建了大规模的基础语言数据集,通过引导现有对象标签在短语级别提供更精细的场景-文本对应。
然后引入了对比语言-场景预训练(CLASP)来有效地利用这些数据,从而将3D视觉与语言模型相结合。
论文综合评估涵盖了开放式任务,如密集字幕和3D QA,以及封闭式任务,如对象检测和语言基础。跨多个3D基准测试的实验揭示了接地3D- llm的领先性能和广泛适用性。
https://arxiv.org/abs/2405.10370
3、Not All Language Model Features Are Linear

最近的研究提出了线性表征假设:语言模型通过操纵激活空间中的一维概念表征(“特征”)来进行计算。
相比之下,这篇论文则探索一些语言模型表征可能本质上是多维的。首先制定了不可约多维特征的严格定义,这些特征是否能被分解成独立的或不共现的低维特征。
受这些定义的启发,设计了一种可扩展的方法,使用稀疏自编码器在GPT-2和Mistral 7B中自动寻找多维特征。这些自动发现的特征包括一些极具解释性的例子,例如代表一周中的日子和一年中的月份的圆形特征。
确定了使用这些确切的圆形来解决涉及一周中的日子和一年中的月份的模块算术计算问题的任务。
最后通过在Mistral 7B和Llama 3 8B上进行干预实验,提供证据表明这些圆形特征确实是这些任务中的计算基本单元,并通过将这些任务的隐藏状态分解成可解释的组件,找到了更多的圆形表征。
https://arxiv.org/abs/2405.14860
4、INDUS: Effective and Efficient Language Models for Scientific Applications

大型语言模型(LLMs)在一般领域的语料库上训练已在自然语言处理(NLP)任务上显示出卓越的成果。然而,以往的研究表明,使用领域专注的语料库训练的LLMs在专业任务上表现更佳。
受到这一关键见解的启发,论文开发了INDUS,这是一套专为地球科学、生物学、物理学、日球层物理学、行星科学和天体物理学领域量身定制的LLMs,使用从多样化数据来源精选的科学语料库进行训练。这套模型包括:
- 使用领域特定词汇和语料库训练的编码器模型,用于解决自然语言理解任务。
- 使用从多个来源提取的多样化数据集训练的基于对比学习的通用文本嵌入模型,用于解决信息检索任务。
- 使用知识蒸馏技术创建的这些模型的小型版本,用于解决存在延迟或资源限制的应用。
论文还创建了三个新的科学基准数据集,分别是CLIMATE-CHANGE-NER(实体识别)、NASA-QA(抽取式QA)和NASA-IR(信息检索),以加速这些多学科领域的研究。
最后展示了模型在这些新任务以及感兴趣领域的现有基准任务上,均优于通用编码器(如RoBERTa)和现有的领域特定编码器(如SciBERT)。
https://arxiv.org/abs/2405.10725
5、 Imp: Highly Capable Large Multimodal Models for Mobile Devices

通过利用大型语言模型(LLMs)的能力,最近的大型多模态模型(LMMs)在开放世界的多模态理解方面显示出了显著的多功能性。
但是它们通常参数量大且计算密集,因此限制了在资源受限场景下的应用性。为此连续提出了几种轻量级的LMMs,以在受限规模下(例如,3B)最大化能力。
尽管这些方法取得了不错的结果,但它们大多只关注设计空间的一两个方面,且影响模型能力的关键设计选择尚未得到彻底研究。这篇论文从模型架构、训练策略和训练数据的角度对轻量级LMMs进行了系统研究。
基于论文的发现,开发了Imp——一个在2B-4B规模上高度能力的LMMs模型。Imp-3B模型稳定地超过了所有相似大小的现有轻量级LMMs,甚至超过了13B规模的最新技术水平的LMMs。
通过低位量化和分辨率降低技术,Imp模型可以在高达约13 tokens/s的推理速度下部署在高通骁龙8Gen3移动芯片上。
https://arxiv.org/abs/2405.12107
6、DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data

Lean 彻底改变了数学证明验证的方式,确保了高精度和可靠性。尽管大型语言模型(LLMs)在数学推理方面表现出前景,但它们在形式定理证明的进步受到训练数据不足的阻碍。
为了解决这个问题,论文引入了一种生成大量 Lean 4 证明数据的方法,这些数据源自高中和本科级数学竞赛题目。这种方法包括将自然语言问题转换为正式声明,过滤掉质量低的声明,并生成证明来创建合成数据。
在这个包含800万个正式声明及其证明的合成数据集上对 DeepSeekMath 7B 模型进行微调后,模型在 Lean 4 miniF2F 测试中实现了46.3%的整个证明生成准确率(64个样本),超过了基准的 GPT-4(23.0%准确率,64个样本)和一种树搜索强化学习方法(41.0%)。
此外模型在 Lean 4 国际数学奥林匹克(FIMO)的标准化基准测试中成功证明了148个问题中的5个,而 GPT-4 未能证明任何问题。
这些结果表明,利用大规模合成数据提升 LLMs 的定理证明能力具有潜力。论文后续将提供合成数据集和模型,以便进一步研究这一有前景的领域。
https://arxiv.org/abs/2405.14333
7、Dynamic data sampler for cross-language transfer learning in large language models

大型语言模型(LLMs)因其在自然语言处理(NLP)领域的广泛应用而受到显著关注。为非英语语言训练LLMs面临重大挑战,这主要是因为获取大规模语料库和所需计算资源的难度。
论文提出了一种基于跨语言迁移的LLM——ChatFlow应对这些挑战,并以成本效益的方式训练大型中文语言模型。使用中文、英文和平行语料的混合,持续训练LLaMA2模型,旨在对齐跨语言表征并特别促进对中文语言模型的知识迁移。
使用动态数据采样器,使模型从无监督预训练逐渐过渡到有监督微调。实验结果表明,这个方法加速了模型收敛,并实现了优越的性能。在流行的中英文基准测试上评估ChatFlow,结果表明它超越了其他在LLaMA-2–7B上后训练的中文模型。
https://arxiv.org/abs/2405.10626
8、Dense Connector for MLLMs

多模态大型语言模型(MLLMs)是否充分利用了视觉编码器的潜力?近期MLLMs在多模态理解方面的卓越表现已经引起了学术界和工业界的广泛关注。
在当前的MLLM竞赛中,焦点似乎主要集中在语言方面。包括更大、更高质量的指令数据集的出现,以及更大规模LLMs的参与。但是对MLLMs使用的视觉信号的关注却很少,通常假定这些视觉信号是由一个固定的视觉编码器提取的最终高级特征。
论文介绍了密集连接器(Dense Connector)——一个简单、有效且即插即用的视觉语言连接器,通过利用多层视觉特征显著增强现有的MLLMs,且额外计算开销极小。
论文的模型仅在图像上训练,也展示了在视频理解方面的卓越零样本能力。通过不同的视觉编码器、图像分辨率、训练数据集规模、不同大小的LLMs(从2.7B到70B),以及多样化的MLLMs架构(例如LLaVA和Mini-Gemini)的实验结果,验证了方法的多功能性和可扩展性,在19个图像和视频基准测试中实现了最佳性能。
https://arxiv.org/abs/2405.13800
LLM训练、评估与推理
1、MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning

低秩适应是一种流行的、用于大型语言模型的高效微调方法。论文分析了在LoRA中实现的低秩更新的影响。
发现表明,低秩更新机制可能限制了LLMs有效学习和记忆新知识的能力。受此启发提出了一种名为MoRA的新方法,该方法采用正方形矩阵实现高秩更新,同时保持可训练参数的数量不变。
为实现这一点,引入了相应的非参数操作符来减小输入维度并增加正方形矩阵的输出维度。这些操作符确保了权重可以合并回LLMs,这意味着这个方法可以像LoRA一样部署。
论文对提出的方法进行了全面评估,涵盖五个任务:指令调整、数学推理、持续预训练、记忆和预训练。方法在记忆密集型任务上表现优于LoRA,并在其他任务上实现了可比的性能。
https://arxiv.org/abs/2405.12130
2、OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework

随着大型语言模型(LLMs)通过规模法则持续增长,基于人类反馈的强化学习(RLHF)因其卓越的表现而受到重视。
与预训练或微调单一模型不同,为大型语言模型训练的基于人类反馈的强化学习(RLHF)面临在四个模型间协调的挑战。
论文提出了一个开源框架OpenRLHF,使RLHF的高效扩展成为可能。与现有的RLHF框架将四个模型部署在相同的GPU上不同,OpenRLHF重新设计了超过70B参数模型的调度,使用Ray、vLLM和DeepSpeed实现了改进的资源利用和多样化的训练方法。
OpenRLHF与Hugging Face无缝集成,提供了一个开箱即用的解决方案,包括优化的算法和启动脚本,确保用户友好性。OpenRLHF实现了RLHF、DPO、拒绝采样和其他对齐技术。
https://arxiv.org/abs/2405.11143
3、Layer-Condensed KV Cache for Efficient Inference of Large Language Models

巨大的内存消耗一直是在实际应用中部署高吞吐量大型语言模型的主要瓶颈。除了大量参数外,Transformer架构中用于注意力机制的键值(KV)缓存也消耗了大量内存,尤其是当深度语言模型的层数较多时。
论文提出了一种新方法,该方法只计算并缓存少数几层的KV,从而显著节省内存消耗并提高推理吞吐量。
在大型语言模型上的实验表明,与标准Transformer相比,方法在语言建模和下游任务中实现了高达26倍的吞吐量提升,并保持了竞争性的表现。
此外这个方法与现有的Transformer节省内存技术是正交的,因此将它们与论文的模型集成非常简单,还可以进一步提高推理效率。
https://arxiv.org/abs/2405.10637
4、Observational Scaling Laws and the Predictability of Language Model Performance

理解语言模型性能如何随规模变化对于基准测试和算法开发至关重要。尽管建立这种理解的一种方法是使用规模法则,但在许多不同规模上训练模型的要求限制了它们的使用。
论文提出了一种替代的观察性方法,该方法绕过模型训练,而是从大约80个公开可用的模型中建立规模法则。从多个模型家族构建单一的规模法则是具有挑战性,因为它们在训练计算效率和能力上存在很大的变化。
但是论文展示了这些变化与一个简单的、通用的规模法则一致,其中语言模型性能是一个低维能力空间的函数,模型家族只在将训练计算转换为能力的效率上有所不同。
这种方法展示了复杂规模现象的惊人可预测性:几种出现的现象遵循平滑的S型行为,并且可以从小模型预测;如GPT-4这样的模型的代理性能可以从更简单的非代理性基准精确预测;如何预测像思维链和自我一致性这样的训练后干预措施的影响,随着语言模型能力的持续提高。
https://arxiv.org/abs/2405.10938
LLM量化与校准
1、AlignGPT: Multi-modal Large Language Models with Adaptive Alignment Capability

多模态大型语言模型(MLLMs)广泛被认为是探索人工通用智能(AGI)的关键。MLLMs的核心在于它们实现跨模态对齐的能力。
当前的MLLMs通常遵循两阶段训练范式:预训练阶段和指令调整阶段。尽管它们取得了成功,但在这些模型中对齐能力的建模存在缺陷。
首先,在预训练阶段模型通常假设所有的图文对都是均匀对齐的,但实际上不同图文对之间的对齐程度是不一致的。
其次,当前用于微调的指令涵盖多种任务,不同任务的指令通常需要不同程度的对齐能力,但以往的MLLMs忽视了这些差异化的对齐需求。
为解决这些问题,论文提出了一种新的多模态大型语言模型AlignGPT。在预训练阶段,不再将所有图文对等同对待,而是为不同的图文对分配不同级别的对齐能力。
然后在指令调整阶段,适应性地结合这些不同级别的对齐能力,以满足不同指令的动态对齐需求。广泛的实验结果显示模型在12个基准测试上达到了竞争性的表现
https://arxiv.org/abs/2405.14129
2、Distributed Speculative Inference of Large Language Models

加速大型语言模型(LLMs)的推理是人工智能中的一个重要挑战。论文介绍了一种新的分布式推理算法——分布式投机推理(DSI),该算法被证明比投机推理(SI)和传统的自回归推理(非SI)更快。
与其他SI算法一样,DSI适用于冻结的LLMs,无需训练或架构修改,并且保留了目标分布。先前关于SI的研究已经展示了与非SI相比的经验性加速,但需要一个快速且准确的起草者LLM。
论文发现了一个差距:当使用较慢或较不准确的起草者时,SI的速度会比非SI慢。
通过证明DSI比SI和非SI都快,无论使用何种起草者都可以弥补了这一差距。通过协调目标和起草者的多个实例,DSI不仅比SI更快,而且还支持无法通过SI加速的LLMs。模拟显示,在现实设置中使用现成的LLMs的加速情况:DSI比SI快1.29–1.92倍。
https://arxiv.org/abs/2405.14105
Transformer和注意力模型
1、Reducing Transformer Key-Value Cache Size with Cross-Layer Attention

键值(KV)缓存在加速基于Transformer的自回归大型语言模型(LLMs)的解码过程中扮演着至关重要的角色。然而长序列长度和大批量大小所需存储KV缓存的内存量可能变得过大。
自Transformer发明以来,减小KV缓存大小的两种最有效的干预措施是多查询注意力(Multi-Query Attention,MQA)及其泛化形式,分组查询注意力(Grouped-Query Attention,GQA)。
MQA和GQA都修改了注意力模块的设计,使得多个查询头可以共享一个键/值头,大幅减少了不同键/值头的数量,同时只对准确度造成最小的影响。
论文展示了可以进一步发展多查询注意力,通过在相邻层之间共享键和值头,提出了一种新的注意力设计,称之为跨层注意力(Cross-Layer Attention,CLA)。通过CLA可以再将KV缓存的大小减少2倍,同时几乎保持与未修改的MQA相同的准确度。
在从头开始训练的1B和3B参数模型的实验中,证明了CLA在内存/准确度权衡方面提供了帕累托改进,相较于传统的MQA,能够实现更长序列长度和更大批量大小的推理,这在其他情况下是不可能的。
https://arxiv.org/abs/2405.12981
2、Your Transformer is Secretly Linear

本文揭示了包括GPT、LLaMA、OPT、BLOOM等在内的Transformer解码器独有的一种新颖线性特性。分析了序列层之间的嵌入变换,发现存在几乎完美的线性关系(普罗克鲁斯特相似性得分为0.99)。
但是当移除残差组件时,由于Transformer层的输出范数一致较低,线性会减少。实验显示移除或线性近似Transformer中一些最线性的块不会显著影响损失或模型性能。
此外在对较小模型进行的预训练实验中,引入了基于余弦相似度的正则化,旨在减少层的线性。这种正则化改善了在像Tiny Stories和SuperGLUE等基准测试上的性能指标,并成功降低了模型的线性。
这项研究挑战了对Transformer架构的现有理解,表明它们的操作可能比之前假设的更为线性。
https://arxiv.org/abs/2405.12250
3、SLAB: Efficient Transformers with Simplified Linear Attention and Progressive Re-parameterized Batch Normalization

Transformer已成为自然语言和计算机视觉任务的基础架构。然而高计算成本使其难以部署在资源受限的设备上。
论文研究了高效Transformer的计算瓶颈模块,即归一化层和注意力模块。LayerNorm通常用于Transformer架构,但由于在推理过程中需要进行统计计算,因此并不计算友好。然而在Transformer中用更高效的BatchNorm替换LayerNorm往往会导致性能下降和训练崩溃。
为解决这个问题论文提出了一种名为PRepBN的新方法,该方法在训练中逐步用重新参数化的BatchNorm替换LayerNorm。还提出了一种名为简化线性注意力(SLA)模块,它简单而有效,能够实现强大的性能。在图像分类和对象检测上进行了广泛的实验,以证明提出的方法的有效性。
例如,SLAB-Swin在ImageNet-1K上获得了83.6%的top-1准确率,延迟为16.2毫秒,比Flatten-Swin低2.4毫秒,准确率高出0.1%。还评估了方法在语言建模任务上的表现,并获得了可比的性能和更低的延迟。
https://arxiv.org/abs/2405.11582
https://avoid.overfit.cn/post/83d546d6c5a4449795455a5f5111dcff

